
Web roste tempem, které je upřímně řečeno až těžké pojmout. Každý den vznikají miliardy nových stránek, produktů, recenzí a datových sad — a pohánějí všechno od průzkumu trhu přes trénování AI až po váš další nákup na Amazonu. Po letech v SaaS a automatizaci jsem z první ruky viděl, jak správná data dokážou rozhodnout o úspěchu, nebo neúspěchu byznysového rozhodnutí. Jenže je tu háček: sběr, aktualizace a vyhodnocování webových dat je čím dál náročnější, ne jednodušší. Tradiční web scrapers nestíhají a firmy hledají chytřejší a rychlejší způsob, jak z internetu získat použitelné poznatky. A právě tady přichází cloud crawler — nástroj, který nenápadně mění způsob, jak organizace ve velkém objevují a využívají webová data.
Co tedy cloud crawler vlastně je? V čem se liší od web scraperů, které možná už znáte? A proč na tuto technologii sází týmy od obchodu po provoz, aby si udržely náskok v datově řízeném světě? Pojďme se do toho pustit, rozmotat buzzwordy a podívat se, jak cloud crawlery (zejména řešení od Thunderbit) mění pravidla hry pro moderní firmy.
Co je cloud crawler? Další krok v objevování dat
Rozebrat to můžeme takto: cloud crawler není jen web scraper, který běží v cloudu. Je to spíš stroj na objevování dat — chytrý cloudový systém navržený tak, aby automaticky vyhledával, extrahoval a analyzoval obrovské datové sady z internetu. Zatímco klasický web scraper vytahuje informace z několika stránek (často jednu po druhé a obvykle z jednoho zařízení), cloud crawler funguje na úplně jiné úrovni. Běží v silných cloudových datacentrech, prochází tisíce nebo i miliony stránek současně a zvládá vše od textu přes obrázky až po PDF — bez ohledu na to, jak složitý nebo rozsáhlý je cílový web.
Představte si to takhle: když je web scraper jako jediný knihovník, který přepisuje pasáže z knihy, cloud crawler je tým superpočítačů, který najednou skenuje všechny knihy v knihovně, obsah označuje, třídí a průběžně analyzuje. Výsledek? Firmy dostanou bohatší, čerstvější a akčnější data — bez omezení lokálního hardwaru a bez ruční práce (, ).
Cloud crawler vs. tradiční web scraper: jaký je skutečný rozdíl?
Pokud jste někdy používali web scraper, znáte základ: nasměrovat ho na stránku, určit, co chcete, a nechat ho data stáhnout. Jenže jak web roste a komplikuje se, starý přístup začíná narážet na své limity. Takhle si vedou cloud crawlery a klasické web scrapery vedle sebe:
| Vlastnost / oblast | Tradiční web scraper | Cloud crawler |
|---|---|---|
| Nasazení | Běží na vašem lokálním zařízení nebo serveru | Běží v cloudu (vzdálená datacentra) |
| Škálování | Omezené výkonem počítače | Masivně paralelní — tisíce stránek najednou |
| Rychlost | Pomalejší, hlavně u velkých úloh | Rychlé dávkové zpracování |
| Údržba | Vyžaduje časté aktualizace, padá při změnách webu | Cloudový, automaticky se přizpůsobuje, méně křehký |
| Typy dat | Obvykle text, někdy obrázky | Text, obrázky, PDF, složitá rozložení |
| Přístup | Vázaný na vaše zařízení/síť | Dostupný odkudkoli a z jakéhokoli zařízení |
| Plánování | Ruční nebo základní automatizace | Pokročilé plánování, opakované úlohy |
| Nejlépe se hodí pro | Menší projekty, jednoduché weby | Velký objem dat, časté nebo složité potřeby |
Cloud crawlery jsou stavěné pro moderní web — tedy svět, kde jsou data všude a rychlost i škálovatelnost nejsou volitelný bonus, ale nutnost (, ).
