
FlexJobs Scraper od Thunderbitu vám s pomocí AI pomůže proměnit stránky FlexJobs v čisté, strukturované datové sady. Snadno získáte nabídky práce na dálku i články s kariérním poradenstvím a díky scrapování podstránek můžete každý řádek doplnit o kompletní detaily pozice nebo plný text článku. Výsledky pak během pár minut vyexportujete do Excelu, Google Sheets, Airtable nebo Notion přes .
🤖 Co je FlexJobs Scraper
AI-Powered FlexJobs Scraper je , který umí vytáhnout data z webu a uspořádat je do tabulky, kterou si můžete stáhnout nebo synchronizovat se svými nástroji. Stačí otevřít stránku, kterou chcete zpracovat (například katalog pracovních nabídek nebo blog), kliknout na AI Suggest Columns a poté na Scrape.
Je navržen pro reálné scénáře, kdy vám nestačí jen to, co je vidět v seznamu. Díky Subpage Scraping Thunderbit projde jednotlivé detailní stránky pracovních pozic nebo článků a doplní do datasetu další pole (například celý popis, požadavky, kategorie, autora a další).
🧲 Co můžete z FlexJobs získat
FlexJobs se často používá pro hledání práce na dálku, hybridních pozic a dalších flexibilních pracovních možností, a zároveň nabízí kariérní zdroje. S Thunderbitem můžete sbírat data jak ze seznamů pracovních nabídek, tak z obsahových stránek – pro výzkum, generování leadů, náborové operace i analýzu obsahu.
🧑💻 Scrapování nabídek práce na dálku z FlexJobs
Z adresáře nabídek na si můžete vytvořit strukturovanou databázi rolí, firem a metadat. Následně každý řádek obohatíte tím, že ze subpage (detailu pozice) vytáhnete kompletní popis, požadavky a informace k přihlášení.
