Yelp má napříč už — a dostat tahle data do použitelné podoby je dnes těžší než dřív. Tvrdý zásah Yelpu proti botům v letech 2024–2025 potichu rozbil většinu dosavadních Python návodů na scraping.
Pokud jste se v poslední době pokusili spustit Yelp scraper a narazili na zeď chyb 403, prázdných HTML odpovědí nebo CAPTCHA, které tam před půl rokem nebyly, není to jen váš pocit. Yelp dnes používá TLS/JA3 fingerprinting, rotující záměrně zamaskované CSS třídy a agresivní hodnocení reputace IP adres — takže starý přístup requests + BeautifulSoup, který pořád doporučuje každý druhý tutoriál, padne hned na první request. Strávil jsem týdny testováním různých postupů proti aktuální infrastruktuře Yelpu a tenhle průvodce pokrývá všechno, co v roce 2025 opravdu funguje: oficiální Fusion API (a proč samo o sobě pravděpodobně nestačí), kompletní Python workflow s vícevrstvou ochranou proti blokaci a také 2klikové no-code řešení s pro všechny, kdo chtějí data bez maratonu debugování.
Proč scrapovat Yelp v Pythonu a kdo z toho opravdu těží
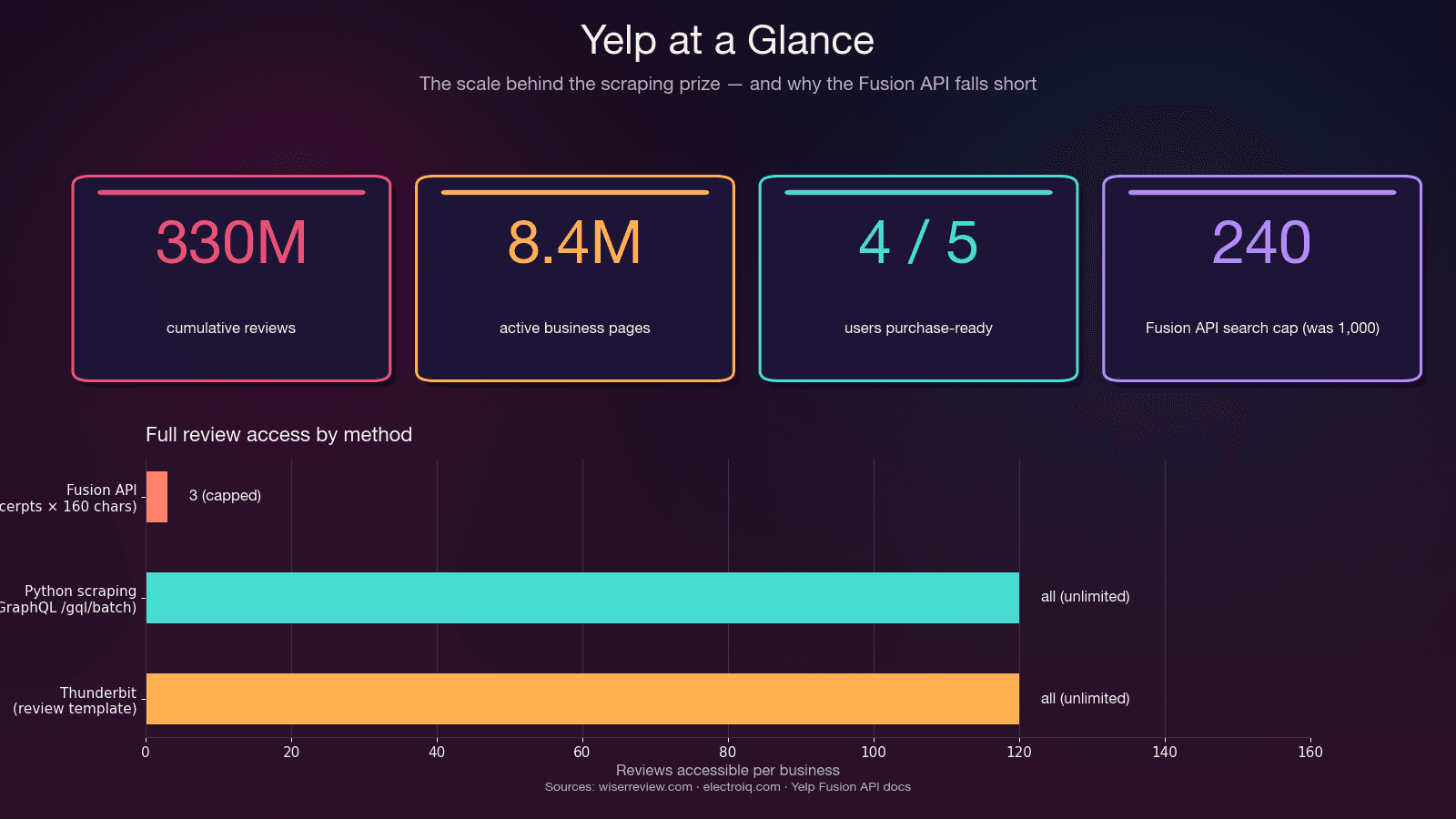
Než napíšete jediný řádek kódu, je dobré si ujasnit skutečný byznysový důvod. Yelp není jen recenzní web pro restaurace — je to v podstatě živá databáze místních firem se strukturovanými kontaktními údaji, hodnocením, kategoriemi, otevírací dobou a stovkami milionů zákaznických recenzí.
