
Web je zaplavený cennými daty — ať už pracujete v prodeji, e-commerce nebo průzkumu trhu, web scraping je tajná zbraň pro generování leadů, sledování cen a konkurenční analýzu. Jenže háček je v tom, že čím víc firem scraping používá, tím tvrději se weby brání. Ve skutečnosti už a jsou dnes standardem. Pokud jste někdy sledovali, jak váš Python skript 20 minut běží hladce — a pak najednou narazí na zeď chyb 403 — víte, jak je to frustrující.
Roky jsem pracoval v SaaS a automatizaci a na vlastní oči jsem viděl, jak se scrapingové projekty mohou během chvilky změnit z „wow, to je snadné“ na „proč jsem zablokovaný všude?“ Tak pojďme na to prakticky: ukážu vám, jak dělat web scraping v Pythonu, aniž byste byli zablokováni, podělím se o osvědčené techniky i ukázky kódu a ukážu, kdy je čas zvážit alternativy s podporou AI, jako je . Ať už jste Python profík, nebo se ve scrapingu teprve tak nějak plácáte, odnesete si toolkit pro spolehlivé získávání dat odolné vůči blokacím.
Co znamená dělat web scraping v Pythonu bez zablokování?
V jádru znamená web scraping bez zablokování získávání dat z webů takovým způsobem, aby nespustil jejich ochranu proti botům. V prostředí Pythonu to není jen o napsání smyčky requests.get() — jde o to zapadnout, napodobit skutečné uživatele a být o krok napřed před detekčními systémy.
Proč právě Python? díky své jednoduché syntaxi, obrovskému ekosystému (například requests, BeautifulSoup, Scrapy, Selenium) a flexibilitě pro vše od rychlých skriptů po distribuované crawlery. Jenže popularita má i cenu: mnoho anti-bot systémů je dnes nastaveno tak, aby rozpoznávalo vzorce scrapingu založené na Pythonu.
Jestli chcete data získávat spolehlivě, musíte jít nad rámec základů. To znamená rozumět tomu, jak weby boty detekují, a jak je můžete přechytračit — samozřejmě bez překročení etických nebo právních hranic.
Proč je vyhýbání se blokaci důležité pro projekty web scrapingu v Pythonu
Zablokování není jen drobný technický problém — může shodit celé firemní workflow. Rozdělme si to:
| Případ použití | Dopad zablokování |
|---|---|
| Generování leadů | Neúplné nebo zastaralé seznamy kontaktů, ztracené prodeje |
| Sledování cen | Promarněné změny cen konkurence, špatná cenotvorba |
| Agregace obsahu | Mezery ve zpravodajských, recenzních nebo výzkumných datech |
| Market intelligence | Slepoé místo při sledování konkurence nebo oboru |
| Nabídky nemovitostí | Nepřesná nebo zastaralá data o nemovitostech, promarněné příležitosti |
Když se scraper zablokuje, nepřicházíte jen o data — plýtváte zdroji, riskujete problémy s dodržováním pravidel a můžete dělat špatná obchodní rozhodnutí na základě neúplných informací. Ve světě, kde , je spolehlivost naprosto klíčová.
Jak weby detekují a blokují Pythonové web scrapery
Weby jsou v rozpoznávání botů čím dál chytřejší. Tohle jsou nejčastější obranné mechanismy proti scrapingu, se kterými se setkáte (, ):
- Blokování IP adres: Příliš mnoho požadavků z jedné IP? Zablokováno.
- Kontrola User-Agentu a hlaviček: Požadavky bez hlaviček nebo s obecným nastavením (například výchozí
python-requests/2.25.1) jsou podezřelé. - Rate limiting: Příliš mnoho požadavků v krátkém čase spustí zpomalení nebo ban.
- CAPTCHA: Úlohy typu „dokaž, že jsi člověk“, které boti (snadno) nezvládnou.
- Analýza chování: Weby sledují robotické vzorce — třeba klikání na stejné tlačítko v pravidelných intervalech.
- Honeypoty: Skryté odkazy nebo pole, se kterými interagují jen boti.
- Fingerprinting prohlížeče: Sběr detailů o vašem prohlížeči a zařízení za účelem odhalení automatizace.
- Sledování cookies a relací: Boti, kteří správně nepracují s cookies nebo relacemi, bývají označeni.
Představte si to jako letištní kontrolu: když vypadáte, chováte se a pohybujete jako všichni ostatní, projdete hladce. Když dorazíte v dlouhém kabátu a slunečních brýlích, čekejte další otázky.
