Poslyšte, kdybych dostal dolar pokaždé, když mi někdo pošle PDF nacpané „důležitými daty“ a čeká, že je kouzlem proměním v tabulku, nejspíš bych si mohl dovolit doživotní zásobu kávy (a možná i pár extra rozšíření do Chromu). PDF jsou všude — prodejní smlouvy, produktové katalogy, výzkumné práce, faktury, prostě cokoli. Jenže jakmile ta data máte opravdu použít? No, právě tam začíná zábava (čti: bolest hlavy).
Prošel jsem si tím mnohokrát — kopírování, vkládání, přeformátování a občas i prosté vzdechování, když se formát úplně rozsypal nebo obrázky a odkazy zmizely do neznáma. Dobrá zpráva je, že svět získávání dat z PDF se dramaticky změnil, hlavně díky nástupu nástrojů poháněných AI. Pokud vás už nebaví trávit hodiny přepisováním čísel nebo zoufat nad rozbitými tabulkami, jste na správném místě. Pojďme se ponořit do světa získávání dat z PDF, podívat se, proč je to důležité, a jak nástroje jako konečně celý proces zjednodušují.
Co je získávání dat z PDF? Základy extrakce dat z PDF
Začněme jednoduše: získávání dat z PDF je jen elegantní výraz pro „automatické získávání strukturovaných dat z PDF souborů“. PDF scraper je nástroj (software, rozšíření nebo služba), který vytáhne to, co vás zajímá — text, tabulky, obrázky, odkazy, cokoli — a převede to do formátu, se kterým se dá opravdu pracovat, třeba do Excelu, Google Sheets nebo databáze.
Jenže je tu háček: PDF nejsou jako webové stránky nebo Excel soubory. Jsou spíš jako digitální výtisky, navržené tak, aby vypadaly stejně všude, ne aby se daly snadno rozebrat počítačem. Některá PDF obsahují text, který lze označit, jiná jsou jen naskenované obrázky (a ty potřebují OCR — optické rozpoznávání znaků) a formátování může být úplně všelijaké. Získávání dat z PDF tedy není jen o kopírování textu — je to spíš luštění skládačky z rozvržení, písem a někdy i skrytých metadat.
Co všechno lze z PDF vytáhnout?
- Běžný text (odstavce, nadpisy atd.)
- Tabulky (například finance, specifikace produktů, výsledky průzkumů)
- Obrázky a grafika (grafy, loga, naskenované podpisy)
- Hyperlinky a odkazy (vložené URL adresy, citace)
- Data z formulářů (pole z vyplnitelných formulářů)
- Metadata (autor, název, datum vytvoření, značky)
A ano, někdy je to všechno nacpané do jednoho nádherně chaotického dokumentu.
Proč na získávání dat z PDF záleží: reálné scénáře a přínosy pro byznys
Tak proč se vlastně s PDF zabývat? Protože je používá každý a data v nich bývají pro firmy zásadní. Tady se získávání dat z PDF opravdu vyplatí:
| Případ použití | Ruční práce | S PDF scraperem | Úspora času a chyb |
|---|---|---|---|
| Extrakce obchodních leadů | Hodiny kopírování kontaktů z nabídek nebo PDF z akcí, riziko, že nějaký lead přehlédnete | Okamžitě vytáhne všechny leady do tabulky | o 80–90 % rychlejší, méně chyb |
| Produktová data pro e-commerce | Dny ručního přepisování specifikací produktů z PDF dodavatelů, formátovací peklo | Hromadná extrakce do CSV nebo Sheets | Úspora času přes 95 %, konzistentní data |
| Analýza výzkumných dat | Týdny přepisování tabulek z odborných prací, vysoké riziko překlepů | Vytáhne tabulky, odkazy i naskenovaný text | Úspora času 80 %, vyšší přesnost |
Pojďme si k tomu říct pár čísel:
- Každý rok vznikne .
- používá PDF jako hlavní formát pro sdílení informací.
- Ruční digitální administrativa (například zadávání dat z PDF) zabírá .
- Automatizované nástroje mohou snížit chybovost z .
Pokud pracujete v prodeji, e-commerce nebo výzkumu, automatizace extrakce dat z PDF není jen „nice to have“ — je to konkurenční výhoda.