Nejvíc z toho těží tyto scénáře a datová pole:
| Případ použití | Klíčová data | Proč je to důležité |
|---|---|---|
| Prodej a lead generation | Název firmy, telefon, web, adresa, kategorie, hodnocení | Vytváření cílených seznamů lokálních SMB — 4 z 5 uživatelů Yelpu jsou připraveni nakupovat už při příchodu |
| Konkurence a intel | Recenze, hvězdičkové hodnocení, počet recenzí, sentiment | Sledování reputace konkurence, odhalování mezer ve službách, tracking trendů |
| Průzkum trhu a NLP | Plný text recenzí, data, metadata recenzentů | Sentiment analysis, topic modeling — recenze Yelpu patří mezi nejpoužívanější NLP korpusy ve výzkumu |
| Reality a výběr lokality | Hustota firem, mix kategorií, kvalita recenzí podle oblasti | Výběr lokality pro franšízy a retail — Yelp přesně pro to prodává Location Intelligence jako licencovaný B2B produkt |
| Ecommerce a provoz | Cenové signály, stížnosti zákazníků, provozní doba | Sledování, jak jsou konkurenti hodnoceni, a odhalování provozních vzorců |
Společný jmenovatel je jednoduchý: cílem jsou strukturovaná data a Python je jen jeden z prostředků, jak se k nim dostat. Někdo chce plnou programovou kontrolu. Jinému stačí tabulka s kontakty na instalatéry v Austinu. V tomhle článku najdete obě cesty.
Yelp Fusion API vs. Python web scraping: co je pro vás lepší?
Většina návodů tenhle krok úplně přeskočí a skočí rovnou do kódu, aniž by vůbec řešila, jestli by oficiální (dnes přejmenované na "Yelp Places API") nestačilo. Podle mých zkušeností právě tahle úvaha ušetří hodiny zbytečné práce — protože API je skvělé na některé úlohy, ale na jiné je naprosto nedostatečné.
Co Fusion API skutečně nabízí
Fusion API poskytuje strukturované vyhledávání firem, detaily firem, autocomplete a endpoint pro recenze. Je autorizované, dobře zdokumentované a nevyžaduje anti-bot obezličky.
Jenže právě u recenzního endpointu se to láme. Tohle potvrdili sami zaměstnanci Yelpu na GitHubu:
"Yelp API nevrací plný text recenzí. Ve výchozím stavu jsou k dispozici tři úryvky recenzí po 160 znacích." —
To není chyba — je to záměr. API je omezené na 3 úryvky recenzí (7 u Premium), každý přibližně na 160 znaků. Žádná metadata recenzí (užitečné/veselé/cool hlasy), žádná historie autora, žádné odpovědi provozovatele. A — z původních 5 000. Ceny začínají na .
Rozhodovací rámec
| Faktor | Yelp Fusion API | Python scraping | Thunderbit (no-code) |
|---|---|---|---|
| Plné recenze | ❌ Jen 3 úryvky (~160 znaků každý) | ✅ Všechny recenze přes GraphQL | ✅ Všechny viditelné recenze |
| Limity | 300–500/den (nové); 5 000 (legacy) | Pod vaší správou (rozpočet na proxy) | Na kredity |
| Náročnost nastavení | ~15 min (API klíč + SDK) | Hodiny až dny | ~2 minuty |
| Firemní pole | ~20 strukturovaných polí | Neomezeně (HTML/JSON parsing) | Pole navržená AI |
| Anti-bot ochrana | N/A (autorizované) | Musíte vyřešit sami | Řešeno automaticky |
| Právní riziko | ✅ Autorizované | ⚠️ Šedá zóna ToS | ⚠️ Stejné jako scraping |
| Cena | od $29/měsíc | Zdarma (+ proxy náklady $0.75–$4/GB) | K dispozici free tier |
| Údržba | Nízká (API stabilní) | Vysoká (selectors se rozbíjejí, anti-bot sílí) | Nízká (AI se přizpůsobí) |
Použijte Fusion API, pokud: potřebujete základní firemní údaje, malé množství dotazů nebo autorizovanou integraci — a stačí vám 3 úryvky recenzí na firmu.
Použijte Python scraping, pokud: potřebujete plný text recenzí, všechny recenze k dané firmě, metadata recenzí, více než 240 výsledků na vyhledávání nebo máte rozpočet pod $29/měsíc.
Použijte Thunderbit, pokud: chcete data rychle bez psaní a správy kódu. Více o tom v no-code části níže.
