
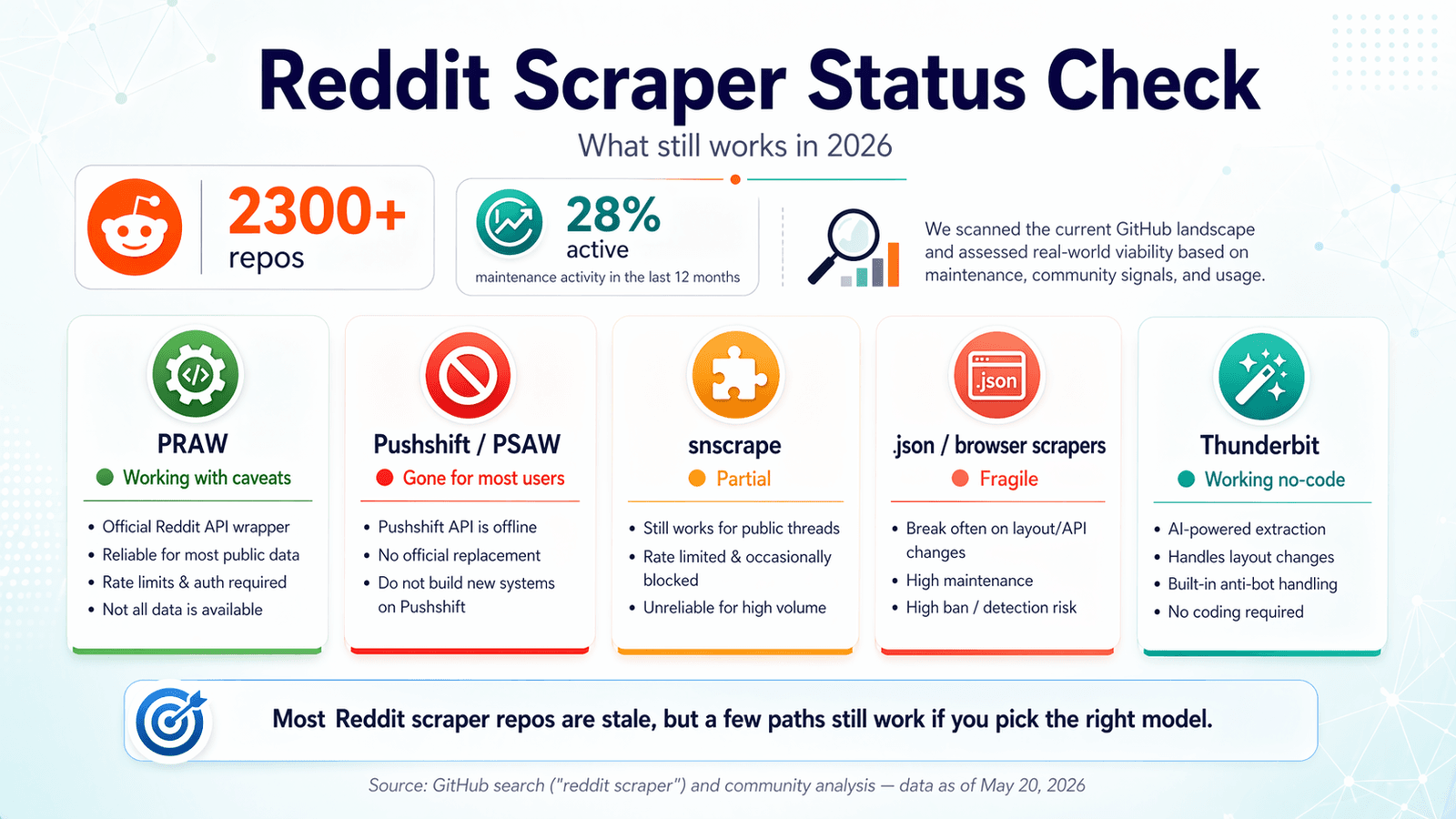
GitHub právě nabízí přes . Zní to jako bufet. Háček? Jen asi 28 % z nich vykazuje za posledních dvanáct měsíců nějakou aktivitu údržby. Posledních pár týdnů jsem strávil procházením těchto repozitářů, testováním endpointů, čtením front issue a porovnáváním s vlastními aktualizacemi pravidel Redditu. Cíl: ušetřit vám klonování repa, zápas s OAuth a zjištění o půlnoci, že to celé nenápadně přestalo fungovat už v roce 2024. Scéna „Reddit scraper GitHub“ je v roce 2026 pohřebištěm dobrých úmyslů, v němž se sem tam najde i pár opravdu užitečných nástrojů. Tenhle průvodce pokrývá, co ještě funguje, co se rozbilo, kdy přeskočit kód úplně a jak zůstat na správné straně stále přísnějšího vymáhání pravidel Redditu. Pokud hledáte zkratku, je no-code varianta, kterou jsme pro přesně tento typ problému postavili — ale budu upřímný i v tom, kde stále dávají větší smysl řešení založená na kódu.