Tradiční metody získávání dat z PDF: problémy a limity
Buďme upřímní: staré způsoby, jak dostat data z PDF ven, nejsou žádná sláva. Tohle jsme zkoušeli skoro všichni (a právě proto nás to tak štve):

1. Ruční kopírování a vkládání
- Bolestivé body: Formátování se rozbije, tabulky se změní v chaos, obrázky a odkazy zmizí a vy si odnášíte migrénu.
- Náklady na práci: Vysoké. Pokud máte 5 000 PDF a každé zabere 1 minutu, je to víc než 80 hodin života, které už nikdy nedostanete zpět.
- Chybovost: 5–10 %. Překlepy, vynechané řádky, nechtěné smazání — známé, prošlé.
2. Převod do Wordu/Excelu a následné čištění
- Bolestivé body: U jednoduchých dokumentů to někdy funguje, ale složitá rozvržení nebo tabulky se rozhází. Stejně pak musíte ten nepořádek ručně opravovat.
- Obrázky/odkazy: Většinou se cestou ztratí.
- Cílená extrakce: Zapomeňte — dostanete celý dokument, ne jen to, co potřebujete.
3. Vlastní skripty (Python atd.)
- Bolestivé body: Musíte být programátor (nebo mít jednoho na rychlé volbě). Každý nový formát PDF znamená úpravu skriptu. Naskenovaná PDF? Hodně štěstí.
- Údržba: Vysoká. Jakmile dodavatel změní šablonu faktury, skript se rozbije.
- Škálovatelnost: Nic pro slabší povahy (nebo netechnické uživatele).
4. Online konvertory
- Bolestivé body: Na jednorázové úkoly snadné, ale citlivé dokumenty musíte nahrávat na cizí server (ahoj, problémy s compliance). Omezená kontrola nad tím, co se skutečně vytáhne.
- Formátování: Někdy ano, někdy ne. Můžete strávit víc času opravami, než kolik jste ušetřili.
Shrnutí: Tradiční metody jsou pomalé, chybové a neskalují. Proto se s tím tolik týmů jednoduše „smíří“ — jenže za cenu obrovské ztráty produktivity.
Moderní řešení pro získávání dat z PDF: od kódu po no-code nástroje
Naštěstí už nejsme zaseknutí ve středověku. Trh se zaplnil chytřejšími, rychlejšími a uživatelsky přívětivějšími možnostmi pro získávání dat z PDF.
1. Programovací knihovny (pro vývojáře)
- Příklady: , , .
- Silné stránky: Velmi flexibilní, dají se automatizovat pro velké dávky, zdarma (open source).
- Slabé stránky: Vysoká doba nastavení, vyžadují programátorské dovednosti, křehké (rozbíjejí se s novými formáty), omezená podpora OCR/obrázků.
2. Online převodníky PDF
- Příklady: , , .
- Silné stránky: Žádné nastavování, snadné i pro netechnické uživatele, rychlé pro malé úkoly.
- Slabé stránky: Omezené možnosti přizpůsobení, obavy o soukromí, chyby ve formátování, limity velikosti souboru a počtu stran.
3. AI nástroje pro získávání dat z PDF
- Příklady: , Nanonets, Docparser.
- Silné stránky: Nepotřebujete kód, zvládají text/tabulky/obrázky/odkazy, AI navrhne, co vytáhnout, podporují dávkové zpracování, integrace se Sheets/Notion/Airtable.
- Slabé stránky: Některé mají limity na kredity/strany, mohou vyžadovat připojení k internetu, u složitých dokumentů se občas musíte chvíli naučit, jak s nimi pracovat.
Porovnání nástrojů pro získávání dat z PDF: která cesta je pro vás?
| Nástroj/metoda | Nastavení | Nejlepší pro | Vytahuje | Lze přizpůsobit? | Cena |
|---|---|---|---|---|---|
| Tabula (Tabula-py) | Střední (UI/kód) | Tabulky v PDF | Tabulky | Částečně | Zdarma |
| PDFMiner | Vyžaduje kódování | PDF s velkým množstvím textu | Text | Ano (kód) | Zdarma |
| PyPDF2 | Vyžaduje kódování | Jednoduchý text/metadata | Text, metadata | Ano (kód) | Zdarma |
| Smallpdf/online převodníky | Žádné (webové) | Rychlé převody | Celý dokument (Word/Excel) | Ne | Freemium |
| Thunderbit | Instalace na 2 kliknutí | Firemní uživatelé, týmy | Text, tabulky, obrázky, odkazy | Ano (AI prompty) | Freemium (Pro od 16,5 $/měs.) |
Seznamte se s Thunderbit: AI PDF scraper rozšíření do Chromu
Teď si pojďme říct o nástroji, který mi i spoustě firemních uživatelů výrazně usnadnil život: .
