Tempo digitálních zpráv je dnes fakt šílené. Každou minutu se publikuje, aktualizuje nebo potichu upraví tisíce titulků – napříč velkými médii, specializovanými blogy i sociálními sítěmi. Pro představu: zpracuje přes 4 miliony článků denně, zatímco sleduje zprávy ve více než 100 jazycích a globální feed obnovuje každých 15 minut. Pro lidi z médií, výzkumu nebo business intelligence je snaha držet krok ručně jako vylévat vodu z potápějící se lodi kávovým hrnkem.
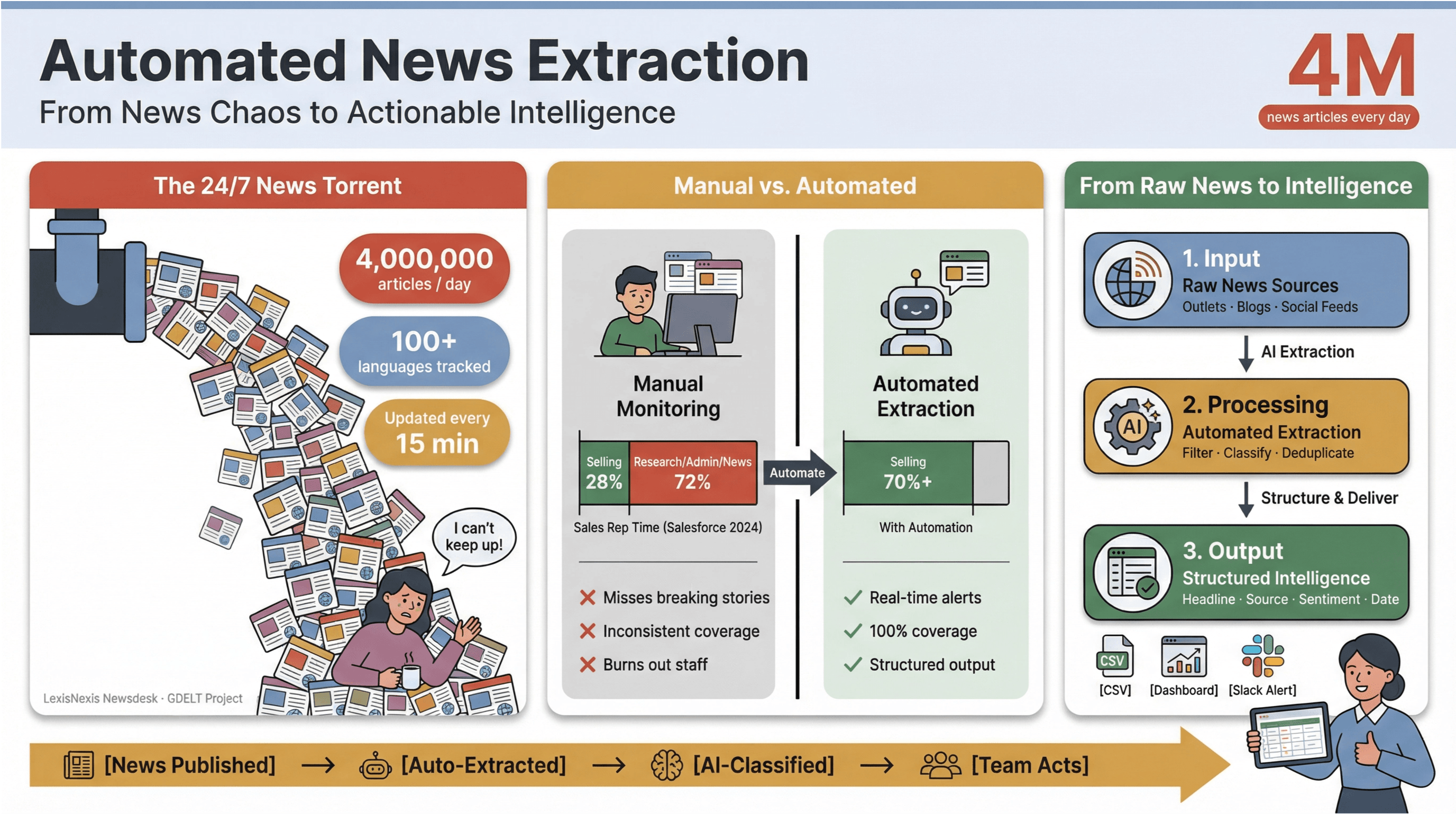
Z vlastní zkušenosti vím, jak ruční monitoring zpráv umí sežrat čas a vysát kapacity. Obchodní týmy stráví skutečným prodejem méně než třetinu týdne – podle Salesforce je to – a zbytek padne na rešerše, administrativu a ano, i nekonečné přepínání mezi záložkami se zprávami. Právě proto se automatizovaná extrakce zpráv stala takovou tajnou zbraní moderních týmů: jako jedna z mála dokáže proměnit chaos 24/7 zpravodajského cyklu ve strukturované, použitelné poznatky – bez vyhoření lidí a bez toho, abyste přehlédli to nejdůležitější.