Co je repozitář „Reddit Scraper GitHub“ (a proč je jich tolik rozbitých)
Repozitář typu „reddit scraper github“ je obvykle open-source projekt v Pythonu (nebo někdy JavaScriptu), který automatizuje stahování příspěvků, komentářů, uživatelských dat nebo médií z Redditu. Obvykle spadá do čtyř kategorií:
- API wrappery (například PRAW): používají oficiální API Redditu, vyžadují OAuth a řídí se pravidly Redditu.
- Nástroje založené na Pushshift/PSAW: dříve se napojovaly na obrovský archiv Redditu v Pushshiftu pro historická data.
- Scrapery veřejného
.jsonendpointu: přidávají k URL Redditu.jsonnebo volají veřejné endpointy bez autentizace. - Scrapery založené na prohlížeči: používají Playwright, Selenium nebo rozšíření do prohlížeče k načtení stránek Redditu a extrakci vykresleného obsahu.
Proč se jich tolik rozbilo? Ze tří důvodů.
- Reddit v polovině roku 2023 zásadně změnil cenovou politiku API. Bezplatné limity API klesly na . Vyšší komerční využití nyní stojí 0,24 USD za 1 000 API volání. Mnoho repozitářů vzniklo ve světě, kde byl přístup k API prakticky neomezený — a ten svět je pryč.
- Veřejný přístup k Pushshiftu byl odebrán. Pushshift byl páteří historického výzkumu Redditu. Jakmile ho Reddit omezil, velká část repozitářů pro „historický scraping“ přišla o hlavní zdroj dat. Některé README pořád dělají dojem, že nástroje žijí dál, ale závislost pod nimi už pro běžné uživatele neexistuje.
- Reddit zpřísnil pravidla i jejich vymáhání. Aktualizace robots.txt z roku 2024, z roku 2025 a z března 2026 jasně ukazují, že Reddit už dávkové scrapování nevnímá jako neškodný vedlejší provoz. Dokonce .
Závěr: když vyhledáte „reddit scraper github“, dostanete stovky výsledků. Data posledního commitu a počty otevřených issue ale vyprávějí úplně jiný příběh.
Kontrola stavu Reddit Scraper GitHubu v roce 2026: Co ještě funguje
Většina srovnávacích článků vznikla v roce 2023 nebo 2024 a už se nikdy neaktualizovala. Uživatelé na fórech pořád narážejí na chyby v repozitářích, které fungovaly před rokem — jedna prosba typu „Pořád narážím na chybu limitace Reddit API: \ Nějaký nápad, jak to obejít?“ je v podstatě esencí zkušenosti s Reddit scraperem v roce 2026.
Provedl jsem kontrolu čerstvosti, stav ověřený k dubnu 2026. Tady je, co jsem zjistil.
PRAW: Oficiální Python wrapper
Stav: ✅ Stále funguje, ale s výhradami.
(Python Reddit API Wrapper) zůstává nejspolehlivějším open-source základem pro scraping Redditu. Je aktivně udržovaný — 4 099 hvězdiček, poslední push 20. dubna 2026, jen 6 otevřených issue a (vydáno v říjnu 2024).
Silné stránky: Oficiální, dobře zdokumentovaný, abstrahuje většinu složitosti API Redditu.
Omezení v roce 2026:
- Přísnější požadavky na OAuth. Potřebujete registrovanou aplikaci Redditu se schváleným popisem použití.
- Nižší rate limity od roku 2024 (100 dotazů/min s OAuth, 10 bez něj).
- Přetrvává tvrdý limit kolem 1 000 příspěvků na výpis. Komunitní vlákna na r/redditdev i Stack Overflow potvrzují: na jeden listing endpoint.
PRAW je nejbezpečnější volba, pokud se vejdete do rámce API.
Jen už to není volný bulk scraper jako dřív.
Pokud chcete praktický postup pro oficiální API cestu, tenhle tutoriál se k této části hodí:
Pushshift / PSAW: Archiv, který potemněl
Stav: ❌ Veřejný přístup zmizel.
byl dlouho oblíbený Python wrapper pro Pushshift, což bývala nejjednodušší cesta k historickým datům Redditu. V roce 2026 je repozitář archivovaný, README doslova říká „THIS REPOSITORY IS STALE“ a mezi nedávnými otevřenými issue najdete perly jako „Pushshift.io UNABLE to connect“ a „The code not working. Possibly due to pushshift api.“
Akademický přístup možná stále existuje přes specifické kanály, ale pro kohokoli, kdo dnes hledá „reddit scraper github“, není Pushshift/PSAW použitelná možnost. Pokud potřebujete hluboká historická data z Redditu, musíte se podívat na schválený akademický přístup k datům nebo na licencované cesty.
snscrape (Reddit modul): Částečné a nespolehlivé
Stav: ⚠️ Částečný — občasné selhávání, z velké části bez údržby.
má 5 337 hvězdiček, ale poslední push proběhl 15. listopadu 2023. README stále tvrdí, že scraping Redditu je podporován „via Pushshift“. Otevřená issue kolem Redditu zahrnují „Error reddit scraping“ a „Reddit scraper returns no submissions before 2022-11-03“, bez jakékoli nedávné smysluplné opravy.
