Je web scraping nezákonný? To je ta otázka za milion dolarů, kterou každý týden slýchám od zakladatelů, marketérů i datových nadšenců.
Když dnes — vůbec poprvé v historii automatizovaný provoz převýšil ten lidský — a velká část toho připadá na web scraping pro business intelligence, prodej i trénování AI, není divu, že se všichni snaží zjistit, kde přesně leží právní hranice.
Jeden den narazíte na titulek o soudním rozhodnutí, podle kterého je scraping veřejných dat v pořádku. Druhý den regulátoři varují před „nezákonným“ sběrem dat ze sociálních sítí. Je to matoucí, a to i pro lidi jako já, kteří denně staví AI web scraping nástroje ve společnosti .
Takže: je web scraping nezákonný? Odpověď není jednoduché ano nebo ne. Záleží na tom, co scrapujete, odkud data berete, jak je používáte a co o tom říká zákon ve vaší zemi.
V tomhle podrobném průvodci rozeberu právní prostředí, vyvrátím několik rozšířených mýtů a přidám praktické tipy i pár zkušeností z praxe, jak zůstat v souladu s pravidly — ať už jste sólo zakladatel, nebo datový tým z Fortune 500.
Web scraping a zákon: Existuje jasná hranice?
Pokud doufáte v odpověď jednou větou, ušetřím vám čas: zákon zatím web scraping nenačrtl do žádné ostré, jasné linie.
Místo toho jde o mozaiku překrývajících se pravidel — vlastnictví dat, soukromí, duševní vlastnictví, zákony proti hackingu a nechvalně proslulé podmínky služby (ToS). Každé z nich může vstoupit do hry a výsledek často závisí na konkrétní situaci ().
Pojďme si rozebrat tři hlavní právní oblasti:
- Vlastnictví dat: Obecně platí, že fakta a veřejně dostupné informace (například ceny nebo telefonní čísla) nejsou chráněny autorským právem. Kreativní obsah (články, obrázky) a proprietární databáze ale chráněné být mohou — zejména v EU, kde existují i tzv. „database rights“ ().
- Soukromí: Moderní zákony na ochranu soukromí (například GDPR v Evropě nebo PIPL v Číně) považují osobní údaje za regulované aktivum — i když jsou zveřejněné veřejně. Scraping jmen, e-mailů nebo profilů na sociálních sítích bez právního důvodu vás může dostat do problémů ().
- Smlouvy (podmínky služby): Mnoho webů scraping výslovně zakazuje ve svých ToS. I když ToS nejsou zákon, soudy je mohou brát jako závaznou smlouvu. Jejich porušení může vést k žalobám a někdy i k použití protihackingových zákonů, pokud obejdete technické překážky ().
Takže: je web scraping nezákonný? Někdy ano, někdy ne a často „záleží na okolnostech“. Ďábel je v detailech.
Srovnání právních pohledů: USA, EU, UK, Čína
Tady je rychlá tabulka, která ukazuje, jak k web scrapingu přistupují hlavní regiony:
| Region | Scraping veřejných dat | Scraping osobních/soukromých dat | Vymáhání a důležité body |
|---|---|---|---|
| USA | Obecně povolen pro veřejná data (viz hiQ v. LinkedIn). Porušení ToS může vést k civilním žalobám. | Omezený/nelegální, pokud obcházíte přihlášení nebo zneužíváte osobní údaje. Mohou se uplatnit státní zákony (např. CCPA). | Výzvy k ukončení, blokování IP, žaloby. CFAA platí, pokud obejdete technické bariéry. |
| EU | Podmíněně povolen pro neosobní veřejná data. Mohou se uplatnit práva k databázím. EU AI Act (2026) přidává požadavky na transparentnost trénovacích dat pro AI. | Silně regulováno GDPR — i veřejně dostupná osobní data potřebují právní základ. | Úřady pro ochranu osobních údajů mohou udělovat pokuty za porušení soukromí. Vymáhají se i autorská práva a práva k databázím. EU AI Act zakazuje scraping obličejových snímků pro AI. |
| UK | Podobné jako EU. Veřejná, neosobní data lze scrapovat, ale je nutné respektovat práva k datům a smluvní podmínky. | Přísné u osobních údajů — platí UK GDPR. Computer Misuse Act kriminalizuje neoprávněný přístup. | ICO může sankcionovat porušení ochrany dat. Soudy mohou vymáhat ToS. |
| Čína | Přísně kontrolováno. Veřejná, neosobní data lze scrapovat pro interní použití, ale prostředí je opatrné. | Vysoce omezeno — PIPL vyžaduje souhlas pro osobní údaje. Uplatňuje se i zákon proti nekalé soutěži. | Trestní případy při rozsáhlém scrapingu. Soudy používají právo proti nekalé soutěži k zastavení neoprávněného scrapingu. |
(, )
Je web scraping nezákonný? Klíčové právní faktory, které je třeba zvážit
Co tedy ve skutečnosti rozhoduje o tom, jestli je váš scrapingový projekt legální, nebo riskantní? Tady jsou hlavní faktory:
- Veřejná vs. soukromá data: Scraping dat, která může na otevřeném webu vidět kdokoli, je obecně bezpečnější. Scraping čehokoli za přihlášením, paywallem nebo technickou bariérou? To už je velmi pravděpodobně nelegální ().