Pojďme si rozebrat, co automatizovaná extrakce zpráv doopravdy znamená, proč je klíčová pro každého, kdo potřebuje data ze zpráv v reálném čase, a jak postavit robustní a compliant workflow s nejlepšími nástroji (včetně toho, jak celý proces překvapivě zjednodušuje – i pro netechnické uživatele, jako je moje máma).
Automatizovaná extrakce zpráv: proč je nezbytná pro moderní redakce
Automatizovaná extrakce zpráv je přesně to, co název říká: použití softwaru k automatickému sběru zpravodajského obsahu a jeho převodu do strukturované, prohledávatelné podoby – tedy řádky a sloupce místo chaotických webových stránek nebo PDF. V praxi to znamená, že můžete sledovat stovky (nebo tisíce) zdrojů, vytahovat klíčová pole jako titulek, čas, autor a text článku a posílat data do dashboardů, alertů nebo navazujících analýz – bez jediného Ctrl+C/Ctrl+V.
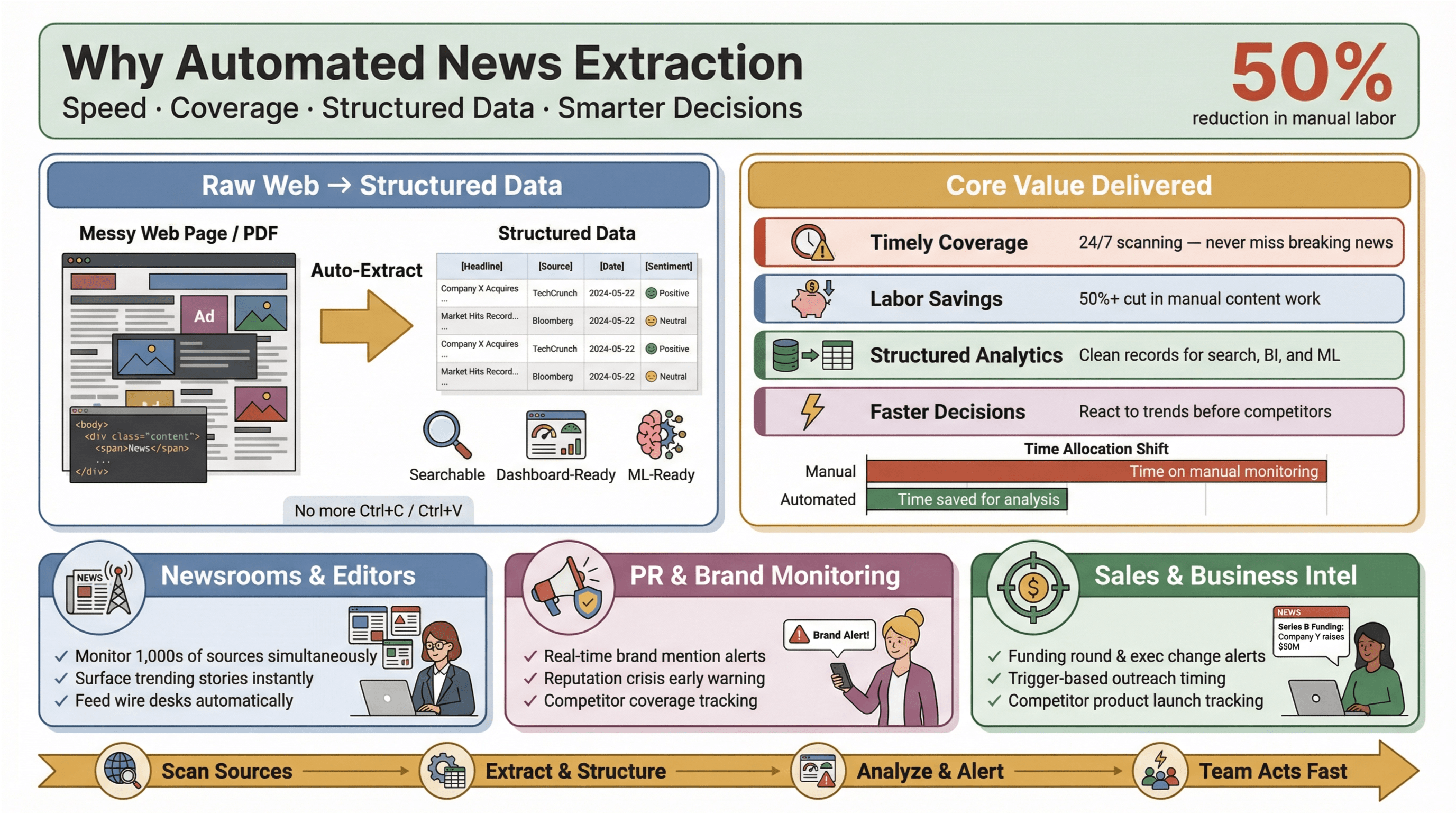
Proč na tom záleží? Protože v dnešním zpravodajském prostředí platí, že rychlost rozhoduje. Ať jste editor v redakci, PR manažer hlídající zmínky o značce, nebo analytik sledující kroky konkurence, být první může znamenat rozdíl mezi využitím příležitosti a doháněním ostatních. Nástroje pro automatizovanou extrakci umožní i malým týmům hrát „vyšší ligu“ – sbírat data ze zpráv v reálném čase napříč webem, snížit ruční práci a vytáhnout na povrch to, co je opravdu podstatné.