V některých prostředích může fungovat pro malé jednorázové stahování, ale pro produkci nebo pravidelné scrape je nespolehlivý. Berte ho jako legacy řešení.
Playwright a scrapery veřejného .json endpointu: Obejít to jde (někdy)
Stav: ✅ Funguje, ale je křehké.
Princip je jednoduchý: použijete headless prohlížeč (Playwright, Puppeteer) k načtení stránek Redditu a scrapujete vykreslený obsah, nebo k URL Redditu přidáte .json, abyste získali strukturovaná data bez oficiálního API.
Silné stránky: Nepotřebujete API klíč, můžete obejít limit 1k příspěvků, získáte vykreslený obsah.
Slabé stránky: Rozbije se, když Reddit změní rozložení front-endu nebo strukturu JSONu, může spustit anti-bot ochrany a vyžaduje techničtější nastavení. Při mém letošním testování vracely přímé požadavky na veřejné Reddit .json endpointy odpovědi 403. To neznamená, že bude blokován každý prostředí, ale znamená to, že na zkratku .json už se nedá spoléhat jako na něco, co „prostě funguje“.
Repozitáře jako jsou v tomhle až osvěžujícím způsobem upřímné: README varuje uživatele, aby nástroj používali „s rotujícími proxy, jinak vám Reddit může nadělit IP ban.“ To je v podstatě příběh dubna 2026 v jedné větě.
Pokud hodnotíte cestu přes browser automation jako workaround, tenhle tutoriál k Playwrightu je silný doplněk k části níže:
Thunderbit: Scrapování v prohlížeči s AI (bez kódu, bez API klíče)
Stav: ✅ Funguje — automaticky se přizpůsobuje změnám na stránce.
volí úplně jiný přístup. Jde o , která pomocí AI čte stránky Redditu, navrhuje datová pole (název příspěvku, autor, upvoty, časová značka, URL atd.) a ve dvou kliknutích extrahuje strukturovaná data. Žádné nastavování OAuth, žádná registrace API klíče, žádné Python prostředí, žádná správa závislostí. AI stránku při každém spuštění znovu přečte, takže když Reddit změní rozvržení, Thunderbit se přizpůsobí automaticky místo tichého selhání.
Export zdarma do CSV, Google Sheets, Airtable nebo Notion. Zvládá stránkování i scraping podstránek (například nejdřív vytáhne seznam v subredditu a pak navštíví každý příspěvek kvůli komentářům). Pro publikum, které chce data z Redditu bez údržby GitHub repozitáře, je to nejméně bolestivá cesta.
(Pro úplnost: Thunderbit jsme postavili my, takže jsem zaujatý — ale v článku budu dál jasně říkat, kde dávají řešení s kódem pořád větší smysl.)
Přehled stavu vedle sebe
| Nástroj / kategorie | Pořád funguje (duben 2026)? | Vyžaduje API klíč? | Poznámky |
|---|---|---|---|
| PRAW | ✅ Ano, s výhradami | Ano (OAuth) | Nejlépe udržovaný open-source základ. Omezený rate limity a limitem 1k příspěvků. |
| Pushshift / PSAW | ❌ Ne (pro většinu uživatelů) | N/A | Veřejný přístup zmizel. Repozitář je archivován. |
| snscrape (Reddit modul) | ⚠️ Částečně / nespolehlivé | Ne | Stále dokumentuje Reddit „via Pushshift“. Údržba se zastavila v roce 2023. |
| scrapery .json / veřejných endpointů | ⚠️ Částečně | Ne | Může fungovat, ale přímé požadavky jsou čím dál častěji blokovány. Závisí na proxy. |
| Playwright / browser scrapery | ✅ Ano, ale křehké | Obvykle ne | Nejpoužitelnější DIY workaround bez API. Pořád záleží na změnách stránky a anti-bot kontrolách. |
| Thunderbit | ✅ Ano | Ne | AI/browser workflow. Žádné OAuth, žádné selektory. Nejlepší volba pro neprogramátory. |
Rate limity, limit 1k příspěvků a co skutečně pomáhá
Tohle je největší bolest pro každého, kdo používá projekt typu reddit scraper github. Fóra jsou plná frustrace: „unavený z toho, že běhy umírají v polovině kvůli rate limitům“, „Proč dostávám jen asi 1 000 položek?“ Dvě hlavní omezení jsou rate limity API Redditu (počet požadavků za minutu) a limit výpisu na zhruba 1 000 příspěvků (API vrací jen nejnovějších přibližně 1 000 příspěvků na jeden listing endpoint).