- Povaha dat: Osobní údaje (jména, e-maily, profily) aktivují zákony na ochranu soukromí. Obsah chráněný autorským právem (články, obrázky) nelze kopírovat ve velkém. Čistá fakta (ceny, počasí) jsou obvykle volně použitelná ().
- Zamýšlené použití: Interní analýza nebo výzkum jsou posuzovány mírněji než znovupublikování nebo prodej vyextrahovaných dat. Použít scraped data k přímé konkurenci se zdrojem? To si koleduje o žalobu ().
- Dodržení pravidel webu: Vždy zkontrolujte robots.txt a ToS. Robots.txt není právně závazný, ale je slušnost ho respektovat. Porušení ToS může znamenat civilní žaloby nebo i něco horšího ().
- Technická opatření: Klíčové je scrapovat lidským tempem a neobcházet bezpečnostní opatření. Příliš agresivní zátěž serveru nebo obcházení CAPTCHA může spadat do roviny hackingu ().
Co se změnilo v letech 2024–2026: Klíčové soudní případy a regulace
Právní prostředí pro web scraping se od roku 2023 výrazně proměnilo. Tady jsou vývoje, které by měl znát každý scraper:
Hlavní soudní rozhodnutí
-
Meta v. Bright Data (2024): Americký federální soud . Soudce konstatoval, že „návštěvník není považován za ‚uživatele‘, pokud nemá účet“. Meta brzy poté stáhla zbývající nároky. To je přelomové vítězství pro scraping veřejných dat.
-
X Corp v. Bright Data (2024): Twitter (nyní X) prohrál podobný spor, čímž se potvrdil stejný princip: scraping veřejně dostupných dat bez přihlášení neporušuje ToS, protože scraper s těmito podmínkami nikdy výslovně nesouhlasil.
-
Reddit v. Perplexity AI (říjen 2025): Reddit , s odkazem na DMCA a s tvrzením o obcházení anti-bot systémů. To naznačuje novou právní strategii: platformy přecházejí na nároky z autorského práva a obcházení ochranných opatření místo CFAA.
-
NYT v. OpenAI (březen 2025): Federální soudce a zamítl návrh OpenAI na zamítnutí. To může vytvořit důležitý precedens pro otázku, zda scraping obsahu pro trénování AI modelů spadá pod „fair use“.
-
Narovnání Anthropic (září 2025): Anthropic souhlasil s úhradou 1,5 miliardy USD jako narovnání hromadné žaloby na autorská práva v USA kvůli použití chráněných textů pro trénování svého AI modelu — což ukazuje, že náklady na scraping pro AI jsou velmi reálné.
Hlavní trend: od CFAA ke smluvnímu a autorskému právu
Vzorec je jasný: CFAA (Computer Fraud and Abuse Act) ztrácí sílu jako zbraň proti scraperům veřejných dat. Společnosti, které se snažily použít CFAA proti scrapingu veřejných dat — Meta, X, LinkedIn — většinou neuspěly. Právní bojiště se přesouvá k:
- smluvnímu právu (porušení ToS — soudy ale říkají, že nepřihlášení uživatelé jimi nemusí být vázáni)
- nárokům z autorského práva (zejména u trénovacích dat pro AI)
- zákonům proti obcházení ochranných opatření (DMCA Section 1201)
Pro scrapers to znamená, že právní riziko nezmizelo — jen se přesunulo jinam.
Regulační změny
- Aktualizace CCPA 2026: Upravené kalifornské předpisy CCPA a přidaly nová pravidla pro technologie automatizovaného rozhodování (ADMT), posouzení rizik a povinnosti datových zprostředkovatelů.