Čím je Thunderbit jiný?
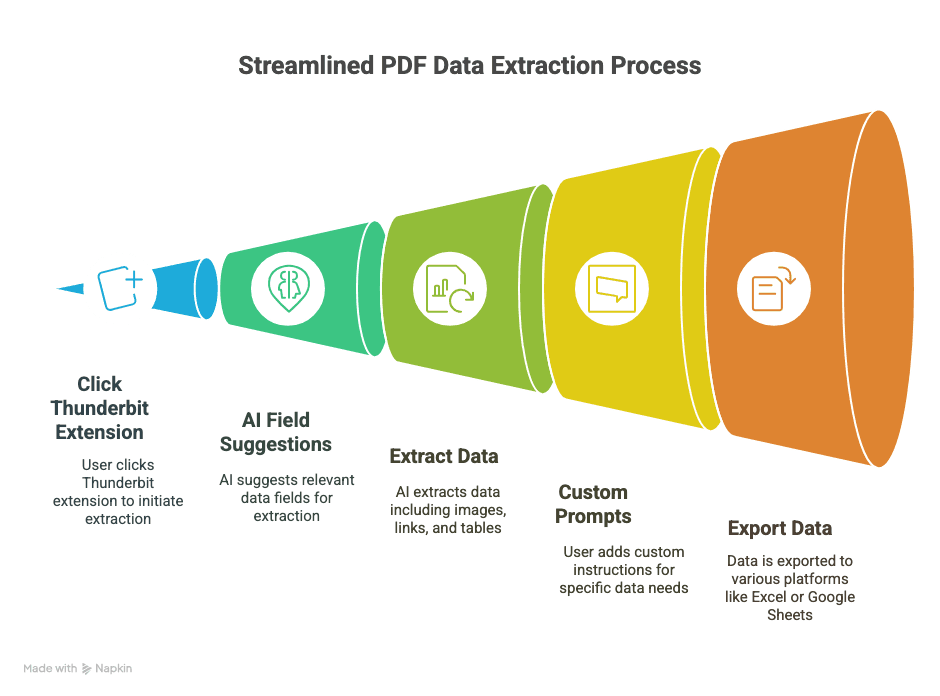
- Extrakce na 2 kliknutí: Otevřete PDF v Chromu, klikněte na rozšíření Thunderbit a zbytek nechte na AI.
- Návrhy polí řízené AI: Funkce „AI Suggest Fields“ přečte vaše PDF a navrhne sloupce, které pravděpodobně potřebujete (například „Jméno“, „E-mail“, „Cena“ atd.).
- Zvládá obrázky, odkazy a tabulky: Nejen prostý text — Thunderbit umí vytáhnout obrázky, hypertextové odkazy a dokonce spustit OCR nad naskenovanými dokumenty.
- Vlastní prompty: Potřebujete jen telefonní čísla nebo specifikace produktů? Přidejte vlastní instrukci a Thunderbit se zaměří jen na ně.
- Export kamkoli: Pošlete data rovnou do Excelu, Google Sheets, Airtable nebo Notionu. Konec CSV akrobacii.
- Dávkové a podstránkové scrapování: Máte seznam PDF nebo odkazů? Thunderbit je zvládne zpracovat najednou.
- Spolehlivost na úrovni byznysu: Navrženo pro přesnost, soukromí a reálné pracovní procesy.
Stručně řečeno, je to jako mít digitálního stážistu, kterého baví zadávání dat (a nikdy se neunaví).
Jak získat data z PDF pomocí Thunderbit: průvodce krok za krokem
Jste připraveni vidět, jak snadné to může být? Takhle používám Thunderbit k převodu PDF na strukturovaná, použitelná data:
1. Nainstalujte Thunderbit
- Stáhněte si .
- Zaregistrujte se (stačí účet Google nebo e-mail — zabere to pár sekund).
2. Otevřete PDF v Chromu
- Buď otevřete PDF přes webový odkaz, nebo přetáhněte místní PDF do karty Chromu.
3. Spusťte Thunderbit nad PDF
- Klikněte na ikonu Thunderbit v liště prohlížeče.
- Vyberte „AI Web Scraper“ — Thunderbit pozná, že jde o PDF, a připraví se na práci.
4. Nechte AI navrhnout pole
- Klikněte na „AI Suggest Columns“.
- AI v Thunderbitu projde PDF a doporučí sloupce (například „Datum“, „Částka“, „Jméno kontaktu“ atd.).
- Zobrazí vám náhled extrahovaných dat přímo v tabulce v rozšíření.
5. Upravte si to podle potřeby
- Přejmenujte sloupce, smažte přebytečné nebo přidejte vlastní (například „Doba záruky“ nebo „URL produktu“).
- U složitějších dat vyberte v PDF text a naučte tím AI, co přesně chcete.
6. Vyberte formát exportu
- Zvolte CSV, Google Sheets, Airtable nebo Notion.
- Udělte Thunderbitu oprávnění k připojení (jednorázové nastavení).
7. Proveďte extrakci a export
- Klikněte na „Scrape“ nebo „Export“.
- Thunderbit zpracuje PDF a pošle data tam, kam potřebujete — obvykle během několika sekund.
A hotovo. Žádný kód, žádné kopírování a vkládání, žádné drama.
Tipy pro přesnou extrakci dat z PDF s Thunderbit
- Zkontrolujte pole navržená AI: AI je chytrá, ale rychlé ověření vám zajistí, že dostáváte přesně to, co potřebujete.
- Práce se složitými tabulkami: U vícestránkových nebo divně naformátovaných tabulek použijte náhled, najděte problémy a podle potřeby upravte sloupce.
- Extrahujte obrázky/odkazy: Nezapomeňte tato pole zahrnout, pokud je vaše PDF obsahuje — Thunderbit je zvládne také.
- Naskenovaná PDF: Vestavěné OCR v Thunderbitu je solidní, ale čím čistší sken, tím lepší výsledky.
- Vlastní prompty: Chcete jen e-maily nebo telefonní čísla? Přidejte prompt typu „Vytáhni všechny e-mailové adresy“ a Thunderbit se zaměří na ně.
Pokročilé získávání dat z PDF: extrakce obrázků, odkazů a vlastních dat
Thunderbit není jen o prostém textu. Takhle můžete z PDF dostat ještě víc:
- Obrázky: Vytáhněte loga, grafy nebo jakoukoli vloženou grafiku. Thunderbit dokáže dokonce OCR textu uvnitř obrázků.
- Hyperlinky: Získejte všechna URL nebo odkazy — skvělé pro odborné práce nebo životopisy.
- Vlastní datové typy: Použijte AI prompty k extrakci přesně toho, co potřebujete (například „Najdi všechna produktová SKU a jejich ceny“).
- Shrnutí a kategorizace: Přidejte sloupec a nechte Thunderbit shrnout sekci nebo průběžně kategorizovat data.
Parsování dat z PDF pro konkrétní firemní potřeby
- Prodej: Z batchu nabídek vytáhněte jen kontaktní údaje.
- E-commerce: Z katalogů dodavatelů stáhněte specifikace produktů, ceny a obrázky.
- Výzkum: Získejte tabulky, odkazy a dokonce generujte shrnutí z odborných článků.
A jakmile data máte, můžete je strukturovat pro snadnou analýzu v Excelu, Google Sheets nebo Notionu — Thunderbit udělá těžkou práci za vás a vy už jen používáte výsledky.
Export a používání dat z PDF: od extrakce k akci
Dostat data ven je teprve začátek. Takhle je můžete skutečně využít:
- Možnosti exportu: CSV, Excel, Google Sheets, Airtable, Notion — vyberte si, co vám sedí.
- Tipy na formátování: Používejte nastavení typů sloupců v Thunderbitu (číslo, datum, text), aby byla data čistá a připravená k analýze.
- Propojení workflow: Napojte exportovaná data na CRM, skladové systémy nebo analytické dashboardy.
- Spolupráce: Sdílejte tabulky Google Sheets nebo báze Airtable se svým týmem — všichni pracují se stejnými, aktuálními daty.
A to nejlepší? Už žádné přeposílání tabulek e-mailem tam a zpět nebo přemýšlení, jestli vám neunikl nějaký řádek.