No-code zkratka: scrapeujte Yelp s Thunderbit (bez Pythonu)
Než se pustíme do Pythonu, tady je nejrychlejší cesta pro každého, jehož skutečným cílem jsou data, ne programování. Každý konkurenční článek předpokládá, že umíte Python, ale z mé práce v Thunderbit vím, že velká část lidí hledajících „scrape Yelp“ jsou obchodníci, operations manažeři a majitelé malých firem, kteří prostě chtějí tabulku místních podniků — ne kurz TLS fingerprintingu.
už má připravené Yelp šablony:
- — extrahuje název firmy, hodnocení, kontaktní údaje, adresu, otevírací dobu a kategorii
- — extrahuje uživatelské jméno recenzenta, obsah recenze, hodnocení, datum a lokaci recenzenta
Jak to funguje v praxi
- Otevřete stránku s výsledky hledání na Yelp nebo stránku konkrétní firmy v Chromu
- Klikněte na AI Suggest Fields v — AI si přečte stránku a navrhne sloupce (název firmy, hodnocení, počet recenzí, cenová úroveň, kategorie, adresa, telefon, URL)
- Klikněte na Scrape — hotovo
U předpřipravených Yelp šablon je to ještě jednodušší: otevřete šablonu a klikněte na Scrape.
Scraping podstránek zvládá enrichment automaticky — začnete na stránce výsledků Yelp, zapnete subpage scraping a Thunderbit postupně navštíví každou stránku firmy, aby vytáhl otevírací dobu, plné recenze, web, fotky i vybavení. Bez další konfigurace.
Stránkování je automatické — ať už jde o klikací nebo scrollovací variantu, vše funguje rovnou po instalaci. (Více o tom, jak to funguje, najdete v našem .)
Exporty jsou zdarma ve všech tarifech — Excel, Google Sheets, Airtable, Notion, CSV, JSON. Žádný pandas, žádný kód na zápis CSV.
Porovnání času
| Čas | Python scraper | Thunderbit |
|---|---|---|
| První spuštění | Hodiny až dny (selectors, stránkování, proxy, retry logika) | ~30 sekund s připravenou Yelp šablonou |
| Když Yelp změní markup | Ručně přepsat selektory | Znovu kliknout na AI Suggest Fields — automatická adaptace |
| Když vám zablokují IP | Debug, rotace proxy poolů, znovutestování | Cloud režim řeší rotaci IP za vás |
| Export do Google Sheets | Napsat OAuth + pandas propojení | Jedno kliknutí, zdarma |
Když Thunderbit vyzkoušíte nejdřív a zjistíte, že vám stačí, můžete zbytek článku přeskočit. Pokud potřebujete plnou programovou kontrolu, vlastní pole nebo škálování nad několik tisíc záznamů měsíčně — čtěte dál.
Python knihovny pro scraping Yelpu: kterou vybrat
"Mám použít Scrapy, BS4+requests, nebo Selenium?" je jedna z nejčastějších otázek v diskusích na r/webscraping kolem Yelpu. A přesto si každý tutoriál vybere svou oblíbenou knihovnu a jde dál, aniž by vysvětlil proč. Tady je poctivé rozebrání.
Realita roku 2025: requests + BeautifulSoup je na Yelp rozbitý
Stack, který doporučuje každý klasický návod na Yelp — pip install requests beautifulsoup4 — vás v roce 2025 zablokuje už při prvním requestu. Ne při padesátém. Při prvním.
Důvod: knihovna requests v Pythonu posílá TLS/JA3 fingerprint, který neodpovídá žádnému skutečnému prohlížeči. Yelpova anti-bot vrstva to odhalí už na úrovni TLS handshaku, ještě než se vůbec přečte User-Agent header. Testoval jsem to opakovaně — nová IP, realistické hlavičky, náhodné prodlevy — a stejně jsem hned dostal 403 Forbidden s obyčejným requests.
Matice rozhodnutí mezi knihovnami
| Knihovna | Nejlepší pro | Zvládá JS? | Anti-bot? | Náročnost učení | Rychlost |
|---|---|---|---|---|---|
requests + BeautifulSoup | ❌ | ❌ | Velmi nízká | Rychlá (dokud nejste zablokováni) | |
httpx async + parsel | Velkoplošný async scraping | ❌ | ❌ | Nízká | Velmi rychlá |
curl_cffi + parsel | Specificky pro Yelp: TLS impersonation | ❌ | ✅ TLS/JA3/HTTP2 | Nízká | Velmi rychlá |
Scrapy 2.14 | Kompletní crawl pipeline se stránkováním | Částečně (přes scrapy-playwright) | AutoThrottle, retry middleware | Střední až vysoká | Rychlá |
Selenium 4.43 / Playwright 1.58 | Stránky náročné na JS, obejití CAPTCHA | ✅ | Částečně | Střední | Pomalá (~10–30 stránek/min) |
| Thunderbit | Pro neprogramátory, rychlá extrakce | ✅ (v prohlížeči) | Vestavěné (Cloud režim) | Velmi nízká | Rychlá |
Zlomový objev: curl_cffi
Knihovna, která mi úplně změnila workflow pro scraping Yelpu, je — Python binding pro curl-impersonate. Vytváří naprosto stejný TLS/JA3 + HTTP/2 fingerprint jako skutečný Chrome, a její API je prakticky drop-in náhradou za requests:
1from curl_cffi import requests
2r = requests.get(
3 "https://www.yelp.com/biz/some-restaurant",
4 impersonate="chrome131",
5)
6print(r.status_code, len(r.text))Tahleta jediná změna — from curl_cffi import requests plus impersonate="chrome131" — obejde největší anti-bot vrstvu Yelpu . V mých testech je to rozdíl mezi okamžitou 403 a čistou odpovědí 200.