Osvědčené postupy pro správu rate limitů
Současný veřejný základ Redditu: . V praxi to řešte takto:
- Exponenciální backoff. Když dostanete rate-limit odpověď, počkejte a při každém dalším pokusu prodlužujte pauzu (1 s, 2 s, 4 s, 8 s…). Neopakujte endpoint jako zběsilí.
- Čtěte hlavičky
X-Ratelimit-Remaining. Odpovědi API Redditu obsahují hlavičky, které říkají, kolik požadavků vám zbývá a kdy se okno obnoví. Řiďte tempo podle nich, ne odhadem. - Rotující user-agenty. Některé repozitáře to doporučují jako způsob, jak se vyhnout detekci. Může to pomoci, ale používejte to eticky — ne k obcházení banů, které jste si zasloužili.
- Logujte všechno. Přidejte logování odpovědí API, hlaviček rate limitů i chyb. Když váš scraper umře ve 2 ráno, logy jsou váš nejlepší kamarád.
Jak překonat strop 1 000 příspěvků
Nejvěrohodnější workaround pro limit kolem 1 000 položek je dělení podle časového okna:
- Zeptejte se na jeden časový úsek pomocí parametrů
beforeaafter. - Posuňte okno dopředu (nebo dozadu).
- Opakujte.
- Deduplicitně porovnávejte podle ID příspěvku.
Není to elegantní, ale je to poctivější než předstírat, že jeden request loop vytáhne libovolnou historii z listing endpointu. Pro skutečně historická data byste potřebovali schválený akademický přístup nebo licencovanou cestu — Pushshift už není výchozí odpověď.
Scraping přes prohlížeč (Playwright nebo Thunderbit) tenhle limit obchází úplně, protože scrapuje to, co je vykreslené na stránce, ne to, co vrací API. Funkce stránkování v Thunderbit vám umožní klikat přes stránky a sbírat data z tolika stran, kolik potřebujete.
Deduplicitace a obnova po chybách
Většina repozitářů typu reddit scraper github nemá deduplikaci ani obnovu po chybách vestavěnou. Uživatelé si výslovně stěžují, že „žádný neměl deduplikaci, vyhýbání se rate limitům po chybách ani kontrolu, jestli jsou soubory už stažené“. Udělejte to takto:
- Deduplicitace: Pro každý příspěvek vytvořte hash z jeho ID (nebo ID + obsahu). Ukládejte už viděné hashe do jednoduché SQLite databáze nebo klidně do textového souboru. Před vložením zkontrolujte, jestli hash už existuje. To je důležité hlavně při dělení časových oken nebo při opakovaném spouštění neúspěšných úloh.
- Obnova po chybách: Po každých N záznamech uložte průběh do checkpoint souboru. Když běh selže, restartujte z posledního checkpointu, ne od začátku. Z 3hodinové úlohy, která padá ve 2. hodině, se tak stane 1hodinové pokračování.
Jak různé přístupy zvládají tato omezení

| Přístup | Práce s rate limity | Více než 1k příspěvků? | Automatická deduplikace? | Obnova po chybách? |
|---|---|---|---|---|
| PRAW (surový) | Ručně (sleep/retry) | ❌ (limit API) | ❌ | ❌ |
| PRAW + dělení podle časového okna | Ručně | ✅ (workaround) | ❌ | ❌ (pokud ji nepřidáte) |
| Scrapování .json přes Playwright | N/A (žádné API) | ✅ | ❌ | ❌ |
| Thunderbit (scraping v prohlížeči) | Vestavěné (AI tempo) | ✅ (stránkování) | N/A (vizuální kontrola) | Vestavěné |
Když repozitář Reddit Scraper GitHub není odpověď: cesta bez kódu
Většina článků o reddit scraper github předpokládá, že umíte Python. Jenže hodně lidí, kteří hledají řešení pro scraping Redditu, jsou marketéři, obchodníci, výzkumníci nebo zakladatelé indie projektů, kteří Python nepíší denně. Pro takové publikum přináší GitHub repozitář skryté náklady:
- Nastavování OAuth přihlašovacích údajů a vývojářské aplikace Redditu
- Správa Python virtuálních prostředí a konfliktů závislostí
- Ladění záhadných chyb, když se změní interní část PRAW
- Řešení zrušení API klíče, pokud Reddit rozhodne, že váš případ použití není schválený
- Údržba skriptu pokaždé, když Reddit něco změní
To nejsou hypotetické problémy. má 2 563 hvězdiček a 107 otevřených issue. Mezi nedávné hlášky patří „Potíže s instalací“, „Chyba modulu PRAW“ a „Výjimka, která mi ani nedovolí se autentizovat“.