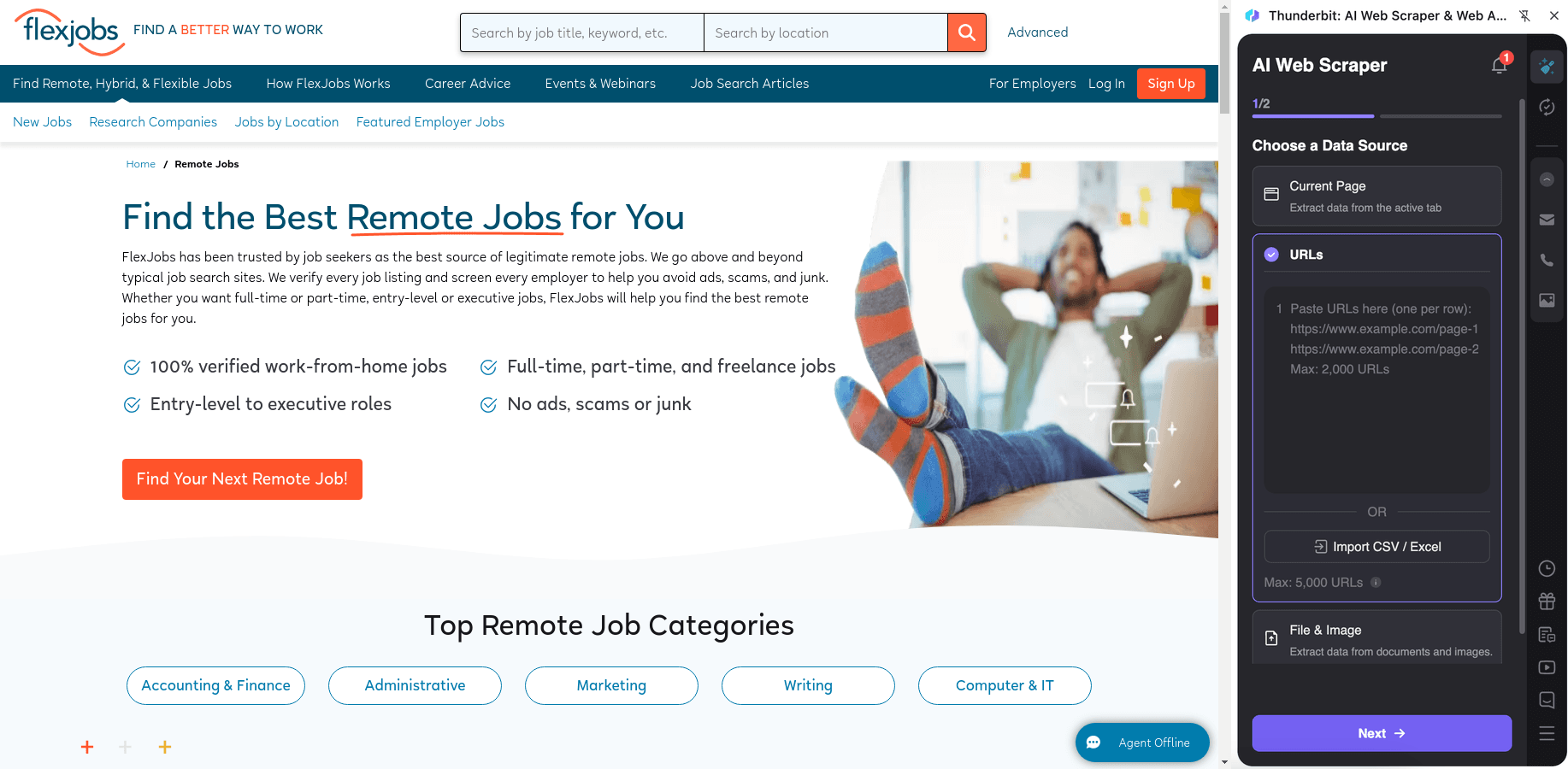
Postup:
- Nainstalujte si a zaregistrujte si účet.
- Otevřete cílovou stránku, například: .
- Klikněte na AI Suggest Columns – vygenerují se doporučené názvy sloupců a datové typy.
- Klikněte na Scrape, spusťte scrapování a poté exportujte do Excelu, Google Sheets, Airtable nebo Notion.
Názvy sloupců
| Sloupec | Popis |
|---|---|
| 🧾 Název pozice | Název pracovní nabídky zobrazený ve výsledcích. |
| 🏢 Společnost | Název zaměstnavatele / firmy, která nabírá (pokud je uveden). |
| 📍 Lokalita / typ remote | Informace o lokalitě, např. remote, pouze USA, omezení na stát, město/stát. |
| 🕒 Typ úvazku | Plný úvazek, částečný, freelance, kontrakt, dočasně apod. |
| 🧩 Kategorie / úroveň | Kategorie pozice a/nebo seniorita, pokud je uvedena. |
| 🗓️ Datum zveřejnění | Datum zveřejnění nebo poslední aktualizace (pokud je zobrazeno). |
| 🔗 URL pozice | Přímý odkaz na detail pozice pro scrapování podstránek. |
| 📝 Krátké shrnutí | Krátký úryvek/preview ze seznamu. |
| 🧠 Dovednosti / klíčová slova | Klíčové dovednosti nebo tagy uvedené u nabídky (pokud jsou). |
| 📄 Plný popis pozice (podstránka) | Kompletní popis pozice z detailní stránky. |
| ✅ Požadavky (podstránka) | Požadavky/kvalifikace vytažené z detailu pozice. |
| 📬 Jak se přihlásit (podstránka) | Instrukce k přihlášení nebo detaily odkazu na přihlášku (pokud jsou dostupné). |
📚 Scrapování článků s kariérním poradenstvím z FlexJobs
Z blogu na můžete získat metadata článků pro obsahový výzkum, SEO analýzu nebo interní znalostní bázi. Pomocí scrapování podstránek pak stáhnete i celý text článku, nadpisy a informace o autorovi.