Doporučený stack pro Yelp v roce 2025: curl_cffi + parsel + jmespath + rezidenční proxy. Pokud potřebujete kompletní crawl pipeline se schedulingem, zabalte to do Scrapy 2.14 s downloader middleware postaveným na curl_cffi.
Nastavení Python prostředí pro scraping Yelpu
- Obtížnost: střední
- Časová náročnost: ~15 minut na setup, 1–2 hodiny na funkční scraper
- Co budete potřebovat: Python 3.10+ (doporučeno 3.12), terminál a volitelně poskytovatele rezidenčních proxy
Krok 1: Vytvořte virtuální prostředí a nainstalujte balíčky
1python3.12 -m venv .venv
2source .venv/bin/activate # Ve Windows: .venv\Scripts\activate
3pip install "curl_cffi>=0.11" "parsel>=1.9" "jmespath>=1.0" pandasCo jednotlivé balíčky dělají:
curl_cffi— posílá HTTP requesty s Chrome TLS fingerprintem (obejití anti-botu)parsel— CSS/XPath selektory pro parsing HTML (stejný engine jako Scrapy, ale lehčí)jmespath— deklarativní dotazování nad JSON (čistší než vnořené přístupy do dictů u embedded JSON od Yelpu)pandas— export dat do CSV/Excelu
Volitelné, ale užitečné:
1pip install fake-useragent # Pozn.: repozitář byl archivován v dubnu 2026, ale stále jde nainstalovatKrok za krokem: jak scrapovat Yelp v Pythonu
Tady začíná hlavní tutoriál. Klíčová myšlenka, která celé řešení dělá mnohem odolnějším: vynechte CSS selektory a vytahujte skrytý JSON. Yelp náhodně mění názvy CSS tříd při každém buildu (y-css-14xwok2 jeden týden, y-css-hcq7b9 další), takže scraper připoutaný k těmto selektorům se během pár týdnů rozpadne. Embedded JSON payloady — application/ld+json schema i react-root-props — jsou stabilní.
Krok 2: Scrapujte výsledky vyhledávání na Yelpu
URL výsledků hledání na Yelpu mají předvídatelný tvar: https://www.yelp.com/search?find_desc={term}&find_loc={location}. Data z výsledků jsou vložená v tagu <script data-id="react-root-props"> jako JSON — ne jako něco vykresleného v moři CSS tříd.
1import re, json, jmespath
2from curl_cffi import requests
3from parsel import Selector
4> This paragraph contains content that cannot be parsed and has been skipped.
5> This paragraph contains content that cannot be parsed and has been skipped.
6Měli byste dostat seznam dictů s názvy firem, URL, hodnocením a počtem recenzí. Pokud `react-root-props` v odpovědi chybí, dostali jste blokovací shell — otočte IP a zkuste to znovu.
7Header `Cookie: intl_splash=false` je běžný workaround pro country-splash redirect Yelpu. Bez něj neamerické IP adresy často narazí na splash stránku, která vypadá jako soft block, ale ve skutečnosti jím není.
8### Krok 3: Scrapujte stránky firem na Yelpu
9Každé URL firmy z výsledků vede na detailní stránku s bohatšími daty. Nejstabilnější cíl pro extrakci je blok `<script type="application/ld+json">` — obsahuje strukturovaná data schema.org, která Yelp drží kvůli SEO a neobfuská.
10```python
11def scrape_business(biz_url: str) -> dict:
12 url = f"https://www.yelp.com{biz_url}" if biz_url.startswith("/") else biz_url
13 r = requests.get(url, headers=HEADERS, impersonate="chrome131")
14 if r.status_code != 200:
15 return {"url": url, "error": r.status_code}
16 sel = Selector(text=r.text)
17 biz_id = sel.css('meta[name="yelp-biz-id"]::attr(content)').get()
18 for raw in sel.css('script[type="application/ld+json"]::text').getall():
19 try:
20 data = json.loads(raw)
21 except json.JSONDecodeError:
22 continue
23 for node in (data if isinstance(data, list) else [data]):
24 if node.get("@type") in (
25 "Restaurant", "LocalBusiness", "FoodEstablishment",
26 "HealthAndBeautyBusiness", "HomeAndConstructionBusiness",
27 ):
28 return {
29 "biz_id": biz_id,
30 "name": node.get("name"),
31 "rating": (node.get("aggregateRating") or {}).get("ratingValue"),
32 "review_count": (node.get("aggregateRating") or {}).get("reviewCount"),
33 "address": node.get("address"),
34 "telephone": node.get("telephone"),
35 "price_range": node.get("priceRange"),
36 "hours": node.get("openingHours"),
37 "url": url,
38 }
39 return {"biz_id": biz_id, "url": url}Hodnota meta[name="yelp-biz-id"] je zakódované ID firmy, které budete potřebovat pro endpoint s recenzemi. Získejte ji tady — v dalším kroku se vám bude hodit.