Jak cloud crawlery dramaticky zrychlují sběr dat
A tady se to začíná opravdu zajímavé. Cloud crawlery využívají výkon cloud computingu ke zpracování tisíců webových stránek paralelně. To znamená, že můžete stáhnout celý katalog e-shopu, sledovat ceny konkurence na desítkách webů nebo agregovat nabídky nemovitostí ze všech hlavních portálů — a to za zlomek času, který by zabral klasický scraper.
Proč je to důležité? Protože v odvětvích jako ecommerce, finance nebo realitní trh rozhoduje čerstvost dat. Ceny, skladové zásoby i tržní trendy se mění klidně každou minutu. Čekat hodiny nebo dny, až lokální scraper doběhne, prostě není řešení. Cloud crawlery nejsou omezené pamětí vašeho notebooku ani kancelářskou Wi‑Fi — podle potřeby se škálují, takže zvládnou i obrovské úlohy bez stresu (, ).
Odvětví, která z této efektivity těží nejvíc, zahrnují:
- Ecommerce: sledování cen, agregace produktových katalogů, analýza recenzí
- Realitní trh: sběr nabídek, sledování tržních trendů, porovnávání nemovitostí
- Finance: analýza zpráv a sentimentu, monitoring akcií/krypta, dohled nad regulacemi
- Prodej a marketing: generování leadů, průzkum konkurence, odhalování trendů
A upřímně? To je teprve začátek. Pokud potřebujete webová data ve velkém, cloud crawler je váš nový nejlepší pomocník.
Řešení cloud crawleru od Thunderbit: rychlé, flexibilní a výkonné
Teď si na chvíli nasadím klobouk Thunderbit (dobře, vlastně ho skoro nesundávám). Cloudový scraping režim od je naše odpověď na moderní datovou výzvu — cloud crawler vytvořený pro byznys uživatele, kteří chtějí výsledky, ne starosti.
Tady je to, čím Thunderbit cloud crawler vyniká:
- Dávkové scrapování s vysokou rychlostí: Získejte až 50 stránek najednou, s cloud servery v USA, EU a Asii pro globální pokrytí. Už žádné čekání, až váš notebook se zápalem plíce přefiltrovaně projde velký seznam.