Použijte GitHub repozitář, pokud...
- Potřebujete vlastní scrapingovou logiku (např. specifický průchod stromem komentářů, vlastní integraci NLP pipeline).
- Chcete to napojit na existující Python data pipeline.
- Potřebujete scrapovat ve velmi velkém měřítku s vlastním úložištěm (databáze, data warehouse).
- Jste v pohodě s údržbou kódu a řešením breaking changes.
Použijte no-code nástroj, pokud...
- Potřebujete data z Redditu rychle — během minut, ne hodin nastavování.
- Nechcete spravovat API klíče, OAuth aplikace ani Python prostředí.
- Chcete exportovat rovnou do tabulek, Notion nebo Airtable pro okamžité použití.
- Chcete, aby se nástroj automaticky přizpůsobil, když Reddit změní rozvržení.
Thunderbit přesně zapadá do no-code kategorie. Uživatelé mohou ve 2 kliknutích s poli navrženými AI, exportovat zdarma do CSV/Google Sheets/Airtable/Notion a řešit stránkování bez psaní kódu. Díky scrapování přes prohlížeč není potřeba nastavovat OAuth ani registrovat API klíč.
Rychlý postup: Jak scrapovat Reddit s Thunderbit (krok za krokem)
- Nainstalujte .
- Otevřete stránku Redditu, kterou chcete scrapovat (subreddit, výsledky hledání, profil uživatele).
- Klikněte na „AI Suggest Fields“. Thunderbit přečte stránku a navrhne sloupce — název příspěvku, autor, upvoty, časovou značku, URL atd.
- Upravte pole podle potřeby a klikněte na „Scrape“.
- Zkontrolujte datovou tabulku. Volitelně klikněte na „Scrape Subpages“, aby nástroj navštívil každý příspěvek a stáhl komentáře nebo další detaily.
- Exportujte do cílové aplikace: Google Sheets, Excel, Airtable, Notion, CSV nebo JSON.
Dvě minuty. Nula řádků kódu. Pokud to chcete vidět v akci, podívejte se na .
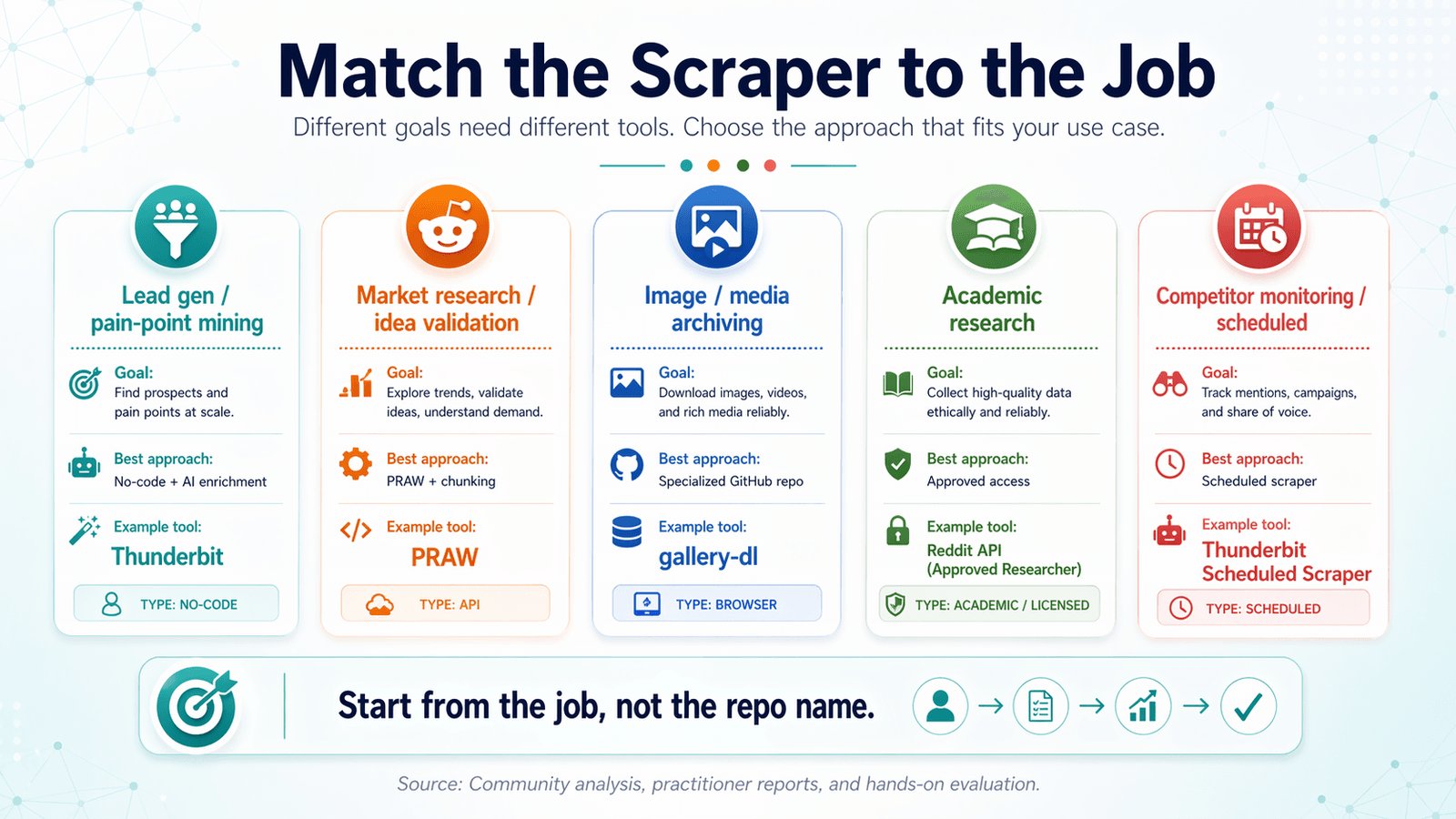
Přiřaďte Reddit scraper ke správnému úkolu: rozhodovací matice podle use case
Většina článků o reddit scraper github organizuje obsah podle nástrojů. To je ale obráceně.
Začněte cílem a teprve potom se vraťte k nástroji.
Lead generation a hledání bolestivých bodů
Co potřebujete: Příspěvky + komentáře s filtrováním podle klíčových slov, AI tagování/štítkování, export do formátů vhodných pro CRM.
Nejlepší přístup: No-code scraper s AI obohacením.
Doporučený nástroj: (AI labelování + export do Google Sheets/Airtable pro import do CRM).
Ukázkový workflow: Scrapujte subreddit a hledejte příspěvky, které zmiňují konkrétní bolestivý bod. Použijte Field AI Prompt v Thunderbitu k zařazení sentimentu nebo označení témat. Exportujte do Airtable nebo Google Sheet obchodního týmu.