Krok 4: Scrapujte recenze Yelpu se stránkováním
Tady Fusion API zaostává a scraping naopak vyniká. Yelpův interní GraphQL batch endpoint vrací plný text recenzí, informace o recenzentech, data, hodnocení a počty hlasů — všechno, co API zadržuje.
Endpoint je https://www.yelp.com/gql/batch a používá statický documentId pro operaci GetBusinessReviewFeed. Stránkování funguje přes cursor zakódovaný v base64.
1import base64
2GQL_URL = "https://www.yelp.com/gql/batch"
3DOC_ID = "ef51f33d1b0eccc958dddbf6cde15739c48b34637a00ebe316441031d4bf7681"
4> This paragraph contains content that cannot be parsed and has been skipped.
5Každá stránka vrací 10 recenzí. Pro stránkování zvyšujte `offset` v base64 cursoru. Parametr `sortBy` přijímá `DATE_DESC` (nejnovější první), `RATING_ASC`, `RATING_DESC` a další.
6### Krok 5: Exportujte data z Yelpu
7```python
8import pandas as pd
9# Předpokládejme, že už máte businesses a reviews
10df_businesses = pd.DataFrame(businesses)
11df_businesses.to_csv("yelp_businesses.csv", index=False)
12df_reviews = pd.DataFrame(all_reviews)
13df_reviews.to_csv("yelp_reviews.csv", index=False)
14> This paragraph contains content that cannot be parsed and has been skipped.
15Pro čtenáře, kteří jdou no-code cestou, Thunderbit exportuje stejná data přímo do Excelu, Google Sheets, Airtable nebo Notion — bez pandas a bez kódu na zápis souborů.
16## Anti-blocking strategie: jak scrapovat Yelp bez blokace
17Tahle část je vlastně důvod, proč tenhle článek existuje. Ochrana Yelpu proti botům je od konce roku 2024 výrazně tvrdší — [TLS fingerprinting, kontrola reputace IP, CAPTCHA a behaviorální analýza](https://blog.apify.com/how-to-scrape-yelp/) jsou všechno součástí hry. Většina starších návodů je zastaralá, protože vznikla ještě před tímto zpřísněním.
18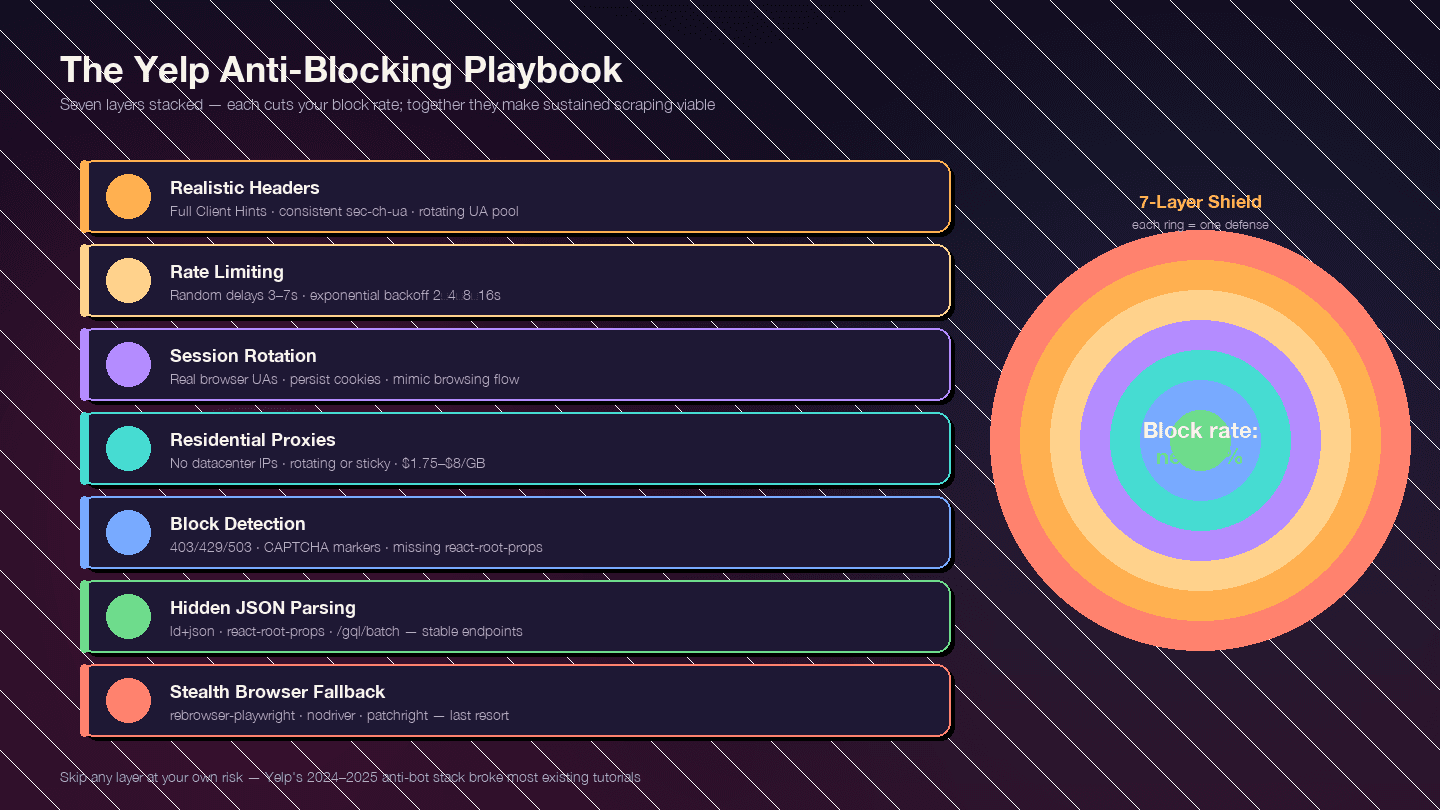
19Strategie je vrstvená. Každá vrstva snižuje míru blokací; dohromady z toho vznikne použitelný a dlouhodobě udržitelný scraping.