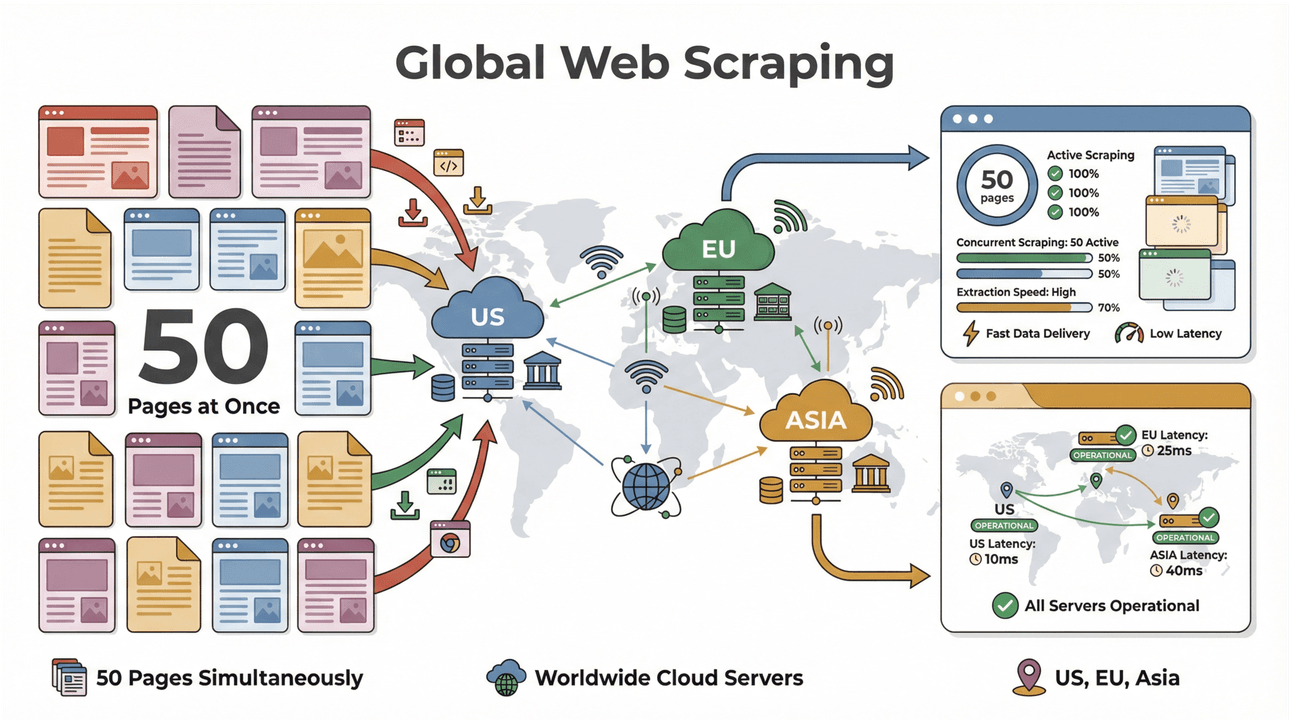
- Podpora složitých stránek: AI od Thunderbit zvládne vše od dynamických ecommerce webů až po komplikovaná PDF a dokonce i extrakci obrázků. Pokud je to na webu, Thunderbit to pravděpodobně zvládne zpracovat ().
- Procházení podstránek: Potřebujete obohatit data o detaily z podstránek, třeba technické parametry produktu nebo bio autora? AI od Thunderbit může navštívit každou podstránku a výsledky sloučit do hlavní datové sady ().
- Chytré strukturování dat: Pomocí „AI Suggest Fields“ necháte Thunderbit přečíst web a navrhnout nejlepší sloupce — bez kódování a bez stavění šablon.
- Export kamkoli: Pošlete data přímo do Excelu, Google Sheets, Airtable nebo Notion. Nebo si je stáhněte jako CSV/JSON — podle toho, co vám sedí do workflow ().
- Bez nutnosti údržby: AI od Thunderbit se přizpůsobuje změnám webu, takže nemusíte neustále opravovat rozbité scrapery ().
A ano, můžete si to celé vyzkoušet ve — nemusíte mi jen věřit na slovo.
Nasazení cloud crawleru: cloud vs. lokálně — co je pro vás správně?
Jednou z největších výhod cloud crawlerů je flexibilita nasazení. U tradičního lokálního crawleru jste svázáni s konkrétním zařízením, sítí a často i s množstvím nastavení, které bolí už při pomyšlení. Když počítač usne nebo vypadne internet, scraping se zastaví. A pokud chcete škálovat, musíte kupovat další hardware nebo spouštět víc skriptů.
Cloud crawlery to obracejí naruby:
- Není potřeba speciální hardware: Veškerá těžká práce probíhá v cloudu. Velké scrapingové úlohy můžete spustit z Chromeboouku, Macu nebo klidně i z telefonu.
- Přístup odkudkoli: Na cestách? Pracujete na dálku? Žádný problém — cloud crawler je vám vždy k dispozici.
- Snadné škálování: Potřebujete zpracovat 10 000 stránek místo 100? Jednoduše navýšíte velikost úlohy — bez zásahu IT.