Průzkum trhu a ověřování nápadů
Co potřebujete: Velké množství názvů příspěvků + skóre, data o trendech na úrovni subredditu.
Nejlepší přístup: PRAW s dělením podle časového okna pro objem, nebo Thunderbit pro rychlé stažení.
Příklad: Scrapování r/SaaS nebo r/startups kvůli trendujícím tématům a vzorcům upvotů za posledních 90 dní.
Archivace obrázků a médií
Co potřebujete: URL médií, deduplikaci, plánované běhy.
Nejlepší přístup: Specializovaný GitHub repozitář (např. ) + cron úloha.
Poznámka: Deduplikace je tady zásadní — stejný obrázek publikovaný napříč subreddity je běžný.
Akademický výzkum a historická data
Co potřebujete: Historická data, celé stromy komentářů, velké datasety.
Nejlepší přístup: Schválený akademický přístup nebo licencovaná datová cesta. Pushshift už není univerzální odpověď.
Realita: Tohle je v roce 2026 nejtěžší use case kvůli omezením Pushshiftu a zpřísněným datovým pravidlům Redditu.
Sledování konkurence a plánované scrapování
Co potřebujete: Opakované scrapování v daných intervalech, detekce změn.
Nejlepší přístup: v Thunderbitu (popište časový interval běžným jazykem, vložte URL, klikněte na Schedule) nebo cron + skript pro uživatele kódu.
Tabulka rozhodování podle use case
| Use case | Co potřebujete | Nejlepší přístup | Ukázkový nástroj |
|---|---|---|---|
| Lead gen / hledání bolestivých bodů | Příspěvky + komentáře, filtrování podle klíčových slov, AI tagování | No-code scraper + AI obohacení | Thunderbit |
| Průzkum trhu / ověřování nápadů | Názvy příspěvků ve velkém + skóre, data na úrovni subredditu | PRAW + dělení podle časového okna nebo Thunderbit | PRAW nebo Thunderbit |
| Archivace obrázků/médií | URL médií, deduplikace, plánované běhy | Specializovaný GitHub repozitář + cron | bulk-downloader-for-reddit |
| Akademický výzkum | Historická data, celé stromy komentářů | Schválený akademický přístup nebo Playwright | Pushshift academic API (pokud je dostupné) |
| Sledování konkurence / plánované | Opakované scrapování, detekce změn | Scheduled scraper | Thunderbit Scheduled Scraper nebo cron + skript |
Jak vyhodnotit kterýkoli repozitář Reddit Scraper GitHub dřív, než se do něj pustíte
Než repo naklonujete a začnete ladit, udělejte tuto 5minutovou zdravotní kontrolu. Ušetří vám hodiny.