20### Vrstva 1: realistické request hlavičky
21Výchozí hlavičky Python `requests` posílají `User-Agent: python-requests/2.x` — a to je okamžitě blokované. Jenže ani realistický User-Agent sám o sobě nestačí. Yelp kontroluje celý set [Client Hints](https://scraperapi.com/web-scraping/yelp/) hlaviček a jejich konzistenci.
22```python
23FULL_HEADERS = {
24 "authority": "www.yelp.com",
25 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
26 "AppleWebKit/537.36 (KHTML, like Gecko) "
27 "Chrome/124.0.0.0 Safari/537.36",
28 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
29 "image/avif,image/webp,image/apng,*/*;q=0.8",
30 "accept-language": "en-US,en;q=0.9",
31 "accept-encoding": "gzip, deflate, br",
32 "sec-ch-ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
33 "sec-ch-ua-mobile": "?0",
34 "sec-ch-ua-platform": '"Windows"',
35 "sec-fetch-dest": "document",
36 "sec-fetch-mode": "navigate",
37 "sec-fetch-site": "same-origin",
38 "sec-fetch-user": "?1",
39 "upgrade-insecure-requests": "1",
40 "referer": "https://www.yelp.com/",
41 "cookie": "intl_splash=false",
42}Tři chyby, kvůli kterým vás systém označí:
- UA tvrdí, že jde o Chrome, ale
sec-ch-uachybí nebo odporuje verzi UA sec-ch-ua-platformříká "Windows", ale UA string uvádí macOS- Stejný User-Agent pro tisíce requestů z jedné IP — používejte pool 10–20 čerstvých Chrome/Firefox/Safari stringů
Vrstva 2: rate limiting a náhodné prodlevy
Předvídatelné časování je varovný signál. Přidejte náhodné pauzy a při chybách použijte exponenciální backoff.
1import random, time
2> This paragraph contains content that cannot be parsed and has been skipped.
3<Table content={`| **Parametr** | **Doporučená hodnota** |
4|---|---|
5| Náhodná pauza mezi requesty | \`random.uniform(3, 7)\` sekund |
6| Backoff při 429/403/503 | 2 → 4 → 8 → 16 s, max. 5 pokusů |
7| Současní workeři na jednu IP | 1 (serializovat na IP; pro paralelismus použít proxy) |
8| Maximální udržitelná rychlost na jednu rezidenční IP | ~1 request / 5 s (~12 rpm) |`} />
9### Vrstva 3: rotace User-Agentů a session
10Rotujte mezi sadou reálných browser User-Agentů. Udržujte sessions a cookies, aby to vypadalo jako skutečné prohlížení — Yelp využívá detekci přes cookies, takže vytvářet novou session pro každý request je samo o sobě podezřelé.
11```python
12UA_POOL = [
13 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
14 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
15 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:125.0) Gecko/20100101 Firefox/125.0",
16 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14.4; rv:125.0) Gecko/20100101 Firefox/125.0",
17 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/605.1.15 Safari/17.4.1",
18 # Přidejte dalších 5–10 aktuálních stringů
19]Vrstva 4: rotace proxy
Při jakémkoli reálném objemu potřebujete rezidenční proxy. Datacenter ani free proxy na Yelpu nefungují — IP reputační vrstva Yelpu preventivně vrací 403 pro rozsahy AWS, GCP a DigitalOcean.
| Poskytovatel | Startovní cena za GB | Poznámky |
|---|---|---|
| IPRoyal | $1.75/GB | Nejlevnější; provozuje nejcitovanější Yelp návod |
| Decodo (dříve Smartproxy) | $3.20–$3.50 | Nejlepší poměr GB/cena při vyšším objemu |
| Bright Data | $4.00 (PAYG) | Pool přes 150M IP; dedikovaná stránka pro Yelp proxy |
| Oxylabs | $6.00–$8.00 | Prémiové; 10M+ IP |
| Aluvia (mobile SIM) | $3.00 | Skutečné mobilní IP amerických operátorů, cílené na Yelp |
Rotující rezidenční proxy (nová IP pro každý request) fungují nejlépe pro velké crawly výsledků. Sticky sessions (jedna IP po dobu 10 minut) jsou lepší, když chcete zachovat cookies napříč flow stránka firmy → recenze → stránkování.