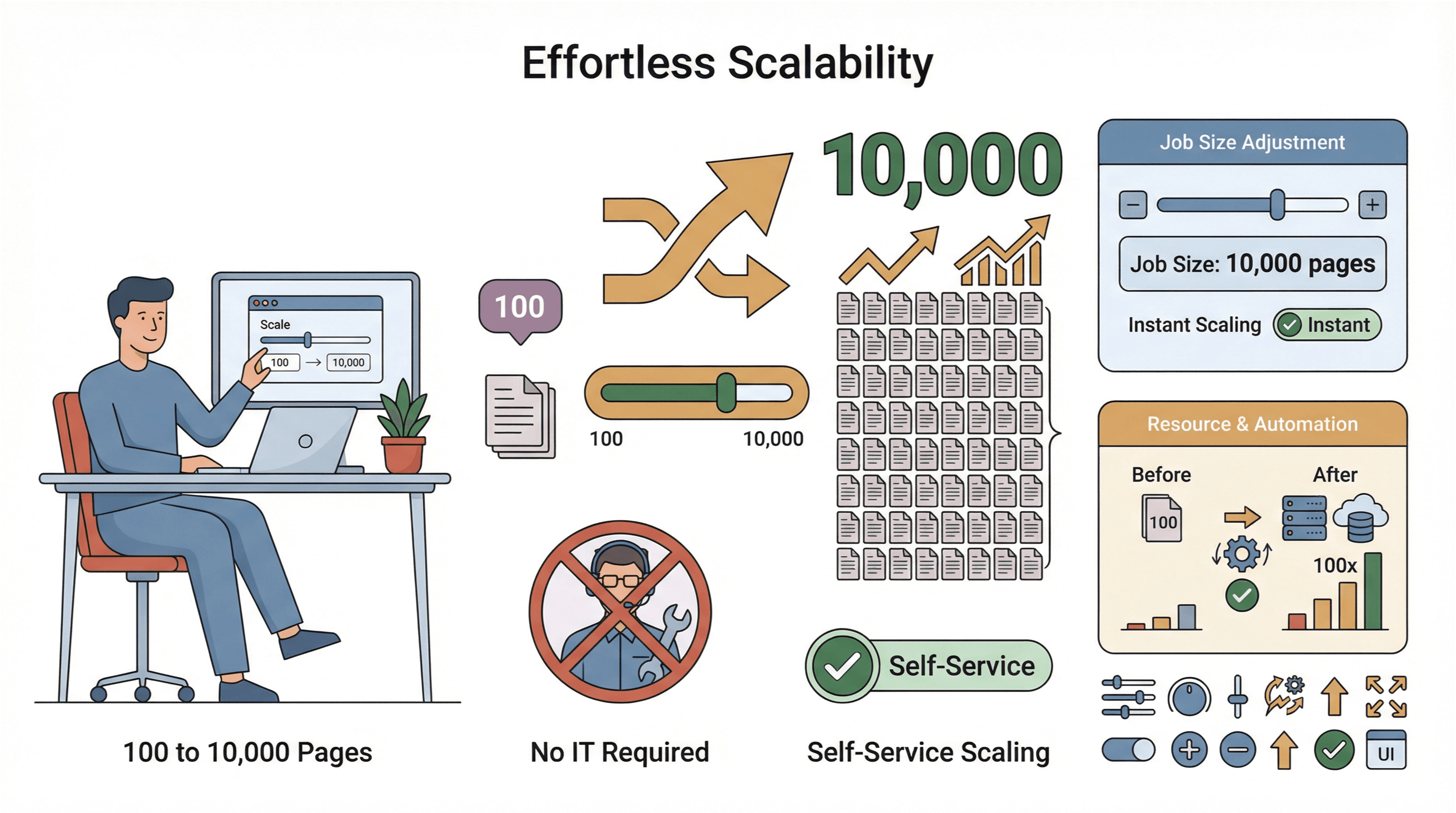
- Globální sběr dat: Díky cloud serverům ve více regionech můžete přistupovat i k geograficky omezenému obsahu a lépe řešit compliance ().
Samozřejmě, bezpečnost a dodržování pravidel jsou vždy zásadní. Nejlepší cloud crawlery (včetně Thunderbit) používají šifrované spojení, respektují podmínky webů a nabízejí funkce, které vám pomáhají s citlivými daty zacházet zodpovědně.