- Nové zákony o ochraně soukromí v jednotlivých státech USA: Indiana, Kentucky a Rhode Island přijaly komplexní zákony o ochraně soukromí, účinné od roku 2026.
- EU AI Act: Plné vymáhání začíná — bude vyžadovat, aby vývojáři AI zveřejňovali zdroje trénovacích dat, respektovali opt-outy z autorských práv a zakazoval scraping obličejových snímků pro AI systémy.
- AI Accountability for Publishers Act (únor 2026): Navrhovaný americký zákon, který by vyžadoval, aby AI společnosti před scrapováním obsahu získaly souhlas a zaplatily vydavatelům.
Scrapingové zásady velkých platforem: Co potřebujete vědět
Ne všechny weby k scrapingu přistupují stejně. Tady je přehled podle platforem: co největší služby dovolují, co blokují a co na to říkají soudy:
| Platforma | ToS ke scrapingu | Technická obrana | Právní vymáhání | Co je prakticky bezpečné |
|---|---|---|---|---|
| Google (Search & Maps) | V ToS zakazuje automatizovaný přístup. Maps Platform má výslovnou klauzuli „No Scraping“. | Výzvy SearchGuard JS, CAPTCHA, omezení rychlosti. V roce 2025 aktualizoval robots.txt, aby blokoval AI crawlery. | V prosinci 2025 žaloval scrapers s odkazem na DMCA. Aktivně blokuje AI crawlery (Anthropic, Meta, OpenAI). | Scraping veřejných firemních dat z Google Maps je právně obhajitelný (precedens hiQ), ale počítejte s technickými blokacemi. Pokud to jde, používejte oficiální API. |
| Amazon | V Conditions of Use výslovně zakazuje veškerý scraping („žádný robot, spider, scraper ani jiné automatizované prostředky“). | Agresivní detekce botů, CAPTCHA, blokování IP. robots.txt blokuje všechny boty kromě Googlebot/Bingbot. Od roku 2025 výslovně blokuje i AI crawlery. | V listopadu 2025 zažaloval Perplexity AI. Pravidelně posílá výzvy k ukončení. V březnu 2026 aktualizoval BSA s pravidly pro AI agenty. | Veřejná produktová data (ceny, nabídky) jsou podle amerického práva faktická a lze je scrapovat, ale Amazon se brání velmi tvrdě. Zpomalte požadavky a vyhněte se osobním údajům. |
| V ToS scraping zakazuje; pro přístup ke službě vyžaduje souhlas uživatele. | U většiny profilových dat login wall, detekce botů, omezení rychlosti. | Případ hiQ potvrdil, že scraping veřejných profilů není porušením CFAA, ale LinkedIn vyhrál nároky ze smlouvy/nekalé soutěže, když byly použity falešné účty. | Veřejné profily viditelné bez přihlášení jsou právně obhajitelné ke scrapingu. Nikdy nevytvářejte falešné účty ani nescrapujte data za přihlášením. | |
| Meta (Facebook & Instagram) | ToS scraping zakazují; oddělená pravidla pro data z přihlášených a odhlášených uživatelů. | U většiny obsahu login wall, pokročilá detekce botů. | V roce 2024 prohrála s Bright Data — soud rozhodl, že ToS neplatí pro nepřihlášené scrapery. Zbývající nároky stáhla. | Veřejná data (firemní stránky, veřejné příspěvky) viditelná bez přihlášení jsou v bezpečnější pozici. Nikdy nescrapujte soukromé profily ani data za loginem. |
| X (Twitter) | V roce 2023 aktualizoval ToS tak, aby zakazoval veškerý scraping a crawling bez písemného souhlasu. Zrušil starou výjimku v robots.txt. | robots.txt blokuje všechny crawlery (Disallow: /). Výzvy Cloudflare Turnstile. Přísné limity rychlosti (300 požadavků/hod.). Hodnocení reputace IP. | Prohrál s Bright Data u veřejných dat, ale technický přístup omezuje agresivně. | Veřejné tweety a profily jsou právně obhajitelné, ale technické bariéry X patří v roce 2026 k nejtěžším. Počítejte s blokacemi bez prémiové proxy infrastruktury. |
Závěr: Soudy opakovaně rozhodly, že scraping veřejně viditelných dat bez přihlášení neporušuje CFAA. Platformy vás ale mohou dál žalovat na základě smluvního práva, autorského práva nebo obcházení ochranných opatření — a technickými bariérami vám život rozhodně znepříjemní. Scrapujte vždy zodpovědně.