Vrstva 5: detekce a ošetření blokací
Ne každá blokace vypadá stejně. Yelp často podstrčí generický shell „page not available“ místo CAPTCHA, takže naivní scrapery si myslí, že dostaly data, i když ve skutečnosti dostaly prázdnou odpověď.
1BLOCK_MARKERS = (
2 "captcha", "px-captcha", "page not available",
3 "access denied", "unusual traffic",
4)
5def is_blocked(resp):
6 if resp.status_code in (401, 403, 429, 503):
7 return True
8 body = resp.text.lower()
9 if any(m in body for m in BLOCK_MARKERS):
10 return True
11 # Pokud jde o search/business page a chybí react-root-props,
12 # Yelp poslal ořezanou blokovací odpověď
13 if "react-root-props" not in body and "/biz/" in str(resp.url):
14 return True
15 return False| Signál | Význam |
|---|---|
| HTTP 403 | Tvrdý blok — IP/hlavičky/TLS jsou spálené |
| HTTP 429 | Rate limit — často se dá zachránit backoffem |
| HTTP 503 | Obecný blok nebo load shedding |
Redirect na /error nebo tělo „page not available“ | Soft block |
| Prázdný jen se | Challenge page čekající na JS |
captcha / g-recaptcha / px-captcha v těle | Eskalace — vyžaduje se CAPTCHA |
Chybějící react-root-props na listing page | Ořezaná blokovací odpověď |
Vrstva 6: odolný parsing — skrytý JSON místo CSS selektorů
Je dobré to zopakovat: Yelp náhodně mění názvy CSS tříd při každém buildu. Scraper připoutaný k h3.y-css-14xwok2 se rozbije během pár týdnů, jakmile Yelp nasadí h3.y-css-hcq7b9.
Payloady, které se nemění:
<script type="application/ld+json">— strukturovaná data schema.org (název, adresa, telefon, hodnocení, otevírací doba)<script data-id="react-root-props">— kompletní data výsledků vyhledávání jako JSONhttps://www.yelp.com/gql/batch— GraphQL endpoint pro recenze se stabilnímdocumentId
Pokud parsujete CSS třídy, stavíte na písku. Parsujte raději JSON.
Vrstva 7: fallback přes stealth browser
Na headless browser přepínejte jen tehdy, když curl_cffi + rezidenční proxy neprojdou — typicky když Yelp vrátí JavaScript challenge page nebo CAPTCHA.
Pro 95 % scraping úloh pro firmy / vyhledávání / recenze je curl_cffi + skrytý JSON + rezidenční proxy rychlejší, levnější a spolehlivější než browser. Ale když browser opravdu potřebujete:
This paragraph contains content that cannot be parsed and has been skipped.
Pro Yelp vynechte obyčejné Selenium. Je příliš snadno fingerprintovatelné.
Yelp Fusion API vs. Python scraping vs. Thunderbit: kompletní srovnání
| Dimenze | Yelp Fusion API | Python scraping | Thunderbit |
|---|---|---|---|
| Plný text recenzí | ❌ 3 úryvky × ~160 znaků | ✅ Neomezeně (GraphQL) | ✅ Vestavěná šablona pro recenze |
| Metadata recenzí (hlasy, odpovědi provozovatele) | ❌ | ✅ | ✅ Přes pole navržená AI |
| Fotky | ❌ (0 na Base) | ✅ Neomezeně | ✅ |
| Maximum výsledků na vyhledávání | 240 (před 2024 to bylo 1 000) | Neomezeně (s paginací) | Neomezeně |
| Denní limit | 300–500 (nové) / 5 000 (legacy) | Jen rozpočet na proxy | Na kredity (3 000/měsíc na Pro) |
| Náročnost nastavení | ~15 min | Hodiny až dny | ~2 minuty |
| Anti-bot ochrana | N/A | Váš problém | Řešeno (Cloud režim) |
| Právní riziko | Nízké (autorizované) | Střední (šedá zóna ToS) | Střední (stejné jako scraping) |
| Cena (start) | od $29/měsíc | ~ $0.75–$4/GB proxy + čas vývoje | Free tier |
| Cena při větším objemu | $643+/měsíc | $50–$500/měsíc za proxy + čas vývoje | $38–$49/měsíc |
| Export dat | JSON | CSV/JSON (musíte napsat sami) | Excel / Sheets / Airtable / Notion — zdarma |
| Údržba | Nízká | Vysoká (selectors se rozbíjejí, anti-bot sílí) | Nízká (AI se přizpůsobí) |
Právní a etické tipy pro scraping Yelpu
Nejsem právník a tohle není právní poradenství. Ale právní situace se za poslední dva roky změnila natolik, že byste měli znát základní rámec, než investujete čas do projektu na scraping Yelpu.