Dopad v praxi: jak cloud crawlery mění strategie založené na datech
Pojďme na to prakticky. Proč firmy přecházejí na cloud crawlery? Protože vidí reálný a měřitelný dopad:
- Analýza trhu v reálném čase: Maloobchodníci používají cloud crawlery ke sledování cen a skladových zásob konkurence v reálném čase, což umožňuje dynamické ceny a rychlejší reakce na pohyby trhu ().
- Predikce spotřebitelských trendů: Značky agregují recenze, příspěvky ze sociálních sítí a diskuse na fórech, aby odhalily vznikající trendy a mohly okamžitě upravovat kampaně.
- Prodej a generování leadů: Obchodní týmy si skládají aktuální seznamy kontaktů z adresářů, eventových webů i PDF — a do CRM tak posílají čerstvé a kvalifikované leady ().
- Provoz a compliance: Finanční firmy využívají cloud crawlery ke sledování regulačních změn, zpráv a podání napříč jurisdikcemi — snižují riziko a drží si náskok před změnami.
Společný jmenovatel? Cloud crawlery umožňují týmům jednat rychleji, rozhodovat chytřeji a předbíhat konkurenci, která se stále vleče v pomalém pruhu.
Na co se zaměřit při výběru cloud crawleru
Ne každý cloud crawler je stejný. Pokud vybíráte řešení, zaměřte se na tyto vlastnosti (a právě tady Thunderbit vyniká):
- Škálovatelnost: Zvládne tisíce stránek najednou? Nezpomalí, když úloha naroste?
- Snadné použití: Je rozhraní přívětivé i pro netechnické uživatele? Dá se scraping nastavit na pár kliknutí?
- Podpora různých typů dat: Text, obrázky, PDF, podstránky — umí vše?
- Integrace: Exportuje do vašich oblíbených nástrojů (Excel, Sheets, Notion, Airtable)?
- Plánování: Umí opakované úlohy pro stále čerstvá data?
- AI asistence: Nabízí chytré návrhy polí, obohacování dat a přizpůsobení změnám webu?
- Bezpečnost a compliance: Jsou vaše data a přihlašovací údaje chráněné? Pomáhá vám dodržovat pravidla ochrany soukromí?
Thunderbit splňuje všechna tato kritéria, takže je skvělou volbou pro týmy, které chtějí výkon bez bolesti.
Začínáme: jak používat cloud crawler pro vaše podnikání
Jste připraveni začít? Takhle se běžný byznys uživatel může rozjet s cloud crawlerem, jako je Thunderbit:
- Nainstalujte si : Rychlé nastavení, bez zásahu IT.
- Vyberte cíl: Otevřete web, seznam nebo dokument, ze kterého chcete data získat.
- Klikněte na „AI Suggest Fields“: Nechte AI od Thunderbit stránky projít a doporučit nejlepší sloupce k extrakci.
- Upravte podle potřeby: Přidejte, odeberte nebo přejmenujte pole podle svých požadavků.
- Zvolte cloudový režim scrapingu: U velkých úloh nebo složitých webů přepněte do cloudového režimu pro maximální rychlost.
- Spusťte scraping: Thunderbit zpracuje v cloudu až 50 stránek najednou.
- Zkontrolujte a exportujte: Náhled výsledků a pak export do Excelu, Google Sheets, Notion nebo Airtable.
- Naplánujte opakované úlohy: Pro průběžné potřeby nastavte plánované scrapování — data se budou automaticky aktualizovat ().
Tip: Začněte s menší úlohou, ať si vše osaháte, a pak přidávejte. A nebojte se využít podporu nebo dokumentaci Thunderbit — jsou tu proto, aby vám pomohly.
Budoucnost sběru dat: co čeká cloud crawlery dál?
Revoluce kolem cloud crawlerů je teprve na začátku. Tohle budu v příštích letech sledovat:
- Chytřejší AI extrakce: Cloud crawlery se zlepšují v chápání kontextu, vztahů i sentimentu — a data, která sbírají, jsou díky tomu cennější ().