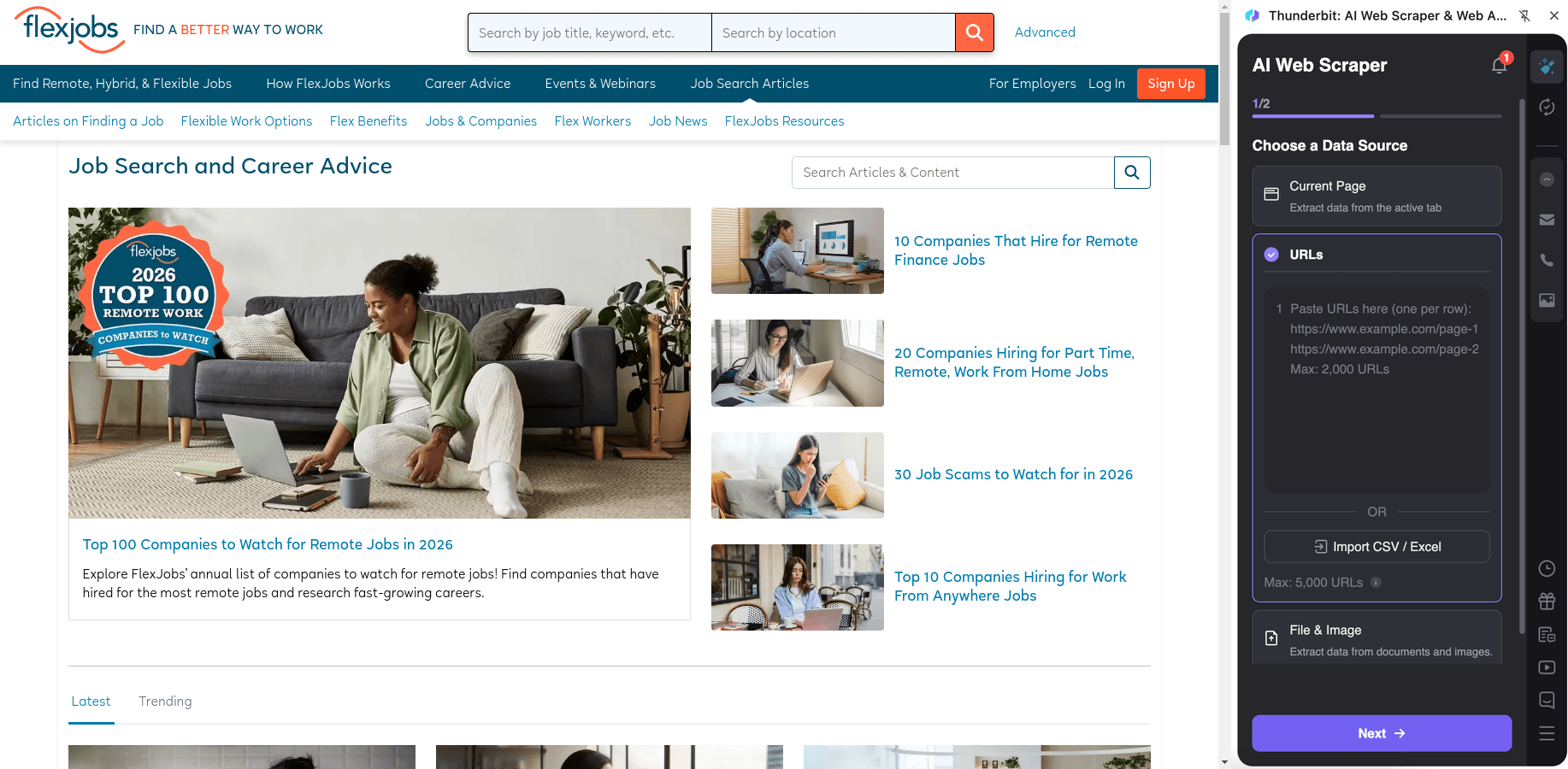
Postup:
- Nainstalujte si a zaregistrujte si účet.
- Otevřete cílovou stránku, například: .
- Klikněte na AI Suggest Columns – vygenerují se doporučené názvy sloupců a datové typy.