Časté nástrahy při získávání dat z PDF a jak se jim vyhnout
I s nejlepšími nástroji se mohou objevit zádrhele. Tohle jsem se naučil (někdy i tvrdou cestou):
- Chyby OCR: Rozmazané skeny nebo divná písma dokážou zmást i nejlepší OCR. Snažte se používat co nejčistší PDF a kritická pole vždy zkontrolujte.
- Složité rozvržení: Tabulky ve více sloupcích nebo vnořené tabulky mohou potřebovat trochu ručního vedení — použijte ruční výběr nebo prompty v Thunderbitu.
- Datové typy: Čísla s čárkami nebo data v netypických formátech? Nastavte typ sloupce před exportem, nebo to očistěte v Excelu/Sheets.
- Limity velikosti souboru a počtu stran: Obří PDF? Rozdělte je na menší části, nebo použijte cloudový režim Thunderbitu pro dávkové úlohy.
- AI „halucinace“: Je to vzácné, ale občas může AI odhadnout název sloupce nebo doplnit chybějící data. Výstup vždy zběžně zkontrolujte, hlavně u důležitých čísel.
- Ruční kontrola: U dat zásadních pro byznys si dejte rychlou validaci — automatizované nástroje jsou přesné, ale lidské oko se vždy hodí.
A když narazíte na zeď, je tu podpora a komunita Thunderbit, které vám pomohou.
Závěr a hlavní poznatky: jak dostat získávání dat z PDF do služeb vašeho byznysu
Na závěr: získávání dat z PDF bývalo noční můrou — pomalé, chybové a prostě otravné. Ale s moderními nástroji jako je dnes rychlé, přesné a troufám si říct, že skoro i příjemné.
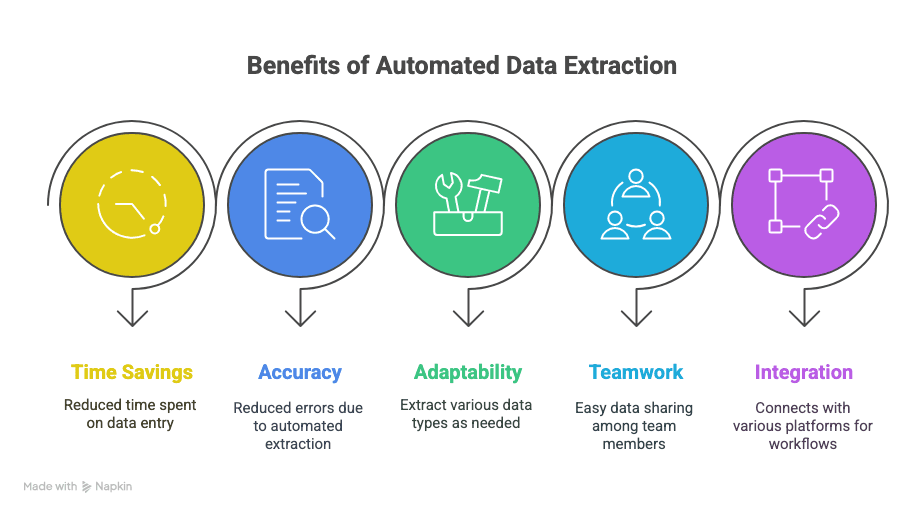
Co získáte:
- Zpět svůj čas: Ušetříte hodiny (nebo i týdny) ručního zadávání dat.
- Méně chyb: Automatická extrakce znamená méně překlepů a vynechaných řádků.
- Flexibilitu: Vytáhnete přesně to, co potřebujete — text, tabulky, obrázky, odkazy, cokoli.
- Spolupráci: Okamžitě sdílíte data se svým týmem, ať je kdekoli.
- Chytřejší workflow: Napojíte se na Sheets, Notion, Airtable a další.
Chcete to zkusit? Stáhněte si , spusťte ho na svém příštím PDF a uvidíte, o kolik snazší život může být. Vaše budoucí já (a vaše zápěstí) vám poděkuje.
Další tipy a návody najdete na nebo se ponořte hlouběji do článku .
Pojďme z těch PDF bolestí hlavy udělat vítězství v produktivitě — po jednom kliknutí.
Shuai Guan, spoluzakladatel a CEO, Thunderbit