Trénovací data pro AI a web scraping: Nová právní hranice
Pokud sledujete zprávy v roce 2026, víte, že scraping dat pro trénování AI modelů se stal nejžhavějším právním bojištěm. Tady je, co se děje:
- Žaloby z autorského práva přibývají. New York Times, autoři a vydavatelé žalují OpenAI, Anthropic a další s tvrzením, že masový scraping chráněného obsahu pro trénování LLM není „fair use“. Anthropic v roce 2025 uzavřel významnou hromadnou žalobu za 1,5 miliardy USD — což ukazuje, že náklady na scraping pro AI jsou skutečně vysoké.
- Obrana „fair use“ je nejistá. Americké soudy zatím nevydaly definitivní rozhodnutí o tom, zda je trénování AI na scrapaných datech fair use. První rozhodnutí naznačují, že hodně záleží na tom, jak byla data získána a co se s výstupem AI dělá.
- Přichází nová legislativa. (předložený v únoru 2026) chce po AI společnostech, aby před scrapováním obsahu získaly povolení a zaplatily vydavatelům.
- EU AI Act (plné vymáhání ) vyžaduje, aby vývojáři AI zveřejňovali zdroje trénovacích dat, respektovali strojově čitelné opt-outy z autorských práv (v rámci výjimky TDM ze směrnice o autorském právu) a označovali AI generovaný obsah. Zároveň zakazuje AI systémy, které scrapují obličejové snímky z internetu.
- AI/LLM crawlery explodují. AI crawlery během osmi měsíců ztrojnásobily až zčtyřnásobily svůj podíl na webovém provozu z 2,6 % na 10,1 %. Samotný GPTBot od OpenAI vzrostl o 305 %. V reakci na to velké weby (Amazon, Reddit, NYT) upravují robots.txt tak, aby AI crawlery výslovně blokovaly.
Co to znamená pro vás: Pokud scrapujete data pro klasické business účely (lead generation, sledování cen, průzkum trhu), tyto AI-specifické předpisy se vás nemusí přímo týkat. Pokud ale scrapaná data posíláte do AI modelů, postupujte velmi opatrně — a vyžádejte si právní radu.
Zákony o web scrapingu po světě: Rychlé srovnání
Podívejme se na to v globálním měřítku:
- Spojené státy: Žádný plošný zákaz. Scrapování veřejně přístupných webů je obecně legální (), a rozhodnutí v případech Meta a X Corp z roku 2024 pozici pro scraping veřejných dat ještě posílila. Scraping za přihlášením nebo technickými bariérami ale může stále aktivovat CFAA. Trend se nyní posouvá k tomu, že firmy používají spíše smluvní právo a nároky z autorského práva. Zákony na ochranu soukromí se rychle rozšiřují: CCPA dostala zásadní aktualizace s účinností od 1. ledna 2026, včetně nových pravidel pro automatizované rozhodování a povinností datových brokerů. Indiana, Kentucky a Rhode Island také v roce 2026 přijaly komplexní zákony na ochranu soukromí.
- Evropská unie: Přísné zákony na ochranu soukromí. GDPR platí i pro veřejně dostupná osobní data. Práva k databázím mohou blokovat rozsáhlý scraping strukturovaných dat (). NOVĚ: začne být naplno vymahatelný 2. srpna 2026, takže bude po vývojářích AI vyžadovat zveřejňování zdrojů trénovacích dat a respektování copyright opt-outů. Zákon zakazuje scraping obličejových snímků z internetu pro AI systémy.
- Spojené království: Po brexitu kopíruje pravidla EU. Veřejná data lze scrapovat, ale scraping osobních údajů je přísně regulován. Computer Misuse Act může neoprávněný přístup kriminalizovat.
- Čína: Velmi restriktivní. PIPL a zákon o bezpečnosti dat vyžadují souhlas pro osobní údaje. Soudy používají právo proti nekalé soutěži k blokování scrapingu, který škodí firmám ().