5minutová kontrola zdraví repozitáře
- Datum posledního commitu. Pokud je to víc než 6 měsíců, postupujte opatrně. API Redditu se mění často.
- Poměr otevřených vs. uzavřených issue. Vysoký počet nezodpovězených issue je červená vlajka. Zkontrolujte, jestli nedávné issue zmiňují selhání autentizace, 403 nebo výpadky Pushshiftu.
- Soubor LICENSE. Zjistěte, jestli existuje. Žádná licence = právně nejasné (víc níže).
- Závislosti. Jsou požadované knihovny aktuální? Používá zastaralé balíčky?
requirements.txtplný připíchnutých verzí z roku 2022 je varovný signál. - Kvalita README. Vysvětluje nastavení jasně? Jsou tam příklady použití? Špatná dokumentace = pro vás víc ladění.
- Hvězdičky vs. fork a nedávná aktivita. Hodně hvězdiček, ale nízká nedávná aktivita může znamenat, že projekt býval populární, ale dnes je opuštěný. Porovnejte hvězdičky s datem
pushed_at.
Rychlý příklad: má 364 hvězdiček — na první pohled vypadá důvěryhodně. Ale repozitář je archivovaný a README říká „THIS REPOSITORY IS STALE.“
Samotné hvězdičky neřeknou celý příběh.
Tipy, jak z Reddit Scraper GitHub setupu vytěžit maximum
Pokud se přece jen vydáte cestou kódu, tady je, jak si ušetřit bolesti hlavy.
Vždy používejte virtuální prostředí
Virtuální prostředí drží závislosti scraperu izolované, takže se nepřekrývají s jinými Python projekty. Jeden příkaz: python -m venv venv a pak prostředí před instalací čehokoli aktivujte. Je to základní hygiena, ale už jsem viděl dost GitHub issue s názvem „module not found“, abych věděl, že to stojí za připomenutí.
Ukládejte přihlašovací údaje bezpečně
Nikdy napevno nepište client ID nebo secret Reddit API přímo do skriptu. Použijte proměnné prostředí nebo soubor .env a přidejte .env do .gitignore. Pokud omylem pošlete přihlašovací údaje na GitHub, hned je otočte — roboti vyhledávají odhalené API klíče.
Logujte všechno
Přidejte logování odpovědí API, hlaviček rate limitů i chyb. Když se něco rozbije, logy rozhodují mezi „vím přesně, co se stalo“ a „nemám tušení, proč to přestalo fungovat“.
Plánujte a automatizujte s rozmyslem
Pokud spouštíte opakované scrapování, použijte cron (Linux/Mac) nebo Task Scheduler (Windows) — ale sledujte selhání. Cron úloha, která dva týdny tiše selhává, je horší než žádná automatizace.
Alternativa: v Thunderbitu vám umožní popsat interval běžným jazykem, bez potřeby cron syntaxe.
Právní a etické best practices pro scraping Redditu
Tohle není jen formální upozornění. Reddit od změn API v roce 2023 agresivně vymáhá své podmínky a scraping osobních údajů nese reálné právní riziko.
Tady je to, na čem skutečně záleží.
Podmínky služby Redditu: co opravdu říkají
Redditu (revidovaný k 31. březnu 2026) výslovně zakazuje přístup k datům ze služeb, jejich vyhledávání nebo sběr automatizovanými prostředky, pokud to není povoleno podmínkami nebo samostatnou smlouvou. a přidávají další detaily: Reddit může monitorovat a auditovat používání vývojáři, měnit nebo ukončit přístup a trvale zablokovat přístup při nadměrném nebo zneužívajícím používání. Komerční použití obecně vyžaduje výslovné schválení.
jde ještě dál: před přístupem k datům Redditu přes API je vyžadované schválení, neschválená komercializace a využití pro AI/data mining jsou zakázané a vymáhání může zahrnovat zrušení tokenů, pozastavení aplikací nebo účtů a také pozastavení souvisejících botů či domén.
Soulad s robots.txt
Současný Redditu je nezvykle restriktivní:
1User-agent: *
2Disallow: /To je plošný zákaz pro všechny automatizované user agenty. Soubor také odkazuje na . To je mnohem přísnější než permisivní vzory robots.txt, které někteří vývojáři stále předpokládají podle starších zvyklostí web scrapingu.
Nejlepší praxe: před scrapingem vždy zkontrolujte robots.txt, i když váš nástroj kontrolu neprosazuje automaticky.
Osobní údaje a soukromí (GDPR/CCPA)
Pokud scrapujete uživatelská jména, historii příspěvků nebo jakékoli osobně identifikovatelné údaje, mohou se uplatnit (EU) a CCPA (Kalifornie). Nejlepší praxe: před uložením osobní údaje anonymizujte nebo agregujte. Netvořte profily jednotlivých uživatelů bez právního důvodu.