Co říkají podmínky Yelpu: výslovně zakazuje používat „jakéhokoli robota, pavouka... nebo jiné automatizované zařízení“ k „přístupu, získávání, kopírování, scrapování nebo indexování jakékoli části služby“. Přibylo také znění o „AI Technologies a/nebo jiných automatizovaných nástrojích“.
: „Yelp nepovoluje žádné scrapování svého webu.“
Co říká robots.txt: robots.txt Yelpu má wildcard User-agent: * / Disallow: / a výslovně blokuje GPTBot, ClaudeBot, PerplexityBot, CCBot a Meta-ExternalAgent. Povoleni jsou jen Googlebot, Bingbot a několik crawlerů sociálních sítí.
Relevantní právní precedens: V případu (N.D. Cal., leden 2024) soud rozhodl, že scraping veřejně dostupných dat bez přihlášení neporušuje podmínky Meta. Klíčové rozlišení je: veřejná data bez přihlášení vs. data po přihlášení. Případ ukázal, že scraping veřejných dat pravděpodobně neporušuje CFAA, ale hiQ přesto prohrál na státních deliktech (trespass to chattels, misappropriation) a dostal rozsudek na $500 000.
Praktická doporučení:
- Scrapujte jen veřejně dostupné stránky bez přihlášení
- Omezujte tempo requestů (prodlevy v tomhle návodu zároveň fungují jako etické rate limity)
- Nepřeprodávejte syrové texty recenzí připsané konkrétním uživatelům — respektujte soukromí recenzentů
- Dodržujte místní zákony o ochraně dat (CCPA, GDPR)
- Nepřihlašujte se kvůli scrapingu — to už překračuje hranici autorizace
- Informace o firmě (název/adresa/telefon/hodnocení) berte jako veřejná faktická data; text recenzí jako citlivější obsah
Pro konkrétní situaci se poraďte s právníkem.
Závěr
Tři cesty, jeden cíl.
Yelp Fusion API je autorizovaná a nenáročná varianta — ale končí na 3 úryvcích recenzí a začíná na $29 měsíčně. Python scraping vám dá plnou kontrolu nad každým datovým bodem na Yelpu, ale vyžaduje reálnou investici: curl_cffi pro TLS impersonation, rezidenční proxy, náhodné prodlevy, parsing skrytého JSON a průběžnou údržbu, jakmile se obrana Yelpu dál vyvíjí. Thunderbit vás dostane od „potřebuji data z Yelpu“ k „tady je moje tabulka“ zhruba za 30 sekund, bez kódu a bez nastavování proxy.
Anti-blocking postupy, které v roce 2025 skutečně fungují: realistické hlavičky s plným Client Hints, curl_cffi pro impersonaci TLS fingerprintu, náhodné prodlevy s exponenciálním backoffem, rotace rezidenčních proxy a — hlavně — parsování skrytého JSON (application/ld+json a react-root-props) místo křehkých CSS selektorů.
Nevíte, která cesta je pro vás? Nejprve zkuste . Pokud vám stačí, ušetřili jste si hodiny práce. Pokud potřebujete víc kontroly — plné programové pipeline, vlastní pole, úzkou integraci s CRM — výše uvedený Python návod vám pokryje záda. A pokud chcete hlubší pohled na krajinu scraping nástrojů, podívejte se na náš přehled nebo na průvodce .
Často kladené otázky
Dá se Yelp zdarma scrapovat v Pythonu?
Ano — pomocí bezplatných knihoven jako curl_cffi, parsel a jmespath. Ale při větším objemu (víc než pár desítek stránek) budete potřebovat placené rezidenční proxy, které začínají zhruba na . Thunderbit navíc nabízí free tier s 6 stránkami měsíčně pro rychlou no-code extrakci.
Blokuje Yelp scrapery?
Ano, a dost agresivně. Yelp používá . Obyčejný requests je blokovaný hned na první pokus. Vrstvená anti-blocking strategie z tohohle průvodce — curl_cffi pro TLS impersonation, realistické hlavičky, náhodné prodlevy a rezidenční proxy — je to, co v roce 2025 funguje.
Je Yelp Fusion API lepší než scraping?
Záleží na vašich potřebách. API je autorizované a s nižším rizikem, ale vrací jen , omezuje výsledky hledání na 240 a začíná na $29 měsíčně. Pokud potřebujete plný text recenzí, metadata recenzí nebo víc než pár stovek záznamů denně, scraping je jediná cesta.
Jak scrapovat recenze z Yelpu v Pythonu?
Použijte curl_cffi s impersonate="chrome131" pro načtení stránky firmy, z <meta name="yelp-biz-id"> vytáhněte zakódované ID firmy a pak pošlete POST na https://www.yelp.com/gql/batch s operací GetBusinessReviewFeed a stránkujte přes base64-enkódovaný after cursor. Krok za krokem kód je v tutoriálu výše. Dobrou referencí je také .
Dá se Yelp scrapovat i bez kódování?
Ano — má předpřipravené šablony pro i . Otevřete stránku Yelpu, klikněte na AI Suggest Fields a potom na Scrape. Export do Google Sheets, Excelu, Airtable a Notion je zdarma ve všech tarifech, včetně free plánu.
Více informací