- Klikněte na Scrape, vytáhněte data a poté exportujte do Excelu, Google Sheets, Airtable nebo Notion.
Názvy sloupců
| Sloupec | Popis |
|---|---|
| 📰 Název článku | Titulek blogového příspěvku. |
| 🔗 URL článku | Odkaz na stránku článku pro scrapování podstránek. |
| ✍️ Autor | Jméno autora, pokud je zobrazeno. |
| 🗓️ Datum publikace | Datum vydání článku. |
| 🏷️ Kategorie / štítek | Kategorie nebo tag (ze seznamu nebo z podstránky, pokud je uveden). |
| 🧷 Perex | Krátký úryvek ze seznamu článků. |
| 🖼️ URL hlavního obrázku | Hlavní obrázek přiřazený k článku (pokud je dostupný). |
| 🧾 Plný obsah článku (podstránka) | Kompletní text vytažený ze stránky článku. |
| 🔠 Nadpisy (podstránka) | Nadpisy H2/H3 pro osnovu a analýzu. |
| ⏱️ Doba čtení (volitelné) | Odhadovaná doba čtení, pokud ji stránka uvádí. |
🎯 Proč používat FlexJobs Scraper
Scrapování FlexJobs se hodí pro různé týmy a procesy, kde je důležitá práce se strukturovanými daty.
- Nábor a talent ops: Vytvořte vyhledávatelný pipeline remote pozic podle kategorií, lokálních omezení a typu úvazku. Můžete sledovat trendy v čase a sdílet jednotný dataset s týmem.
- Obchod a partnerství: Najděte firmy, které nabírají na remote role, a obohaťte lead listy o obor, tempo náboru a typy rolí.
- Kariérní koučové a tvůrci: Sbírejte signály z trhu práce a organizujte články s radami do knihovny pro newslettery, kurzy nebo koučink.
- Marketing a SEO týmy: Analyzujte témata na blogu FlexJobs, frekvenci publikování a strukturu obsahu pro vlastní redakční plán.
- Ecommerce ops a analytici (ano, i to): Pokud provozujete job board, staffing marketplace nebo HR produkt, můžete scrapovaná data využít pro konkurenční analýzu a tvorbu taxonomie.
Thunderbit je určen pro business uživatele, kteří chtějí rychlost a spolehlivost bez údržby křehkých scraping skriptů. Když se změní rozložení stránky, AI ji znovu „přečte“ a přizpůsobí se.
🧩 Jak používat FlexJobs Chrome Extension
- Nainstalujte Thunderbit Chrome Extension: Získejte ji v a vytvořte si účet.
- Přejděte na stránku FlexJobs: Otevřete pro nabídky nebo pro články.
- Spusťte AI-Powered Scraper: Klikněte na AI Suggest Columns pro návrh polí a případně upravte názvy sloupců a datové typy (Text, Date, URL, Image atd.).
- Scrapujte a doplňte data z podstránek: Klikněte na Scrape pro seznam a poté použijte Scrape Subpages, abyste do stejné tabulky doplnili kompletní detaily pozic nebo plný obsah článků.
Užitečné zdroje, pokud se scrapováním začínáte:
- Další návody najdete na
💳 Ceník pro FlexJobs Scraper
Thunderbit používá jednoduchý kreditní systém:
- 1 kredit = 1 výstupní řádek ve výsledné tabulce (například jeden řádek s nabídkou práce nebo jeden řádek s článkem).
- Export dat je zdarma: můžete exportovat do Excelu, Google Sheets, Airtable nebo Notion, případně stáhnout CSV/JSON.
Začít můžete s tarifem Free a scrapovat 6 stránek měsíčně. Pokud spustíte bezplatnou zkušební verzi, můžete zdarma scrapovat 10 stránek – ideální pro otestování stránkování a obohacení dat z podstránek před přechodem na placený plán.
Placené tarify se přizpůsobí vašemu objemu práce:
- Starter se hodí pro menší scrapování a jednorázové projekty.
- Pro úrovně jsou vhodnější pro průběžné náborové operace, monitoring trhu práce a sledování obsahu.