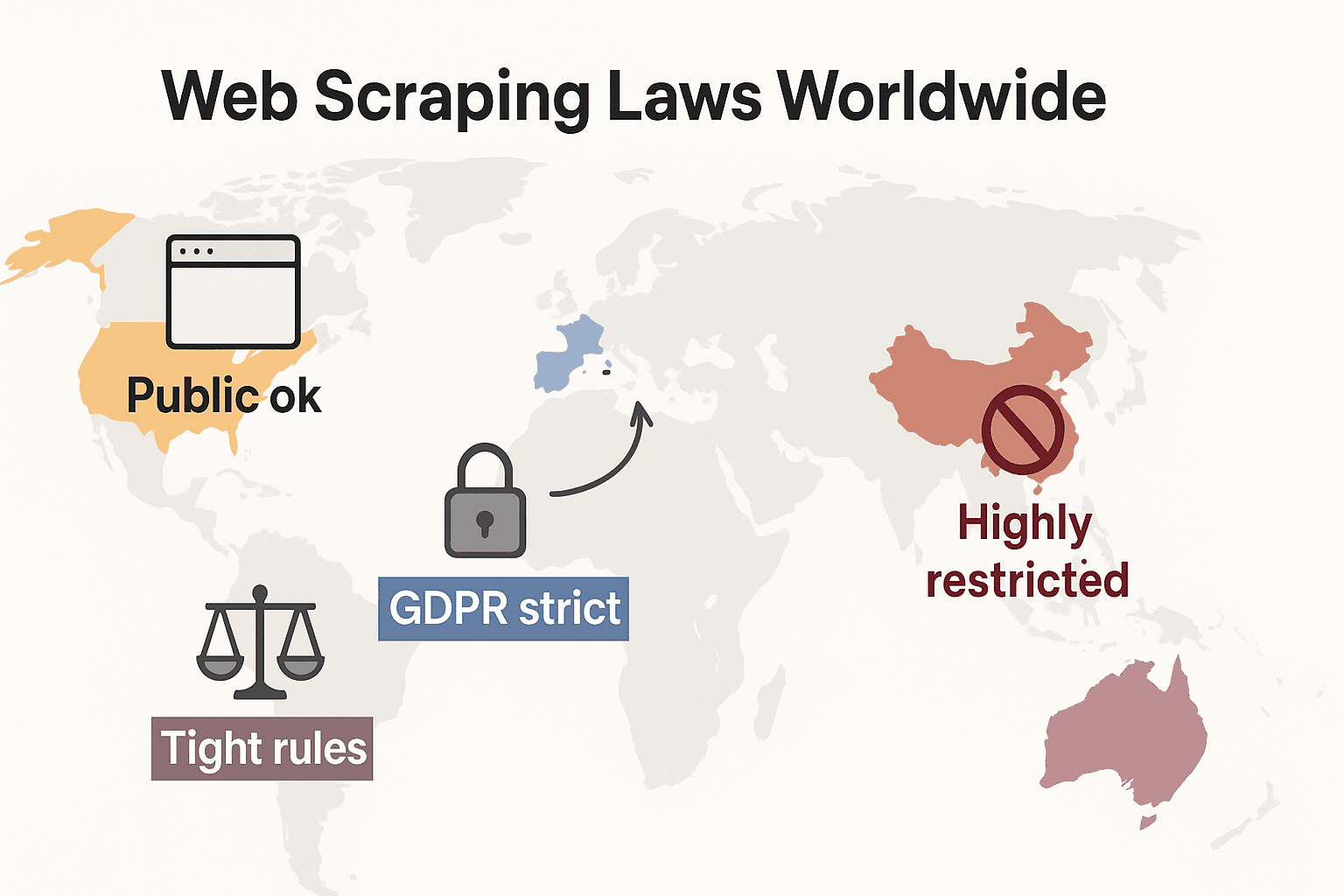
Shrnutí: nejbezpečnější je scraping veřejných, neosobních dat pro interní použití. Všechno ostatní? Zkontrolujte místní zákony a postupujte opatrně.
Časté mýty o legálnosti web scrapingu
Pojďme vyvrátit pár mýtů, které slýchám pořád dokola:
- Mýtus 1: „Web scraping je bez výjimky nezákonný.“
Nepravda. Neexistuje zákon, který by zakazoval veškerý web scraping. Rozhoduje to, jaká data scrapujete a co s nimi děláte (). - Mýtus 2: „Když jsou data veřejná, můžu s nimi dělat cokoli.“
Ne tak docela. Veřejná data mohou být stále chráněna zákony na ochranu soukromí nebo autorským právem a ToS mohou omezovat určité způsoby použití (). - Mýtus 3: „Web scraping je totéž co hacking.“
Ne. Scraping veřejných webových stránek není hacking. Obejít přihlášení nebo technické bariéry je ale jiný příběh (). - Mýtus 4: „Když mě nechytí, je to v pohodě.“
Riskantní myšlení. Mnoho webů používá anti-bot technologie a všimne si toho. Mlčení neznamená souhlas. - Mýtus 5: „Když uvedu zdroj nebo data použiju interně, je to v pořádku.“
Uvedení zdroje neobchází autorské právo ani právo na ochranu soukromí. Interní použití je bezpečnější, ale není to volná vstupenka. - Mýtus 6: „Každý web scraping porušuje soukromí.“
Ne každý scraping se týká osobních údajů. Ale scraping velkého množství osobních dat bez ochranných opatření je téměř vždy nezákonný (). - Mýtus 7: „Když ToS webu scraping zakazuje, je scraping vždy nezákonný.“
Ne nutně. V roce 2024 soudy v případech Meta v. Bright Data a X Corp v. Bright Data rozhodly, že ToS nemohou vázat uživatele, kteří s nimi nikdy nesouhlasili — tedy pokud scrapujete bez přihlášení nebo bez vytvoření účtu, ToS webu se na vás nemusí vztahovat. Je to stále vyvíjející se oblast, ale jde o významný posun.
Jak scrapovat data legálně: Nejlepší postupy pro soulad s pravidly
Tady je můj osvědčený checklist pro legální a etický web scraping:
- Přečtěte si a respektujte podmínky služby webu. Pokud píšou „no scraping“, zvažte, že přestanete, nebo si vyžádejte povolení ().
- Držte se veřejných dat. Pokud potřebujete heslo, jde o omezený obsah — nescrapujte ho ().
- Zkontrolujte robots.txt a crawlujte slušně. Není právně závazný, ale je to dobrá etiketa. Nezahlcujte servery — rozprostřete požadavky v čase ().
- Vyhněte se osobním údajům, pokud pro ně nemáte právní základ. Když je musíte sbírat, dodržujte GDPR/CCPA a minimalizujte rozsah.
- Nezveřejňujte scraped obsah ve velkém bez úprav. Přidejte hodnotu nebo analýzu, případně si vyžádejte souhlas ().
- Nenasouvejte scraped obsah do AI modelů bez kontroly autorských práv. Právní prostředí se mění rychle — pokud je to váš případ, poraďte se.
- Používejte oficiální API nebo exporty dat, když jsou k dispozici. Jsou navržené přesně pro tyto účely a bývají bezpečnější ().
- Buďte transparentní a odpovědní. Pokud sbíráte osobní údaje, informujte lidi a veďte záznam o aktivitách.
- Minimalizujte data a zabezpečte je. Sbírejte jen to, co opravdu potřebujete, udržujte data přesná a ukládejte je bezpečně.
- Sledujte změny a u hraničních případů si vyžádejte právní radu. Zákony i soudní rozhodnutí se mění rychle — zejména EU AI Act a státní zákony na ochranu soukromí v USA. Když si nejste jistí, zeptejte se odborníka.
Legální používání web scraping nástrojů: Co by firmy měly vědět
Web scraping nástroje jako zpřístupňují sběr dat i lidem bez programování, ale pořád je musíte používat zodpovědně:
- Vyberte nástroje zaměřené na compliance. Thunderbit například scrapuje jen to, co vidíte v prohlížeči — žádné skryté obcházení API ani neoprávněný přístup ().
- Držte se legitimních use casů. Interní analytika, průzkum trhu a sledování konkurenceschopných cen jsou obecně bezpečné. Znovupublikování nebo prodej scraped dat? To je mnohem rizikovější.
- Nastavte nástroje pro compliance. Nastavte prodlevy mezi crawlery, respektujte robots.txt a používejte šablony, které sbírají jen to, co potřebujete.
- Ponechte data uvnitř firmy. Interní použití scraped dat je bezpečnější než jejich znovupublikování.
- Vzdělávejte tým. Ujistěte se, že všichni znají pravidla a osvědčené postupy.
- Využívejte vestavěné compliance funkce. Thunderbit upozorňuje na rizikové weby, scrapuje lidskou rychlostí a neukládá vaše data na své servery.
- Netlačte na pilu. Pokud nástroj nějaký web nezvládne, nesnažte se to obejít hackováním. Ne všechna data lze získat bez rizika.
Přístup Thunderbitu: Umožnit souladné AI web scraping
Ve jsme strávili spoustu času přemýšlením o compliance. Tady je, jak náš AI Web Scraper pomáhá uživatelům zůstávat na správné straně zákona:
- Scrapuje jen to, co vidíte. Thunderbit funguje v rámci vaší relace v prohlížeči, takže se nedostane k datům, která byste nemohli ručně zkopírovat.
- Vede uživatele varováními. Když se pokusíte scrapovat web s přísnými anti-scraping pravidly, Thunderbit vás upozorní.
- Rychlost scrapingu jako u člověka. Ať už scrapujete lokálně, nebo v cloudu, Thunderbit nezahlcuje servery.
- Přizpůsobitelný výběr dat. Naše AI navrhuje relevantní sloupce, takže sbíráte jen to, co skutečně potřebujete.
- Práce s podstránkami a stránkováním. Thunderbit prochází weby jako skutečný uživatel a respektuje jejich strukturu.
- Soukromí a bezpečnost. Vaše data zůstávají u vás — Thunderbit je neukládá ani nepoužívá znovu.
- Exporty přívětivé pro compliance. Exportujte přímo do Google Sheets, Airtable, Notion nebo CSV pro bezpečné interní použití.
- Plánování a automatizace. Nastavte opakované scrapování v rozumných intervalech.
- Podpora více jazyků. Uživatelské rozhraní Thunderbitu podporuje 34 jazyků, takže je compliance dostupné globálně.
- Pravidelné aktualizace šablon. Naše instantní šablony pro populární weby průběžně aktualizujeme podle právních i technických změn.
Tím, že compliance zabudováváme přímo do produktu, Thunderbit pomáhá týmům sbírat data, která potřebují — bez právních bolestí hlavy.
Být napřed: Přizpůsobení se právním a technickým změnám v web scrapingu
Web scraping není hra typu nastav a zapomeň. Zákony i struktura webů se pořád vyvíjejí. Tady je, jak zůstat napřed:
- Sledujte právní vývoj. Tempo změn se v letech 2024–2026 výrazně zrychlilo — sledujte zprávy o technologickém právu, aktualizace regulátorů i odborné blogy v oboru (například ). Dávejte pozor na vymáhání EU AI Act (srpen 2026), nové státní zákony o ochraně soukromí v USA a probíhající spory o autorská práva v AI.
- Přizpůsobujte se technickým změnám. Weby neustále mění rozvržení i anti-bot obranu. Velké platformy (Amazon, X, Google) v letech 2025–2026 výrazně zpřísnily obranu. AI a šablony Thunderbitu jsou navržené tak, aby se přizpůsobovaly automaticky.
- Využívejte oficiální API, když jsou k dispozici. Pokud web přejde na placené API, zvažte přechod kvůli spolehlivosti i souladu s pravidly.
- Pravidelně auditujte scraping. Dokumentujte zdroje, sledujte změny ToS nebo zásad a podle potřeby upravujte strategii.
- Využívejte aktualizace šablon Thunderbitu. Náš tým drží šablony aktuální, takže se nemusíte bát změn struktury ani nových požadavků na compliance.
- Buďte flexibilní. Pokud se nějaký zdroj dat stane příliš rizikovým, přesuňte se jinam nebo hledejte partnerství.
Se správnými nástroji a správným přístupem můžete udržet datový pipeline v chodu — a přitom nešlapat na právní miny.
Závěr: Orientace v právním prostředí web scrapingu
Web scraping není sám o sobě nezákonný — je to silný nástroj pro byznys, výzkum i inovace. Ale jako každý nástroj má svá pravidla. Klíčem je rozumět tomu, co scrapujete, jak to scrapujete a co s daty uděláte. Respektujte místní zákony, dodržujte zásady webů a používejte compliance-friendly nástroje, jako je , abyste zůstali v souladu s pravidly.
Soudní rozhodnutí z let 2024–2026 (Meta v. Bright Data, X Corp v. Bright Data) posílila argumenty pro scraping veřejných dat, ale objevují se nová rizika kolem trénovacích dat pro AI, nároků z autorského práva a EU AI Act. Pravidla jednotlivých platforem se navíc výrazně liší — Google, Amazon, LinkedIn, Meta a X prosazují svá pravidla každý jinak — takže než začnete, poznejte prostředí.
Kdykoli si nejste jistí, vyhledejte právní radu — zejména u velkých nebo citlivých projektů. A pamatujte: právní prostředí se neustále mění, takže buďte informovaní a flexibilní.
Chcete se dozvědět víc o web scrapingu, compliance a automatizaci? Podívejte se na pro další průvodce, nebo si sami vyzkoušejte .
Často kladené dotazy
1. Je web scraping nezákonný všude?
Ne. Web scraping sám o sobě není nezákonný, ale jeho legálnost závisí na tom, co scrapujete, jak to scrapujete a kde se nacházíte. Scraping veřejných, neosobních dat pro interní použití je ve většině regionů obecně povolen, ale scraping osobních nebo chráněných dat, nebo porušení podmínek webu, může být nezákonný ().
2. Znamená robots.txt, že je scraping nezákonný, když ho ignoruji?
Robots.txt není právně závazný, ale je nejlepší praxe ho respektovat. Ignorování robots.txt vás samo o sobě k soudu nedostane, ale v případě sporu můžete působit jako „špatný aktér“ ().
3. Můžu scrapovat Google, Amazon nebo LinkedIn?
Je to složité. Všechny tři služby scraping ve svých ToS zakazují, ale soudy rozhodly, že ToS nemusí být závazné pro nepřihlášené uživatele (viz Meta v. Bright Data a X Corp v. Bright Data, obojí 2024). Scraping veřejně viditelných dat (ceny produktů, firemní záznamy, veřejné profily) je v USA obecně právně obhajitelný. Každá platforma ale svá pravidla vymáhá jinak: Amazon je v právních krocích nejagresivnější (v listopadu 2025 zažaloval Perplexity AI); LinkedIn spoléhá na technické bariéry a smluvní nároky; Google stále více využívá vymáhání přes DMCA. Scrapujte vždy zodpovědně a počítejte s technickými protiopatřeními.
4. Můžu scrapovat Facebook nebo Instagram?
Po Meta v. Bright Data (2024) je scraping veřejných dat z Facebooku a Instagramu bez přihlášení na silnější právní půdě. Soud rozhodl, že ToS společnosti Meta se na nepřihlášené uživatele nevztahují. Nikdy ale nevytvářejte falešné účty ani nescrapujte data za login wall — to už je za hranou.
5. Můžu scrapovat X (Twitter)?
X v roce 2023 aktualizoval ToS tak, aby zakazoval veškerý scraping bez písemného souhlasu, a nasadil agresivní technickou obranu (Cloudflare Turnstile, limity 300 požadavků za hodinu, hodnocení reputace IP). Bright Data však v podobném sporu uspěla — veřejná data scrapovaná bez účtu nejsou vázána ToS X. Technicky je ale X v roce 2026 jednou z nejtěžších platforem na scraping.
6. Je scraping dat pro trénování AI modelů legální?
To je v roce 2026 největší otevřená otázka. Hlavní žaloby (NYT v. OpenAI, narovnání Anthropic za 1,5 miliardy USD) ukazují na značné právní riziko. EU AI Act vyžaduje zveřejnění zdrojů trénovacích dat a respektování opt-outů z autorských práv. Navrhovaný AI Accountability for Publishers Act by vyžadoval souhlas i platbu. Pokud scrapujete pro trénování AI, než začnete, vyžádejte si právní radu.
7. Jaký je nejbezpečnější způsob používání nástrojů pro web scraping, jako je Thunderbit?
Držte se scrapování veřejných dat, respektujte podmínky webu, vyhýbejte se osobním údajům, pokud pro ně nemáte právní důvod, a používejte data interně. Thunderbit je navržen tak, aby vám pomohl zůstat v souladu s pravidly — scrapuje jen to, co vidíte v prohlížeči, a upozorňuje na rizikové weby ().
8. Můžu scrapovat data pro komerční použití?
Záleží na okolnostech. Použití scraped dat pro interní analytiku nebo výzkum je obecně bezpečnější. Znovupublikování nebo prodej scraped dat, zejména pokud jsou chráněná autorským právem nebo jde o osobní údaje, je mnohem rizikovější a může vyžadovat povolení nebo licenci.
9. Jak držet krok s právními a technickými změnami v web scrapingu?
Sledujte zprávy o technologickém právu, monitorujte své cílové weby kvůli změnám ToS nebo zásad a používejte nástroje jako Thunderbit, které pravidelně aktualizují šablony i compliance funkce. V roce 2026 sledujte hlavně: vymáhání EU AI Act (srpen), probíhající spory o autorská práva v AI a nové státní zákony o ochraně soukromí v USA. Když si nejste jistí, poraďte se s právníkem.