Základní Python techniky pro web scraping bez zablokování
Teď k tomu podstatnému: jak se při scrapingu v Pythonu skutečně vyhnout blokaci. Tady jsou klíčové strategie, které by měl znát každý scraper:

Rotace proxy serverů a IP adres
Proč je to důležité: Když všechny požadavky přicházejí z jedné IP, jste snadný cíl pro blokaci. Rotující proxy vám umožní rozložit požadavky mezi více IP adres, takže vás bude mnohem těžší zablokovat.
Jak na to v Pythonu:
1import requests
2proxies = [
3 "<http://proxy1.example.com:8000>",
4 "<http://proxy2.example.com:8000>",
5 # ...další proxy
6]
7for i, url in enumerate(urls):
8 proxy = {"http": proxies[i % len(proxies)]}
9 response = requests.get(url, proxies=proxy)
10 # zpracování odpovědiPro větší spolehlivost můžete použít placené proxy služby (například residential nebo rotující proxy) ().
Nastavení User-Agentu a vlastních hlaviček
Proč je to důležité: Výchozí hlavičky Pythonu křičí „bot“. Napodobte reálné prohlížeče nastavením user-agentu a dalších hlaviček.
Ukázka kódu:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9",
4 "Accept-Encoding": "gzip, deflate, br",
5 "Connection": "keep-alive"
6}
7response = requests.get(url, headers=headers)Pro větší nenápadnost rotujte user-agent ().
Náhodné načasování a vzorce požadavků
Proč je to důležité: Boti jsou rychlí a předvídatelní; lidé jsou pomalejší a nepravidelní. Přidejte prodlevy a promíchejte způsob navigace.
Tip v Pythonu:
1import time, random
2for url in urls:
3 response = requests.get(url)
4 time.sleep(random.uniform(2, 7)) # Počkej 2–7 sekundPokud používáte Selenium, můžete náhodně měnit i cesty klikání a vzorce scrollování.
Správa cookies a relací
Proč je to důležité: Mnoho webů vyžaduje cookies nebo session tokeny, aby zpřístupnilo obsah. Boti, kteří je ignorují, bývají zablokováni.
Jak na to v Pythonu:
1import requests
2session = requests.Session()
3response = session.get(url)
4# session bude cookies spravovat automatickyPro složitější toky použijte Selenium k zachycení a opětovnému použití cookies.
Napodobení lidského chování pomocí headless prohlížečů
Proč je to důležité: Některé weby používají JavaScript, pohyb myši nebo scrollování jako signál skutečného uživatele. Headless prohlížeče jako Selenium nebo Playwright umějí tyto akce napodobit.
Příklad se Selenium:
1from selenium import webdriver
2from selenium.webdriver.common.action_chains import ActionChains
3import random, time
4driver = webdriver.Chrome()
5driver.get(url)
6actions = ActionChains(driver)
7actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
8time.sleep(random.uniform(2, 5))To pomáhá obejít analýzu chování a dynamický obsah ().
Pokročilé strategie: obcházení CAPTCHA a honeypotů v Pythonu
CAPTCHA jsou navržené tak, aby boty zastavily hned na místě. I když některé Python knihovny umějí jednoduché CAPTCHA řešit, většina seriózních scraperů spoléhá na služby třetích stran (například 2Captcha nebo Anti-Captcha), které je za poplatek vyřeší ().
Ukázka integrace:
1# Pseudokód pro použití 2Captcha API
2import requests
3captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
4# Počkejte na řešení a pak ho odešlete spolu s požadavkemHoneypoty jsou skrytá pole nebo odkazy, se kterými budou interagovat jen boti. Vyhněte se klikání nebo odesílání čehokoli, co není v běžném prohlížeči viditelné ().
Jak v Python knihovnách navrhnout robustní hlavičky požadavků
Kromě user-agentu můžete rotovat a náhodně měnit i další hlavičky (například Referer, Accept, Origin apod.), abyste ještě lépe zapadli.
V Scrapy:
1class MySpider(scrapy.Spider):
2 custom_settings = {
3 'DEFAULT_REQUEST_HEADERS': {
4 'User-Agent': '...',
5 'Accept-Language': 'en-US,en;q=0.9',
6 # Další hlavičky
7 }
8 }V Selenium: Použijte profily prohlížeče nebo rozšíření pro nastavení hlaviček, případně je vkládejte pomocí JavaScriptu.
Udržujte seznam hlaviček aktuální — inspirujte se skutečnými požadavky prohlížeče v DevTools.
Když tradiční scraping v Pythonu nestačí: nástup anti-bot technologií
Realita je taková, že s rostoucí popularitou scrapingu rostou i anti-bot ochrany. . Detekce řízená AI, dynamické prahy pro požadavky a fingerprinting prohlížeče dělají i pro pokročilé Python skripty stále těžší zůstat neodhaleny ().
Někdy, ať je váš kód jakkoli chytrý, narazíte na zeď. A právě tehdy dává smysl zvážit jiný přístup.
Thunderbit: AI Web Scraper jako alternativa k Python scrapingu
Když Python narazí na své limity, přichází jako no-code AI Web Scraper navržený pro firemní uživatele — ne jen pro vývojáře. Místo zápasu s proxy, hlavičkami a CAPTCHA Thunderbitův AI agent přečte web, navrhne nejlepší pole k extrakci a zvládne vše od navigace na podstránky po export dat.
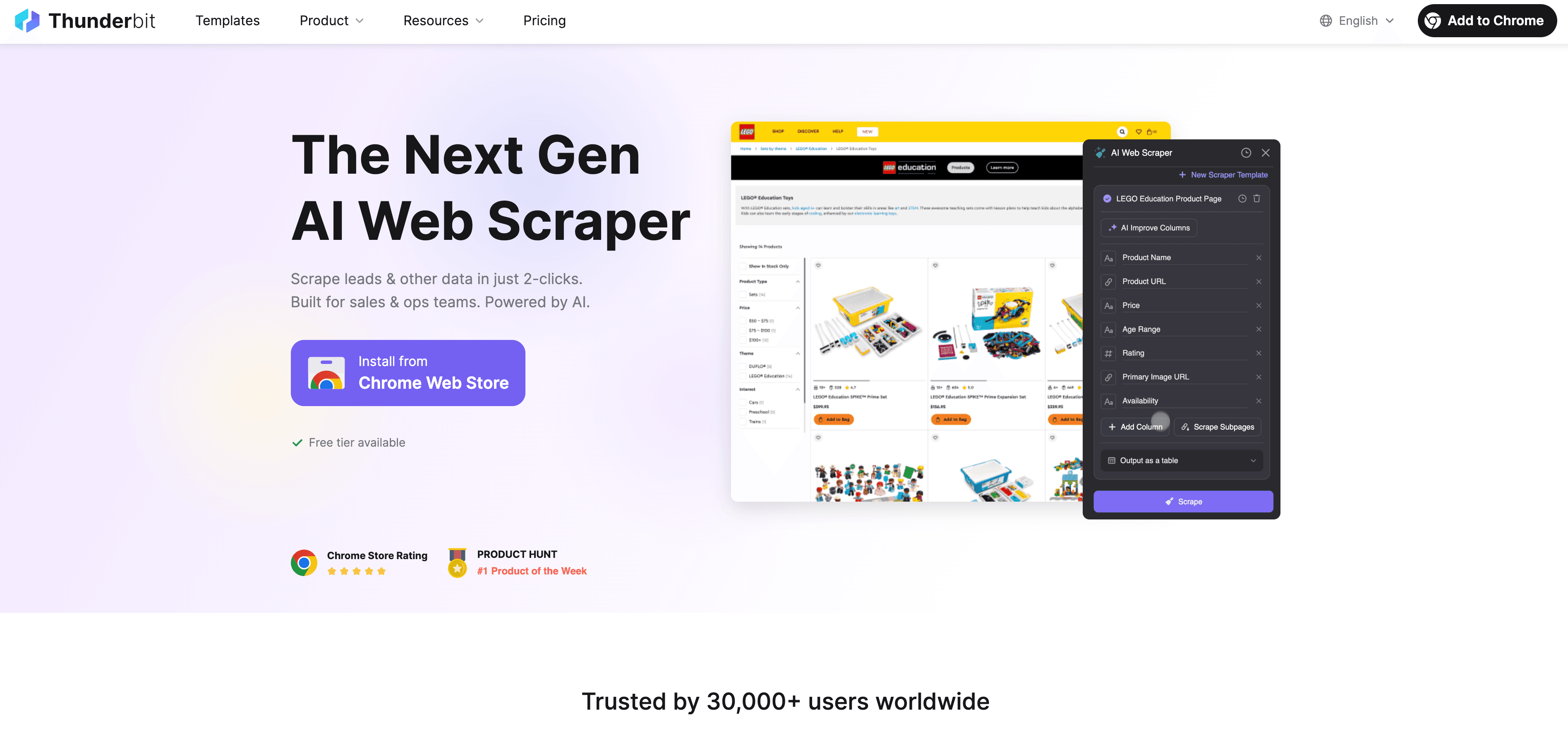
Čím je Thunderbit jiný?