- Roční plán bývá nejvýhodnější, protože obvykle obsahuje slevu oproti měsíčnímu účtování.
Možnosti najdete na stránce .
❓ FAQ
-
Co je AI Powered FlexJobs Scraper?
AI Powered FlexJobs Scraper je workflow v Thunderbitu, které převádí nabídky práce a články z FlexJobs do strukturovaných řádků a sloupců. Využívá AI k pochopení rozložení stránky, takže můžete scrapovat rychle a získat čistá pole jako název, společnost, lokalita a URL.
Výsledky lze navíc obohatit pomocí scrapování podstránek – například o kompletní popis pozice nebo celý obsah článku. -
Co je Thunderbit?
je AI web scraping Chrome Extension, která pomáhá získávat data z webů, PDF a obrázků do strukturovaných tabulek. Je stavěná pro business scénáře jako generování leadů, nábor, ecommerce operace a průzkum trhu.
Obvykle stačí kliknout na AI Suggest Columns a pak na Scrape – Thunderbit podle potřeby zvládne i stránkování a podstránky. -
Potřebuji pro scrapování FlexJobs programování?
Ne. Thunderbit je určen pro ne-technické použití, takže nepotřebujete Python, selektory ani scraping infrastrukturu.
Pokud umíte otevřít stránku a kliknout na pár tlačítek, dataset si vytvoříte. -
Umí Thunderbit získat detaily z každé stránky konkrétní pozice?
Ano. Po stažení seznamu můžete použít Subpage Scraping, které navštíví každou URL pozice a vytáhne podrobnější pole jako plný popis, požadavky a instrukce k přihlášení.
To se hodí, když seznam zobrazuje jen krátké shrnutí. -
Jak Thunderbit řeší stránkování a nekonečné scrollování na FlexJobs?
Thunderbit podporuje scrapování stránkování jak pro klasické „další stránka“, tak pro nekonečný scroll. V jednom běhu tak můžete zpracovat více stránek, což je praktické při sběru stovek nabídek.
Pokud zvolíte Cloud Scraping, Thunderbit zvládne dávky rychle (často až 50 stránek najednou, podle chování webu). -
Do jakých formátů mohu data exportovat?
Data můžete exportovat do Excelu, Google Sheets, Airtable nebo Notion, případně stáhnout jako CSV nebo JSON.
Export je zdarma, takže rozpočet řešíte hlavně podle objemu scrapování, ne podle přístupu k souborům. -
Jaký je rozdíl mezi Cloud Scraping a Browser Scraping pro FlexJobs?
Browser Scraping běží ve vašem Chrome, což je užitečné, pokud web vyžaduje přihlášení nebo personalizovaný přístup. Cloud Scraping běží na cloudové infrastruktuře Thunderbitu a u veřejných stránek bývá rychlejší.
Pokud scrapujete stránky závislé na relaci vašeho účtu, obvykle je lepší volba Browser Scraping. -
Kolik řádků mohu získat a co znamená „500 max rows“?
Hodnota „max rows“ (např. 500) je praktické doporučení pro jeden běh podle struktury stránky a nastavení. Skutečná kapacita závisí na hloubce stránkování, kreditech a na tom, zda obohacujete data z podstránek.
Protože 1 kredit = 1 výstupní řádek, náklady snadno odhadnete podle počtu pozic nebo článků, které chcete získat. -
Je v pořádku scrapovat data z FlexJobs?
Vždy dodržujte podmínky FlexJobs, respektujte soukromí a řiďte se platnými zákony a předpisy. Thunderbit je nástroj pro získání a strukturování dat, ale za správné použití nesete odpovědnost vy.
Pokud si nejste jistí, začněte malým testem a ověřte, že zamýšlené použití odpovídá vašim compliance požadavkům.
📘 Zjistěte více
- Získejte rozšíření:
- Detaily produktu:
- Ceník a tarify:
- Základy scrapování:
- Export do tabulek:
- Chytřejší scrapování s AI:
- Video návody: