Většina návodů na scrapování eBay má životnost zhruba tři měsíce. Vím to, protože náš tým v Thunderbit sledoval, jak se vývojáři pořád vracejí k rozbitým ukázkám kódu, zastaralým CSS selektorům a „funkčním“ GitHub repozitářům, které přestaly fungovat už dvě redesignové verze eBay nazpět.
eBay provozuje — po Amazonu jde o největší veřejně dostupný dataset dlouhého chvostu cen na otevřeném webu. Tahle data pohánějí všechno od cenotvorby pro překupníky až po konkurenční intelligence. Dostávat se k nim programově je ale neustále se měnící cíl: rozhraní eBay postavené na Reactu mění názvy CSS tříd, A/B testy servírují různým uživatelům odlišné DOM struktury a mezi vámi a HTML stojí Akamai Bot Manager. Tenhle průvodce vám dá Python kód, který funguje dnes, vysvětlí, proč scrapery selhávají, abyste je mohli stavět odolněji, poctivě porovná eBay API vs. scraping a ukáže i bezkódovou únikovou cestu pro chvíle, kdy Python za nastavení prostě nestojí.
Co znamená scrapovat eBay pomocí Pythonu?
Scrapování eBay v Pythonu znamená psát skripty, které programově stahují webové stránky eBay, parsují HTML (nebo skrytý JSON) a vytahují z nich strukturovaná data — názvy, ceny, informace o prodejci, data prodeje, varianty — do formátu, se kterým se dá opravdu pracovat, třeba CSV, tabulky nebo databáze.
Scrapovat můžete několik typů stránek eBay:
- Výsledky vyhledávání (např. všechny nabídky „AirPods Pro“)
- Stránky jednotlivých produktů (kompletní specifikace, obrázky, informace o prodejci)
- Prodáno / dokončené nabídky (skutečné transakční ceny a data)
- Profily prodejců a recenze
Python je pro tenhle úkol oblíbená volba. Jeho ekosystém — Requests, BeautifulSoup, lxml, pandas — usnadňuje stahování stránek, parsování HTML i práci s daty. Zásadní rozdíl ale je mezi scrapováním HTML webu a použitím oficiálního eBay API — k tomu se dostanu hned za chvíli.
Proč scrapovat eBay? Reálné firemní scénáře použití
Pokud tohle čtete, pravděpodobně už svůj důvod máte. Přesto je dobré ukotvit debatu v konkrétní byznysové hodnotě, protože návratnost dat z eBay je opravdu působivá. Bain zjistil, že napříč tisíci firmami. McKinsey přisuzuje dynamické cenotvorbě v retailu .
Nejčastější scénáře použití, se kterými se setkávám:
| Případ použití | Potřebná data | Byznysový výsledek |
|---|---|---|
| Monitoring cen a přeceňování | Ceny aktivních nabídek, doprava, stav | Konkurenční cenotvorba, ochrana marže |
| Analýza konkurence | Sortiment produktů, akce, podmínky dopravy | Strategické pozicování, odhalení mezer v nabídce |
| Průzkum trhu a sledování trendů | Rychlost přibývání inzerátů, trendy v kategoriích, vzorce poptávky | Identifikace nových produktů, predikce poptávky |
| Cenotvorba pro překupníky / odhady | Prodejní ceny, data prodeje, stav | Odhad férové tržní hodnoty, rozhodování o nákupu |
| Sentiment analýza | Recenze, hodnocení, pravidla vrácení | Náhled na kvalitu produktu, spokojenost zákazníků |
| Generování leadů | Profily prodejců, informace o obchodu, kontaktní údaje | B2B oslovování prodejců s vysokým GMV |
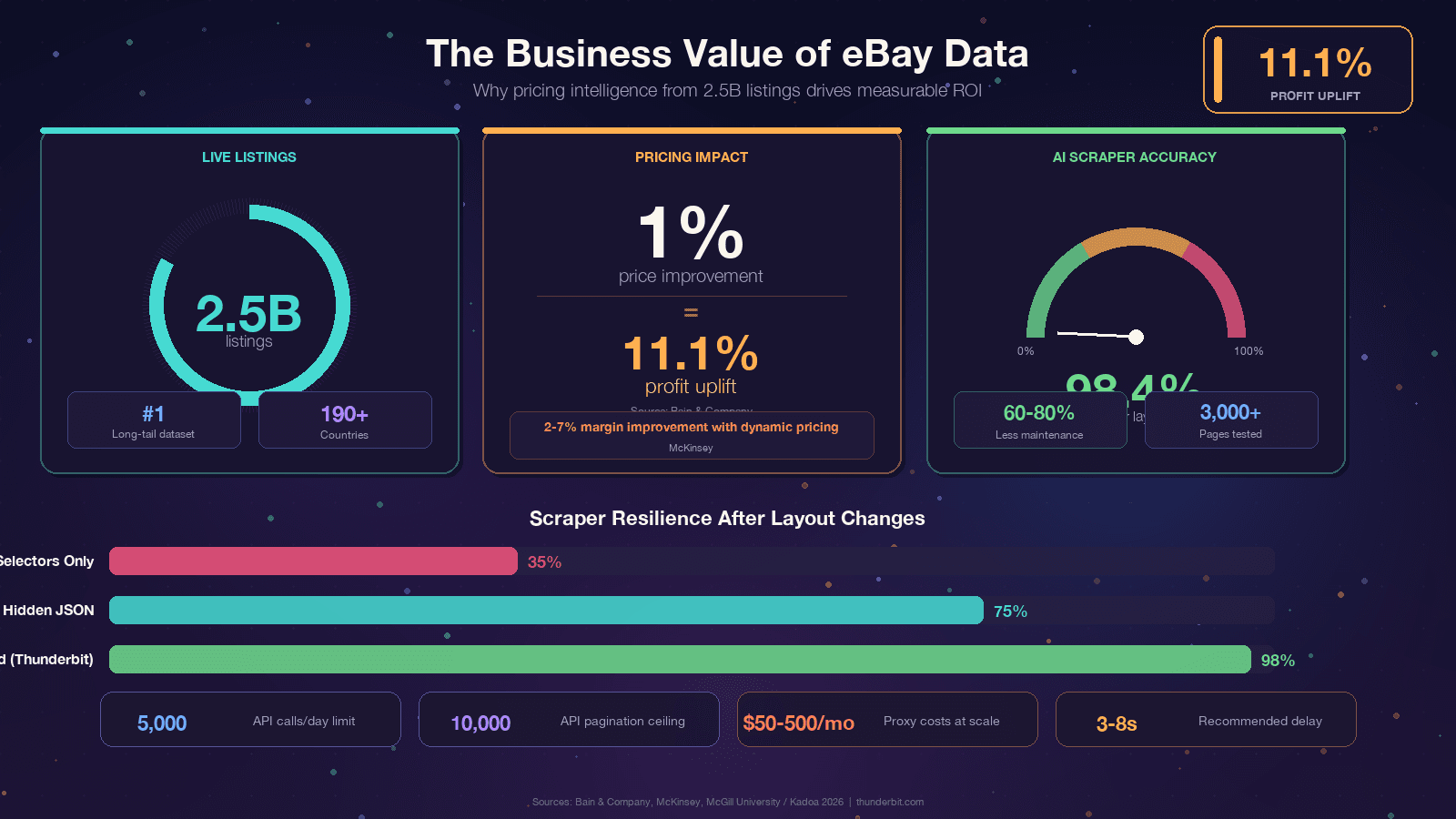
Společný jmenovatel: eBay ta data má, ale jsou uzamčená ve webových stránkách.
Scraping je způsob, jak z nich udělat konkurenční výhodu.
Oficiální eBay API vs. Python scraping: co zvolit?
Tohle je otázka, na kterou bych si přál, aby více návodů odpovídalo naprosto otevřeně. eBay nabízí oficiální API — hlavně — a mnoho uživatelů přemýšlí, jestli použít právě je, nebo jít cestou scrapingu. Odpověď závisí čistě na tom, jaká data potřebujete.
| Kritérium | eBay Browse/Finding API | Python scraping |
|---|---|---|
| Prodáno / dokončené nabídky | Omezené — existuje Marketplace Insights API, ale přístup bývá často zamítán | Plný přístup přes URL parametry LH_Sold=1&LH_Complete=1 |
| Rate limit | 5 000 volání/den v základní vrstvě | Spravujete sami (závisí na proxy) |
| Datová pole | Předem definovaná (název, cena, kategorie, základní údaje o prodejci) | Cokoliv viditelného na stránce (recenze, kompletní specifikace, variace) |
| Složitost nastavení | OAuth 2.0, registrace aplikace, API klíče | pip install + kód |
| Stabilita | Stabilní endpointy | Padá, když se změní HTML |
| Cena | K dispozici je free tier, vyšší objem je placený | Kód zdarma, ale ve větším měřítku stojí proxy |
| Data o variantách/MSKU | Částečně — často jen parent SKU | Plně (přes parsování skrytého JSON) |
| Hloubka stránkování | Tvrdý limit 10 000 položek | Teoreticky neomezené |
Krátká poznámka: staré Finding API (které mělo findCompletedItems) bylo . Pokud používáte ebaysdk-python nebo jinou knihovnu, která sahá na Finding modul, je v produkci momentálně nefunkční.
Mé doporučení: Používejte Browse API pro stabilní, středně objemové a strukturované dotazy na aktivní nabídky. Python scraping použijte tehdy, když potřebujete prodané ceny, recenze, data o variantách nebo jakékoli pole, které API neposkytuje. Mnoho týmů používá obojí.
Nástroje a knihovny, které budete potřebovat pro scrapování eBay v Pythonu
Než napíšeme kód, tady je základní výbava. Pro většinu stránek eBay nepotřebujete headless browser — data jsou vložená v serverem renderovaném HTML.
| Knihovna | Účel |
|---|---|
requests nebo httpx | HTTP klient pro stahování stránek eBay |
curl_cffi | HTTP klient s TLS otiskem skutečného prohlížeče (zásadní pro obejití Akamai) |
beautifulsoup4 | HTML parser pro extrakci přes CSS selektory |
lxml | Rychlý parser backend pro BeautifulSoup |
jmespath | Dotazovací jazyk pro parsování vnořených JSON blobů |
pandas | Práce s daty a export do CSV/Excelu |
gspread | Integrace s Google Sheets |
Nainstalujte všechno jedním příkazem:
1pip install requests httpx curl_cffi beautifulsoup4 lxml jmespath pandas gspreadPoužívejte Python 3.11+ — pandas 3.0 vyžaduje 3.10+ a 3.11 vám dá 10–60% rychlostní zlepšení u I/O zátěže.
Jedna knihovna si zaslouží zvláštní zmínku: curl_cffi je zdaleka největší upgrade, který může mít eBay scraper v roce 2026. eBay používá a hlavní detekční metoda Akamai je TLS fingerprinting. Běžný requests posílá otisk vypadající „pythonově“ jako JA3, který je okamžitě označen. curl_cffi napodobuje TLS handshake skutečného Chromu a pokryje zhruba 90 % cílových stránek chráněných Akamai bez nutnosti headless browseru.
Krok za krokem: jak scrapovat výsledky vyhledávání eBay pomocí Pythonu
Tohle je hlavní tutoriál. Budeme scrapovat stránky s výsledky vyhledávání eBay pro produktové nabídky.
- Obtížnost: Začátečník až středně pokročilý
- Časová náročnost: přibližně 30 minut do prvního funkčního scrapu
- Co budete potřebovat: Python 3.11+, výše uvedené knihovny, terminál a cílovou URL vyhledávání na eBay
Krok 1: Nastavení Python projektu
Vytvořte adresář projektu a nainstalujte závislosti:
1mkdir ebay-scraper && cd ebay-scraper
2python -m venv venv
3source venv/bin/activate # Windows: venv\Scripts\activate
4pip install requests curl_cffi beautifulsoup4 lxml pandasVytvořte soubor scrape_ebay.py. To bude vaše pracovní plocha.
Krok 2: Sestavení URL pro vyhledávání na eBay
Struktura vyhledávací URL na eBay je jednoduchá. Klíčový parametr je _nkw (keyword):
1import urllib.parse
2keyword = "airpods pro"
3base_url = "https://www.ebay.com/sch/i.html"
4params = {
5 "_nkw": keyword,
6 "_ipg": "120", # položek na stránku: 60, 120 nebo 240 (240 může spustit bot ochranu)
7 "_pgn": "1", # číslo stránky
8}
9url = f"{base_url}?{urllib.parse.urlencode(params)}"
10print(url)
11# https://www.ebay.com/sch/i.html?_nkw=airpods+pro&_ipg=120&_pgn=1Další užitečné parametry:
LH_BIN=1— pouze Buy It Now_sacat=175673— konkrétní kategorie_sop=12— řazení podle nejlepší shody (10 = nejnižší cena+doprava, 13 = nově přidané)LH_Complete=1&LH_Sold=1— prodané/dokončené nabídky (podrobně v samostatné části níže)
Krok 3: Odeslání požadavku a zpracování odpovědi
Tady se curl_cffi vyplatí. Prostý requests.get() často vrátí 403 z Akamai. S curl_cffi se vydáváme za skutečný Chrome browser:
1from curl_cffi import requests as cffi_requests
2import random, time
3USER_AGENTS = [
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
5 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (X11; Linux x86_64; rv:124.0) Gecko/20100101 Firefox/124.0",
7]
8HEADERS = {
9 "User-Agent": random.choice(USER_AGENTS),
10 "Accept-Language": "en-US,en;q=0.9",
11 "Accept-Encoding": "gzip, deflate, br",
12}
13def fetch_page(url, max_retries=5):
14 delay = 2
15 for attempt in range(max_retries):
16 try:
17 r = cffi_requests.get(url, impersonate="chrome124", headers=HEADERS, timeout=30)
18 if r.status_code == 200:
19 return r.text
20 if r.status_code in (403, 429, 503):
21 retry_after = r.headers.get("Retry-After")
22 sleep_for = float(retry_after) if retry_after else delay + random.uniform(0, 1)
23 print(f" Status {r.status_code}, retrying in {sleep_for:.1f}s...")
24 time.sleep(sleep_for)
25 delay *= 2
26 continue
27 r.raise_for_status()
28 except Exception as e:
29 print(f" Request error: {e}, retrying...")
30 time.sleep(delay)
31 delay *= 2
32 raise RuntimeError(f"Failed after {max_retries} retries: {url}")Exponenciální backoff s jitterem je důležitý — pevné intervaly spánku jsou samy o sobě bot otisk.
Krok 4: Parsování produktových nabídek z výsledkové stránky
eBay je momentálně uprostřed migrace mezi dvěma layouty výsledků vyhledávání. Odolný scraper musí zvládnout oba:
| Pole | Starý layout | Nový layout |
|---|---|---|
| Karta | li.s-item | li.s-card nebo div.su-card-container |
| Název | .s-item__title | .s-card__title |
| URL | a.s-item__link[href] | a.su-link[href] |
| Cena | span.s-item__price | .s-card__price |
Parsení, které zvládne oba layouty:
1from bs4 import BeautifulSoup
2def parse_search_results(html):
3 soup = BeautifulSoup(html, "lxml")
4 cards = soup.select("li.s-item, li.s-card, div.su-card-container")
5 results = []
6 for card in cards:
7 # Název — zkusíme oba layouty
8 title_el = card.select_one(".s-item__title, .s-card__title")
9 title = title_el.get_text(strip=True) if title_el else None
10 # Přeskočit falešnou placeholder kartu "Shop on eBay"
11 if not title or "Shop on eBay" in title:
12 continue
13 # Cena
14 price_el = card.select_one("span.s-item__price, .s-card__price")
15 price = price_el.get_text(strip=True) if price_el else None
16 # URL
17 link_el = card.select_one("a.s-item__link[href], a.su-link[href]")
18 url = link_el["href"].split("?")[0] if link_el else None
19 # Obrázek
20 img_el = card.select_one("img.s-item__image-img, .s-card__image img")
21 image = None
22 if img_el:
23 image = img_el.get("src") or img_el.get("data-src")
24 # Doprava
25 ship_el = card.select_one("span.s-item__shipping, span.s-item__logisticsCost, .s-card__attribute-row")
26 shipping = ship_el.get_text(strip=True) if ship_el else None
27 results.append({
28 "title": title,
29 "price": price,
30 "url": url,
31 "image": image,
32 "shipping": shipping,
33 })
34 return resultsTen první falešný card placeholder je klasická past. První li.s-item na mnoha stránkách eBay je skrytý zástupný prvek s názvem „Shop on eBay“ a bez skutečné ceny. Vždy ho odfiltrujte.
Krok 5: Zpracování stránkování pro scrapování více stránek
eBay stránkuje přes parametr _pgn. Odkaz na další stránku používá a.pagination__next:
1import urllib.parse
2def scrape_ebay_search(keyword, max_pages=5):
3 all_results = []
4 for page_num in range(1, max_pages + 1):
5 params = {"_nkw": keyword, "_ipg": "120", "_pgn": str(page_num)}
6 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
7 print(f"Scraping page {page_num}: {url}")
8 html = fetch_page(url)
9 results = parse_search_results(html)
10 if not results:
11 print(f" No results on page {page_num}, stopping.")
12 break
13 all_results.extend(results)
14 print(f" Found {len(results)} listings (total: {len(all_results)})")
15 # Slušná prodleva — 3 až 8 sekund s jitterem
16 time.sleep(random.uniform(3, 8))
17 return all_resultsNáhodný jitter 3–8 sekund není volitelný.
eBay vrstva Akamai označuje trvalé požadavky nad 1 req/s z jedné IP jako podezřelé.
Krok 6: Export scrapaných dat do CSV nebo JSON
1import pandas as pd
2results = scrape_ebay_search("airpods pro", max_pages=3)
3df = pd.DataFrame(results)
4df.to_csv("ebay_airpods.csv", index=False)
5df.to_json("ebay_airpods.json", orient="records", indent=2)
6print(f"Exportováno {len(df)} nabídek do CSV a JSON.")Teď byste měli mít čistou tabulku eBay nabídek. Na mém stroji scraping 3 stránek (360 nabídek) trval asi 45 sekund včetně pauz.
Jak scrapovat detailní stránky produktů eBay pomocí Pythonu
Výsledky vyhledávání vám dají přehled. Detailní stránka produktu obsahuje to nejzajímavější: plný popis, hodnocení prodejce, specifikace položky, galerii obrázků a data o variantách.
Parsování stránky jednoho produktu
Stránky položek eBay žijí na /itm/<ITEM_ID>. Nejspolehlivější cesta extrakce je JSON-LD — eBay vkládá blok schématu Product, který přežije téměř všechny CSS přesuny:
1import json
2def parse_item_page(html):
3 soup = BeautifulSoup(html, "lxml")
4 item = {}
5 # 1. JSON-LD — nejstabilnější cesta extrakce
6 for tag in soup.find_all("script", type="application/ld+json"):
7 try:
8 data = json.loads(tag.string or "")
9 except (json.JSONDecodeError, TypeError):
10 continue
11 if isinstance(data, dict) and data.get("@type") == "Product":
12 item["title"] = data.get("name")
13 item["brand"] = (data.get("brand") or {}).get("name")
14 item["images"] = data.get("image")
15 offers = data.get("offers") or {}
16 item["price"] = offers.get("price")
17 item["currency"] = offers.get("priceCurrency")
18 break
19 # 2. CSS fallbacky pro pole, která nejsou v JSON-LD
20 def first_text(selectors):
21 for sel in selectors:
22 el = soup.select_one(sel)
23 if el and el.get_text(strip=True):
24 return el.get_text(strip=True)
25 return None
26 item.setdefault("title", first_text([
27 "h1.x-item-title__mainTitle",
28 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
29 ]))
30 item["condition"] = first_text([
31 ".x-item-condition-text .ux-textspans",
32 ])
33 item["seller"] = first_text([
34 ".x-sellercard-atf__info__about-seller a .ux-textspans",
35 ])
36 item["shipping"] = first_text([
37 "div.ux-labels-values--shipping .ux-textspans--BOLD",
38 ])
39 # 3. Specifikace položky
40 specifics = {}
41 for dl in soup.select(".ux-layout-section-evo__item--table-view dl.ux-labels-values"):
42 k = dl.select_one(".ux-labels-values__labels-content .ux-textspans")
43 v = dl.select_one(".ux-labels-values__values-content .ux-textspans")
44 if k and v:
45 specifics[k.get_text(strip=True).rstrip(":")] = v.get_text(strip=True)
46 item["specifics"] = specifics
47 return itemTady je klíčový vzorec — nejdřív JSON-LD, pak CSS fallbacky — pro stavbu scraperů, které se nerozsypou každé čtvrtletí. O tom víc níže.
Scrapování variant produktů eBay (data MSKU)
Některé nabídky eBay mají více variant — různé barvy, velikosti, kapacity úložiště. Viditelné DOM často ukazuje jen cenové rozpětí jako „899 až 1 099 dolarů“, dokud uživatel neklikne na konkrétní možnost. Skutečná cena za variantu je uložená ve skrytém JavaScript objektu nazvaném MSKU.
To je jedna z oblastí, kde eBay API poskytuje jen částečná data (parent SKU), takže je scraping lepší volbou.
1import re, json
2def extract_variants(html):
3 # Nechcete chamtivý match — přesně proto je non-greedy důležitý
4 m = re.search(r'"MSKU"\s*:\s*(\{.+?\})\s*,\s*"QUANTITY"', html, re.DOTALL)
5 if not m:
6 return []
7 try:
8 msku = json.loads(m.group(1))
9 except json.JSONDecodeError:
10 return []
11 item_labels = {str(k): v["displayLabel"] for k, v in msku.get("menuItemMap", {}).items()}
12 skus = []
13 for combo_key, variation_id in msku.get("variationCombinations", {}).items():
14 option_ids = combo_key.split("_")
15 options = [item_labels.get(oid, oid) for oid in option_ids]
16 var = msku.get("variationsMap", {}).get(str(variation_id), {})
17 bin_model = var.get("binModel", {})
18 price_spans = bin_model.get("price", {}).get("textSpans", [{}])
19 price = price_spans[0].get("text") if price_spans else None
20 qty = var.get("quantity")
21 skus.append({
22 "options": options,
23 "price": price,
24 "quantity_available": qty,
25 "variation_id": variation_id,
26 })
27 return skusTen non-greedy (.+?) v regulárním výrazu je přesně místo, kde se každý eBay scraper snadno zasekne. Chamtivé .+ spolkne všechno až po poslední "QUANTITY" na stránce a vytvoří nevalidní JSON. Tenhle bug jsem viděl alespoň ve třech „funkčních“ tutoriálech.
Jak scrapovat prodané a dokončené nabídky eBay pomocí Pythonu
Tohle je use case, který scraping obhajuje proti API. Data o prodaných položkách — co se skutečně prodalo, za jakou cenu a kdy — jsou zlatý standard pro průzkum trhu, cenotvorbu pro překupníky i oceňování. eBay Browse API to výslovně nenabízí. to sice technicky umí, ale přístup je v režimu „Limited Release“ a .
Potřebujete parametry URL LH_Complete=1 (dokončené nabídky) a LH_Sold=1 (omezit jen na skutečně prodané). Musíte použít oba. Samotné LH_Sold=1 se v některých kategoriích potichu vrátí k aktivním nabídkám — to je nejčastější past komunity.
1def scrape_sold_listings(keyword, max_pages=3):
2 all_sold = []
3 for page_num in range(1, max_pages + 1):
4 params = {
5 "_nkw": keyword,
6 "_ipg": "120",
7 "_pgn": str(page_num),
8 "LH_Complete": "1",
9 "LH_Sold": "1",
10 }
11 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
12 print(f"Scraping prodané stránky {page_num}...")
13 html = fetch_page(url)
14 soup = BeautifulSoup(html, "lxml")
15 cards = soup.select("li.s-item")
16 for card in cards:
17 title_el = card.select_one(".s-item__title")
18 title = title_el.get_text(strip=True) if title_el else None
19 if not title or "Shop on eBay" in title:
20 continue
21 # Zahrnout pouze opravdu prodané položky (zelený wrapper POSITIVE)
22 sold_tag = card.select_one(
23 ".s-item__title--tag .POSITIVE, .s-item__caption--signal.POSITIVE"
24 )
25 if sold_tag is None:
26 continue # Neprodaná dokončená nabídka — přeskočit
27 price_el = card.select_one("span.s-item__price")
28 price = price_el.get_text(strip=True) if price_el else None
29 # Parsování data prodeje
30 sold_date = None
31 import re, datetime as dt
32 card_text = card.get_text()
33 m = re.search(r"Sold\s+([A-Z][a-z]{2}\s+\d{1,2},\s*\d{4})", card_text)
34 if m:
35 sold_date = dt.datetime.strptime(m.group(1), "%b %d, %Y").strftime("%Y-%m-%d")
36 link_el = card.select_one("a.s-item__link[href]")
37 url = link_el["href"].split("?")[0] if link_el else None
38 all_sold.append({
39 "title": title,
40 "sold_price": price,
41 "sold_date": sold_date,
42 "url": url,
43 })
44 if not cards:
45 break
46 time.sleep(random.uniform(3, 8))
47 return all_soldKlíčový rozdíl v HTML: prodané položky ukazují cenu zeleně (uvnitř wrapperu .POSITIVE), zatímco neprodané dokončené nabídky mají cenu červeně přeškrtnutou. Vždy filtrujte podle třídy .POSITIVE.
Proč eBay scrapery padají (a jak stavět odolné)
Pokud vám eBay scraper přestal fungovat, nejste sami. To je v každém fóru o scrapování eBay téma číslo jedna. Otázka není jestli váš scraper spadne — ale kdy.
Proč se to děje:
- eBay používá renderování založené na Reactu s dynamicky generovanými názvy tříd, které se mění při nasazení
- A/B testy servírují různým uživatelům různé DOM struktury (dvojitý layout
s-item/s-cardje zrovna teď živý příklad) - Pravidelné redesigny webu mění vnoření HTML, i když data zůstávají stejná
- Staré selektory jako
#itemTitlea#prcIsumbyly odstraněny už před lety, ale v návodech se pořád objevují
Jak : „Skutečnou výzvou při scrapování eBay je zvládnout změny CSS selektorů. eBay pravidelně aktualizuje frontend, čímž rozbíjí scrapery, které spoléhají na konkrétní názvy tříd.“
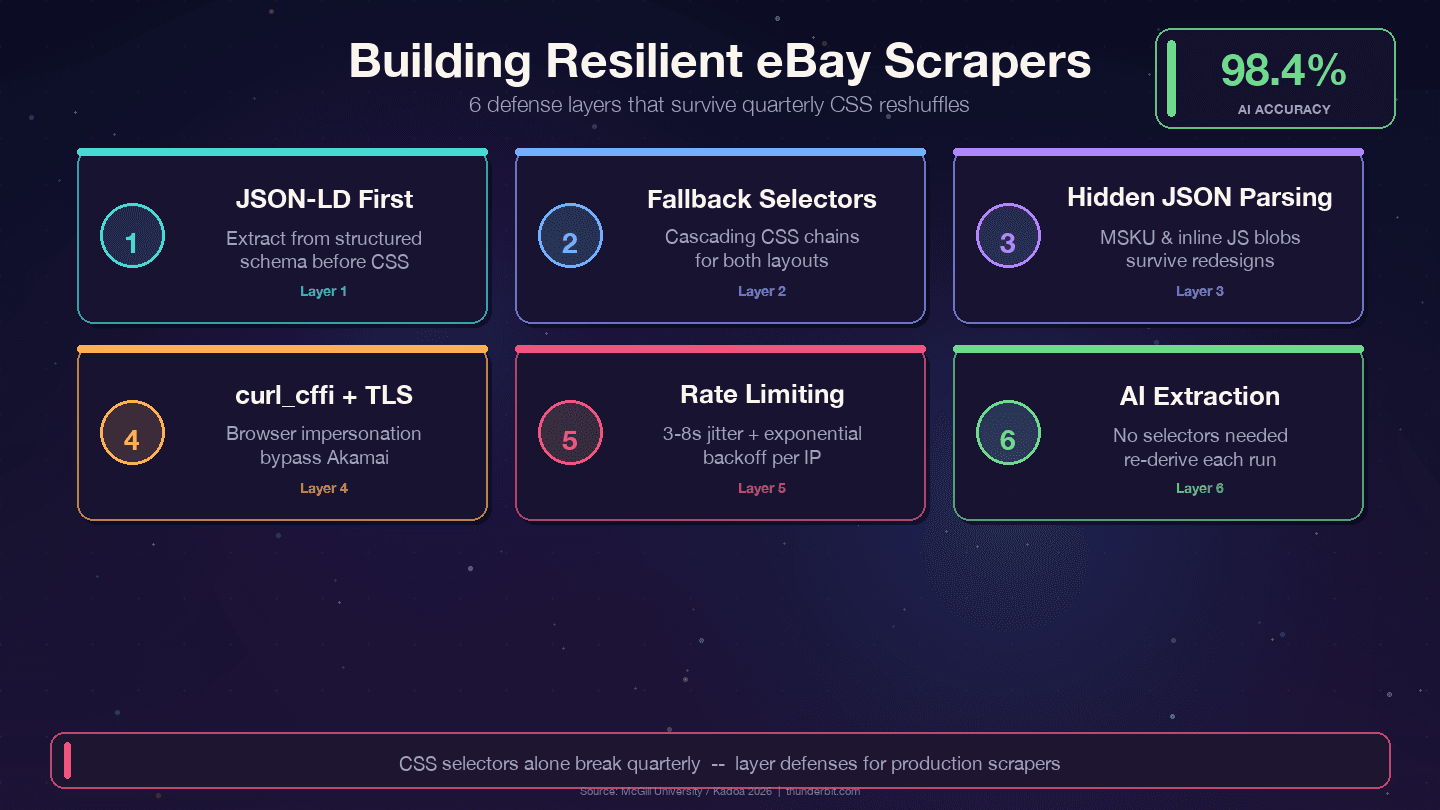
Obranné strategie pro dlouhověké eBay scrapery
Čtyři strategie, které přežijí čtvrtletní přestavby eBay:
1. Upřednostněte JSON-LD před CSS selektory. eBay vkládá na každou stránku položky strukturovaná data schématu Product. Datová vrstva se mění mnohem méně než prezentační vrstva — designéři refaktorují CSS třídy každé čtvrtletí, ale backendové názvy polí jako price, name a seller napojené na interní API se přejmenovávají zřídka.
2. Používejte kaskádové fallback selektory. Nikdy nespoléhejte na jediný CSS selektor. Vždy mějte alternativy:
1def first_text(soup, selectors):
2 for sel in selectors:
3 el = soup.select_one(sel)
4 if el and el.get_text(strip=True):
5 return el.get_text(strip=True)
6 return None
7title = first_text(soup, [
8 "h1.x-item-title__mainTitle",
9 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
10 "[data-testid='x-item-title'] h1",
11])3. Parsujte skryté JSON blob soubory. MSKU objekt pro varianty a inline JavaScript data přežívají CSS změny, protože jsou generované serverem. Extrakce přes regex z <script> tagů je sice na začátku víc práce, ale výrazně snižuje údržbu.
4. Logujte selhání selektorů. Přidejte monitoring, abyste věděli kdy selektor přestal fungovat, ne jen to, že výstup je prázdný:
1if title is None:
2 print(f"WARNING: selector pro název selhal pro {url}")5. Používejte curl_cffi s impersonací prohlížeče. To obchází TLS fingerprinting od Akamai bez potřeby headless browseru.
AI alternativa: žádná údržba selektorů
Pokud vás nebaví každých pár měsíců opravovat selektory, existuje zásadně jiný přístup. Nástroje jako používají AI, která si stránku při každém načtení „přečte“ znovu a dynamicky odvodí logiku extrakce. Studie McGill University testovala AI vs. selector-based scrapery na 3 000 stránkách a zjistila, že , přičemž průmyslové benchmarky uvádějí .
| Přístup | Spadne, když eBay změní HTML? | Náročnost údržby |
|---|---|---|
| Natvrdo napsané CSS selektory | Ano, každé čtvrtletí | Vysoká — průběžné opravy |
| Extrakce skrytého JSON / JSON-LD | Zřídka | Nízká |
| AI scrapování (Thunderbit) | Ne — AI při každém běhu znovu odvodí selektory | Žádná |
Pracovní postup v Thunderbitu rozeberu detailněji později. Prozatím si odnesete toto: pokud stavíte scraper, který má běžet měsíce, vyplatí se investovat do extrakce nejdřív z JSONu a až potom do fallback selektorů. Pokud nechcete selektory udržovat vůbec, AI přístup stojí za vyzkoušení.
Automatizace opakovaného scrapování eBay pro monitoring cen
Jednorázový scraping je užitečný. Ale monitoring cen, sledování zásob a analýza konkurence vyžadují pravidelné sběry dat. Každý konkurenční článek, který jsem četl, uvádí cenový monitoring jako use case, ale téměř žádný neukazuje, jak ho opravdu automatizovat.
Varianta 1: Cron joby (Linux/macOS) nebo Task Scheduler (Windows)
Nejjednodušší přístup. Zabalte Python skript do cron jobu. Vždy používejte absolutní cestu k Pythonu z vašeho venv — cron běží v minimalistickém prostředí:
1crontab -e
2# Denně v 08:15
315 8 * * * /Users/me/ebay/venv/bin/python /Users/me/ebay/scrape_ebay.py >> /Users/me/ebay/scrape.log 2>&1Na Windows použijte PowerShell:
1$A = New-ScheduledTaskAction -Execute "C:\Users\me\ebay\venv\Scripts\python.exe" -Argument "C:\Users\me\ebay\scrape_ebay.py"
2$T = New-ScheduledTaskTrigger -Daily -At 8:15am
3Register-ScheduledTask -TaskName "eBayScraper" -Action $A -Trigger $TTo vyžaduje stroj, který běží pořád, a proxy i anti-bot opatření si spravujete sami.
Varianta 2: Cloud Functions (serverless)
AWS Lambda nebo Google Cloud Functions umožňují spouštět scrapery bez dedikovaného serveru. Vyšší náročnost nastavení — musíte zabalit závislosti, řešit timeouty (Lambda má limit 15 minut) a stejně spravovat proxy. Ale bez údržby serveru.
Varianta 3: Bezkódové plánování s Thunderbit
Funkce Scheduled Scraper vám dovolí popsat interval běhu normální řečí (např. „každý den v 8 ráno“), vložit URL eBay a kliknout na Schedule. Běží to v cloudu s vestavěným anti-bot handlingem.
| Přístup | Náročnost nastavení | Vyžaduje server? | Zvládá anti-bot ochranu? |
|---|---|---|---|
| Cron + Python skript | Střední | Ano (stroj běžící pořád) | Proxy řešíte sami |
| Cloud function (Lambda) | Vysoká | Ne (serverless) | Proxy řešíte sami |
| Thunderbit Scheduled Scraper | Nízká (popíšete slovy) | Ne (v cloudu) | Vestavěné |
Pro ukládání dat z pravidelných scrapů je pro historii cen správná volba lokální SQLite databáze. Použijte ON CONFLICT ... DO UPDATE (ne INSERT OR REPLACE, které ):
1CREATE TABLE IF NOT EXISTS listings (
2 item_id TEXT PRIMARY KEY,
3 title TEXT NOT NULL,
4 price REAL,
5 last_price REAL,
6 first_seen_at TEXT DEFAULT (datetime('now')),
7 last_seen_at TEXT DEFAULT (datetime('now'))
8);
9CREATE TABLE IF NOT EXISTS price_history (
10 item_id TEXT NOT NULL,
11 observed_at TEXT NOT NULL DEFAULT (datetime('now')),
12 price REAL NOT NULL,
13 PRIMARY KEY (item_id, observed_at)
14);Nechcete programovat? Jak scrapovat eBay za 2 minuty s Thunderbit
Už jsem věnoval 2 000 slov Python kódu. Teď chci být upřímný ohledně toho, kdy ho vůbec nepotřebujete.
Jestli jste byznys uživatel, který dělá jednorázový průzkum trhu, překupník kontrolující srovnatelné nabídky nebo ecommerce tým, který potřebuje data dnes bez vývojářského sprintu, je Python přestřelený. Nastavení, údržba selektorů, správa proxy — to je hodně režie na „já jen potřebuju těchto 200 nabídek do tabulky“.
Jak Thunderbit scrapuje eBay (krok za krokem)
- Nainstalujte — bez nutnosti platební karty.
- Otevřete v Chrome libovolné výsledky vyhledávání na eBay nebo stránku produktu.
- Klikněte na „AI Suggest Fields“ v bočním panelu Thunderbitu. AI přečte stránku a navrhne sloupce: Title, Price, Condition, Shipping, Seller, Rating.
- Klikněte na „Scrape“. Rozšíření projde stránkování a naplní datovou tabulku. Pro eBay má Thunderbit , které fungují jedním kliknutím.
- Exportujte do Google Sheets, Airtable, Notion, CSV, JSON nebo Excelu — zdarma.
Celý proces zabere méně než 2 minuty.
Měřil jsem to.
Obohacení podstránek: získejte data z detailu bez dalšího kódu
Po seškrábání stránky s výsledky vyhledávání může Thunderbit navštívit detail každé nabídky a přidat další pole — kompletní specifikace, informace o prodejci, popis, všechny obrázky. Tím se nahradí těch 20+ řádků Python kódu pro scrapování podstránek, které jsme psali výše, jediným kliknutím.
Kdy má pořád smysl použít Python
Python vyhrává, když potřebujete:
- Scraping ve velkém měřítku (desítky tisíc stránek na běh)
- Silně přizpůsobenou logiku parsování nebo transformaci dat
- Integraci do existujících datových pipeline (Airflow, dbt, Kafka)
- Jemné řízení TLS/session pro pokročilý anti-bot handling
- Jednotkovou ekonomiku — u milionů řádků vyhrává udržovaný stack nad SaaS kredity
Pro většinu jednorázových nebo středně velkých projektů je Thunderbit rychlejší a jednodušší. Pro produkční pipeline ve větším rozsahu vám Python dá úplnou kontrolu.
Tipy, jak se nenechat zablokovat při scrapování eBay pomocí Pythonu
eBay vrstva Akamai je reálná. Co v praxi opravdu funguje:
- Používejte
curl_cffisimpersonate="chrome124"— to je největší zlepšení oproti běžnémurequests - Rotujte User-Agent řetězce ze seznamu aktuálních verzí prohlížečů (Chrome 143, Firefox 124, Safari 26)
- Přidávejte náhodné prodlevy — pevné intervaly jsou fingerprint
- Používejte rezidenční nebo rotující proxy pro cokoliv nad několik desítek stránek. Datacentrové IP adresy (AWS, GCP, DigitalOcean) Akamai rychle označí.
- Respektujte
robots.txt— většina filtrovaných browse URL je výslovně zakázaná; detailní stránky položek (/itm/<id>) ne - S CAPTCHA si poraďte elegantně — detekujte ji a zkuste to z jiné IP, nebo použijte službu na řešení CAPTCHA
- Nesekejte server bez rozmyslu. Precedens říká, že trespass to chattels se uplatní, když scraping skutečně degraduje servery. Držet se na 1 req/s na IP vás od téhle hranice drží daleko.
Pro komerční použití ve větším objemu zvažte Browse API pro aktivní nabídky a cílený scraping jen pro prodané srovnatelné položky a data, která API neukazuje. Tenhle hybridní přístup je technicky i právně čistší.
Je scrapování eBay pomocí Pythonu legální?
Nejsem právník a tenhle článek není právní rada. Takže budu stručný.
Právní prostředí se posunulo ve prospěch scrapování veřejně dostupných dat. Klíčové precedenty:
- (9. obvod, 2022): scrapování veřejně dostupných dat neporušuje CFAA
- Van Buren v. United States (Nejvyšší soud USA, 2021): omezil výklad ustanovení CFAA o „překročení oprávněného přístupu“
- (N.D. Cal., 2024): scraping bez přihlášení neporušuje podmínky platformy, protože scraper není „uživatel“
To ale neznamená, že je vše dovoleno. eBay ve své výslovně zakazuje „buy-for-me agenty, LLM řízené boty nebo jakýkoli end-to-end tok, který se snaží odeslat objednávky bez lidské kontroly“. Hranice je jasná: pouze čtecí scraping veřejných stránek je na solidní půdě; automatizace checkoutu ne.
Doporučená praxe: scrapujte jen veřejně viditelná data. Nevytvářejte falešné účty ani neobcházejte přihlašovací bariéry. Nepřeposílejte hromadně chráněné obrázky z inzerátů. A u komerčních projektů konzultujte právníka.
Závěr a hlavní poznatky
Python je nejflexibilnější způsob, jak scrapovat eBay, ale vyžaduje průběžnou údržbu, protože HTML webu se mění. Rozhodovací rámec:
- Použijte eBay Browse API pro stabilní, středně objemové a strukturované dotazy na aktivní nabídky
- Použijte Python scraping pro prodané nabídky, recenze, data o variantách a vše, co API nezpřístupňuje
- Použijte , pokud chcete data z eBay bez psaní nebo údržby kódu
Kód v tomto průvodci staví na odolnosti: nejdřív extrakce z JSON-LD, potom kaskádové CSS fallbacky, pro varianty parsování skrytého JSON. Tahle vrstvená strategie znamená, že váš scraper nezemře při příštím redesignu frontendu eBay.
Pokud chcete vyzkoušet bezkódovou cestu, vám umožní otestovat to na eBay stránkách hned teď. A pokud chcete vidět, jak funguje , stačí jedno kliknutí.
Více o nástrojích pro web scraping najdete v našich průvodcích: , a . Můžete se také podívat na tutoriály na .
Časté dotazy
1. Můžu eBay scrapovat v Pythonu zdarma?
Ano. Všechny knihovny (Requests, BeautifulSoup, curl_cffi, pandas) jsou zdarma a open source. Náklady přicházejí ve větším měřítku — rezidenční proxy pro vysoký objem scrapingu obvykle stojí 50–500 USD měsíčně podle šířky pásma. U malých projektů (několik stovek stránek) můžete při opatrném rate limitingu scrapovat i ze své domácí IP.
2. Jak scrapovat prodané položky a dokončené nabídky eBay v Pythonu?
Přidejte do parametrů vyhledávací URL LH_Complete=1&LH_Sold=1. Musíte použít oba — samotné LH_Sold=1 se v některých kategoriích potichu vrátí k aktivním nabídkám. Výsledky filtrujte kontrolou CSS třídy .POSITIVE na cenovém elementu, která značí skutečný prodej, ne pouze vypršelou neprodanou nabídku.
3. Blokuje eBay web scraping?
eBay používá Akamai Bot Manager, který scrapery detekuje hlavně přes TLS fingerprinting a behaviorální analýzu. Běžné requests volání často končí odpovědí 403. Použití curl_cffi s impersonací prohlížeče, rotací User-Agentů a náhodnými prodlevami 3–8 sekund mezi požadavky zvládne většinu blokací. Ve větším měřítku pomáhají rezidenční proxy.
4. Mám použít eBay API, nebo scraping?
Použijte Browse API pro stabilní dotazy středního objemu na aktivní nabídky (až 5 000 volání/den). Scraping použijte tehdy, když potřebujete historii prodaných cen, úplná data o variantách/MSKU, recenze nebo jakékoli pole, které API nezpřístupňuje. Marketplace Insights API sice technicky poskytuje data o prodejích, ale přístup je omezený a .
5. Jaký je nejjednodušší způsob, jak scrapovat eBay bez programování?
používá AI ke čtení stránek eBay, navrhuje datové sloupce a jedním kliknutím vytahuje nabídky. Zvládá stránkování, obohacení podstránek i export do Google Sheets, Excelu, Airtable nebo Notionu. Předpřipravené to ještě zrychlí pro běžné scénáře.
Více informací