- AI návrh polí: Klikněte na „AI Suggest Fields“ a Thunderbit projde stránku, doporučí sloupce a dokonce vygeneruje instrukce pro extrakci.
- Scraping podstránek: Thunderbit umí navštívit každou podstránku (například detaily produktů nebo profily na LinkedIn) a automaticky obohatit vaši tabulku.
- Cloud nebo prohlížečový scraping: Zvolte nejrychlejší možnost — cloud pro veřejné weby, prohlížeč pro stránky chráněné přihlášením.
- Plánovaný scraping: Nastavíte jednou a máte hotovo — Thunderbit může scrapeovat podle harmonogramu, takže vaše data budou vždy čerstvá.
- Okamžité šablony: Pro populární weby (Amazon, Zillow, Shopify atd.) nabízí Thunderbit šablony na jedno kliknutí — bez nastavování.
- Export dat zdarma: Export do Excelu, Google Sheets, Airtable nebo Notion — bez dalších poplatků.
Thunderbitu důvěřuje více než a nemusíte napsat ani jediný řádek kódu.
Jak Thunderbit pomáhá uživatelům vyhnout se blokaci a automatizovat extrakci dat
Thunderbitova AI jen nenapodobuje lidské chování — v reálném čase se přizpůsobuje každému webu, a tím snižuje riziko blokace. Funguje to takto:
- AI se přizpůsobuje změnám rozhraní: Už žádné rozbité skripty, když web změní design.
- Zpracování podstránek a stránkování: Thunderbit automaticky sleduje odkazy a seznamy rozdělené do více stran, stejně jako skutečný uživatel.
- Cloud scraping ve velkém měřítku: Scrapujte až 50 stránek najednou, bleskově rychle.
- Žádné kódování, žádná údržba: Místo ladění skriptů se můžete věnovat analýze.
Pro hlubší ponor se podívejte na .
Porovnání scrapingu v Pythonu a Thunderbitu: co si vybrat?
Dejme je vedle sebe:
| Funkce | Scraping v Pythonu | Thunderbit |
|---|---|---|
| Čas na nastavení | Střední až vysoký (skripty, proxy atd.) | Nízký (2 kliknutí, zbytek udělá AI) |
| Technické dovednosti | Vyžaduje programování | Bez programování |
| Spolehlivost | Proměnlivá (snadno se rozbíjí) | Vysoká (AI se přizpůsobuje změnám) |
| Riziko blokace | Střední až vysoké | Nízké (AI napodobuje uživatele, přizpůsobuje se) |
| Škálovatelnost | Vyžaduje vlastní kód/cloud nastavení | Vestavěný cloudový/batch scraping |
| Údržba | Častá (změny webu, blokace) | Minimální (AI se automaticky upravuje) |
| Možnosti exportu | Ruční (CSV, DB) | Přímý export do Sheets, Notion, Airtable, CSV |
| Cena | Zdarma (ale časově náročné) | Bezplatný tarif, placené plány pro větší škálu |
Kdy použít Python:
- Potřebujete plnou kontrolu, vlastní logiku nebo integraci s jinými Python workflow.
- Scrapujete weby s minimální ochranou proti botům.
Kdy použít Thunderbit:
- Chcete rychlost, spolehlivost a nulové nastavování.
- Scrapujete složité nebo často se měnící weby.
- Nechcete řešit proxy, CAPTCHA ani kód.
Návod krok za krokem: Jak nastavit web scraping v Pythonu bez zablokování
Projděme si praktický příklad: scraping produktových dat ze vzorového webu s použitím osvědčených postupů proti blokaci.