- Podpora nových typů dat: Lepší práce s videem, audiem a interaktivním obsahem, nejen se statickým textem a obrázky.
- Hlubší automatizace: Od automatického plánování po upozornění v reálném čase — cloud crawlery budou pro byznys uživatele ještě více bezstarostné.
- Silnější compliance: Jak se vyvíjí zákony o ochraně soukromí, cloud crawlery přidají více nástrojů, které týmům pomohou zůstat v souladu s pravidly.
- Napojení na BI a AI nástroje: Přímé datové pipeline z cloud crawlerů do analytiky, dashboardů a platforem strojového učení.
Stručně řečeno: cloud crawlery mají nakročeno stát se páteří digitální business strategie — od produktových launchů až po AI forecasting ().
Závěr: proč jsou cloud crawlery pro moderní firmy nezbytné
Ve zkratce: web je zaplavený daty a staré způsoby jejich sběru už tempo prostě nestíhají. Cloud crawlery představují další evoluční krok — nabízejí rychlost, škálování a inteligenci, které tradiční scrapery jednoduše nemají. Nástroje jako umožňují každému týmu, technickému i netechnickému, vytěžit plný potenciál webových dat — dělat chytřejší rozhodnutí, reagovat rychleji a získat skutečnou konkurenční výhodu.
Pokud jste připraveni odložit ruční scraping a pomalé zpracování dat, teď je ten správný čas zjistit, co může cloud crawler udělat pro vaše podnikání. Vyzkoušejte cloud scraping režim Thunderbit a přesvědčte se, jak snadné — a výkonné — může moderní objevování dat být. A pokud chcete jít ještě víc do hloubky, podívejte se na , kde najdete další návody, tipy i příklady z praxe.
Často kladené otázky
1. Co je cloud crawler jednoduše řečeno?
Cloud crawler je cloudový nástroj, který automaticky vyhledává, extrahuje a analyzuje velké množství dat z webu. Na rozdíl od tradičních scraperů, které běží na vašem lokálním zařízení, cloud crawlery fungují v silných datacentrech, takže zvládnou velký rozsah i vysokou rychlost.
2. V čem se cloud crawler liší od běžného web scraperu?
Cloud crawlery běží v cloudu, zpracují tisíce stránek najednou, podporují složité datové typy, jako jsou obrázky a PDF, a nevyžadují údržbu ani lokální hardware. Tradiční scrapery jsou omezené výkonem vašeho zařízení a hodí se spíš pro menší a jednodušší úlohy.
3. Jaké jsou hlavní výhody používání cloud crawleru?
Cloud crawlery nabízejí rychlý sběr dat ve velkém, podporu složitých webů, přístup odkudkoli a pokročilé funkce, jako je plánování a AI extrakce. Jsou ideální pro firmy, které potřebují rychle čerstvá a použitelná data.
4. Jak cloud crawler od Thunderbit funguje pro byznys uživatele?
Cloud crawler od Thunderbit vám umožní nastavit scraping během několika kliknutí — bez programování. Můžete extrahovat data z webů, PDF i obrázků, obohatit je pomocí AI a rovnou exportovat do Excelu, Google Sheets, Notion nebo Airtable. Je navržený pro netechnické uživatele, kteří chtějí výsledky, ne složitost.
5. Je cloud crawling bezpečný a v souladu se zákony o ochraně osobních údajů?
Ano, přední cloud crawlery jako Thunderbit používají šifrované spojení a osvědčené postupy pro zabezpečení dat. Vždy ale dbejte na to, abyste sbírali jen veřejně dostupná data a respektovali podmínky použití webu i pravidla ochrany soukromí.
Chcete vidět, co cloud crawler dokáže? a začněte ještě dnes objevovat svět velkoobjemového sběru dat v cloudu.
Zjistit více