Licence GitHub repozitářů: zkontrolujte dřív, než začnete stavět
Mnoho repozitářů typu reddit scraper github používá MIT nebo Apache licenci (permisivní), ale některé nemají žádný licenční soubor vůbec — což právně znamená „všechna práva vyhrazena“. Než repo forknete, upravíte nebo na něm něco postavíte, vždy zkontrolujte soubor LICENSE. Žádná licence = právně nejasné, bez ohledu na počet hvězdiček.
Vymáhání je v letech 2025–2026 reálné
Příběh vymáhání Redditu neskončil v roce 2023. Reddit podal v roce 2025 stížnost na Anthropic s tvrzením o neoprávněném scrapingu/použití obsahu Redditu a na konci roku 2025 také postupoval proti Reddit v. SerpApi. To jsou signály, že Reddit je připraven se bránit právně, nejen technickým blokováním.
Jak si v roce 2026 vybrat správný přístup k Reddit Scraper GitHubu
Scéna reddit scraper github se od roku 2023 dramaticky změnila. Většina repozitářů je zastaralá. Rate limity a limit 1k příspěvků jsou reálná omezení. Pushshift pro běžné uživatele zmizel. A vrstva pravidel Redditu je výslovnější a přísněji vynucovaná než kdy dřív.
Krátká verze:
- PRAW je pořád nejspolehlivější open-source základ, pokud přijmete limity API Redditu a chcete si napsat vlastní logiku.
- Pushshift/PSAW už není univerzální odpověď.
- Reddit modul snscrape je legacy a nespolehlivý.
- Scrapery .json a veřejných endpointů jsou křehké a v roce 2026 bývají často blokované.
- Nástroje založené na prohlížeči — ať už repozitáře s Playwrightem, nebo no-code možnosti jako — jsou pro mnoho uživatelů, zejména neprogramátory, nejpraktičtější cestou.
Začněte use casem, ne nástrojem. Než se zavážete ke konkrétnímu GitHub projektu, projděte 5minutovou kontrolu zdraví repozitáře.
A pokud byste raději přeskočili nastavování a začali scrapovat Reddit během minut, .
Časté dotazy
Jaké jsou v roce 2026 nejlepší open-source scrapery Redditu na GitHubu?
zůstává nejspolehlivějším API wrapperem, s aktivní údržbou a dobrou dokumentací. je důvěryhodný udržovaný CLI nástroj postavený na PRAW. Scrapery založené na Playwrightu fungují pro scraping mimo API a modul snscrape pro Reddit je částečně funkční, ale z velké části bez údržby. Před použitím jakéhokoli repozitáře vždy zkontrolujte datum posledního commitu a otevřená issue — většina z na GitHubu je už zastaralá.
Je scraping Redditu legální?
Scraping veřejně dostupných dat se pohybuje v právně šedé zóně, ale vlastní podmínky Redditu jsou restriktivní. , , , a všechny omezují neoprávněné hromadné scrapování. Komerční redistribuce nascrapovaných dat může vyžadovat výslovný souhlas Redditu. Pokud scrapujete osobní údaje, mohou se navíc uplatnit GDPR a CCPA.
Jak se dostanu přes rate limity API Redditu?
Používejte exponenciální backoff, sledujte hlavičky X-Ratelimit-Remaining a zvažte dělení podle časového okna, abyste se vešli do limitů. Scraping přes prohlížeč (Playwright nebo ) obchází rate limity API, protože scrapuje vykreslené stránky, ale má vlastní omezení (rychlost načítání stránek, anti-bot opatření). Neexistuje žádný kouzelný trik, jak rate limity úplně odstranit — vynucují se na straně serveru.
Dá se Reddit scrapovat bez API klíče?
Ano. Scrapery založené na Playwrightu a trik s URL .json API klíč nepotřebují. také API klíč nevyžaduje, protože scrapuje přes prohlížeč. Kompromisy: endpointy .json jsou čím dál častěji blokované (v mnoha prostředích vrací v dubnu 2026 odpověď 403) a scraping přes prohlížeč je pomalejší a náročnější než API volání.
Co se stalo s Pushshiftem pro scraping Redditu?
Veřejný přístup k API Pushshiftu byl odstraněn po změnách licencování dat Redditu, které začaly v roce 2023. Wrapper je archivovaný a zastaralý. Omezený akademický přístup může existovat přes specifické schválené kanály, ale pro většinu uživatelů, kteří dnes hledají „reddit scraper github“, už Pushshift není použitelná možnost. Pokud potřebujete hluboká historická data z Redditu, podívejte se na schválené akademické nebo licencované datové cesty Redditu.
Další informace