1. Nainstalujte potřebné knihovny
1pip install requests beautifulsoup4 fake-useragent2. Připravte skript
1import requests
2from bs4 import BeautifulSoup
3from fake_useragent import UserAgent
4import time, random
5ua = UserAgent()
6urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # Nahraďte vlastními URL
7for url in urls:
8 headers = {
9 "User-Agent": ua.random,
10 "Accept-Language": "en-US,en;q=0.9"
11 }
12 response = requests.get(url, headers=headers)
13 if response.status_code == 200:
14 soup = BeautifulSoup(response.text, "html.parser")
15 # Zde extrahujte data
16 print(soup.title.text)
17 else:
18 print(f"Na {url} zablokováno nebo chyba: {response.status_code}")
19 time.sleep(random.uniform(2, 6)) # Náhodná prodleva3. Přidejte rotaci proxy (volitelné)
1proxies = [
2 "<http://proxy1.example.com:8000>",
3 "<http://proxy2.example.com:8000>",
4 # Další proxy
5]
6for i, url in enumerate(urls):
7 proxy = {"http": proxies[i % len(proxies)]}
8 headers = {"User-Agent": ua.random}
9 response = requests.get(url, headers=headers, proxies=proxy)
10 # ...zbytek kódu4. Ošetřete cookies a relace
1session = requests.Session()
2for url in urls:
3 response = session.get(url, headers=headers)
4 # ...zbytek kódu5. Tipy pro řešení problémů
- Pokud vidíte spoustu chyb 403/429, zpomalte požadavky nebo zkuste nové proxy.
- Pokud narazíte na CAPTCHA, zvažte Selenium nebo službu pro řešení CAPTCHA.
- Vždy si zkontrolujte
robots.txta podmínky používání webu.
Závěr a klíčové poznatky
Web scraping v Pythonu je silný nástroj — ale s tím, jak se anti-bot technologie vyvíjejí, je zablokování neustálé riziko. Nejlepší způsob, jak se blokacím vyhnout? Kombinovat technické best practices (rotující proxy, chytré hlavičky, náhodné prodlevy, práci se session a headless prohlížeče) se zdravým respektem k pravidlům webu a etice.
Jenže někdy ani ty nejlepší Python triky nestačí. A právě tady zazáří nástroje s AI, jako je — nabízí no-code, na blokaci odolný a pro byznys přátelský způsob, jak rychle získat data, která potřebujete.
Chcete vidět, jak snadný může scraping být? a vyzkoušejte si ho sami — nebo se podívejte na náš pro další tipy a návody k scrapingu.
Často kladené otázky
1. Proč weby blokují Pythonové web scrapery?
Weby scrapery blokují, aby chránily svá data, zabránily přetížení serveru a zastavily automatizované boty ve zneužívání jejich služeb. Python skripty jsou snadno odhalitelné, pokud používají výchozí hlavičky, nepracují s cookies nebo posílají příliš mnoho požadavků v příliš krátkém čase.
2. Jaké jsou nejúčinnější způsoby, jak se při scrapingu v Pythonu vyhnout zablokování?
Používejte rotující proxy, nastavte realistický user-agent a hlavičky, náhodně měňte načasování požadavků, spravujte cookies/relace a napodobujte lidské chování pomocí nástrojů jako Selenium nebo Playwright.
3. Jak Thunderbit pomáhá vyhnout se blokaci ve srovnání s Python skripty?
Thunderbit používá AI, která se přizpůsobuje rozvržení webu, napodobuje lidské prohlížení a automaticky zvládá podstránky i stránkování. Snižuje riziko blokace tím, že zapadá do běžného provozu a v reálném čase upravuje svůj přístup — bez nutnosti kódu nebo proxy.
4. Kdy mám použít scraping v Pythonu a kdy nástroj s AI, jako je Thunderbit?
Python použijte, když potřebujete vlastní logiku, integraci s dalším Python kódem nebo scrapujete jednoduché weby. Thunderbit zvolte pro rychlý, spolehlivý a škálovatelný scraping — hlavně když jsou weby složité, často se mění nebo skripty agresivně blokují.
5. Je web scraping legální?
Web scraping je legální pro veřejně dostupná data, ale musíte respektovat podmínky použití webu, zásady ochrany soukromí a příslušné zákony. Nikdy nescrapujte citlivá nebo soukromá data a vždy postupujte eticky a zodpovědně.
Připraveni scrapovat chytřeji, ne tvrději? Vyzkoušejte Thunderbit a zbavte se blokací.
Další čtení:
- Scraping Google News v Pythonu: návod krok za krokem
- Vytvořte si nástroj pro sledování cen Best Buy pomocí Pythonu
- 14 způsobů, jak dělat web scraping bez zablokování
- 10 nejlepších tipů, jak se při web scrapingu nenechat zablokovat