A dopad je měřitelný: studie ukazují, že automatizace dokáže snížit ruční práci při aktualizacích obsahu minimálně o 50 %, takže zůstane více času na analýzu a rozhodování.
Hlavní přínosy automatizované extrakce zpráv v news průmyslu
Pojďme k praxi. Co automatizovaná extrakce zpráv reálně přináší redakcím a firemním týmům?
- Včasné a kompletní pokrytí: Už žádné promeškané breaking news jen proto, že někdo zapomněl zkontrolovat feed. Automatizované nástroje skenují zdroje 24/7.
- Úspora práce i nákladů: Malé a střední týmy zvládnou hlídat tolik zdrojů jako velcí hráči – bez armády stážistů.
- Strukturovaná data pro analytiku: Místo procházení nestrukturovaných článků dostanete čisté záznamy připravené pro vyhledávání, dashboardy i machine learning.
- Rychlejší a chytřejší rozhodování: Data ze zpráv v reálném čase umožní reagovat na změny trhu, PR krize nebo nové trendy dřív než konkurence.
V PR a komunikaci platformy jako a staví monitoring médií v reálném čase do role nutnosti – pro ochranu reputace a rychlou reakci na negativní pokrytí. V obchodu se z alertů stávají „kontextové karty“ pro prospecting – například investiční kola, změny ve vedení nebo launch produktu, které spustí oslovení ve správný moment.
Jak vybrat správné nástroje pro scraping zpráv podle scénáře
Ne všechny nástroje pro scraping zpráv jsou stejné. Správná volba závisí na cílech, technické zdatnosti a typech zpráv, které vás zajímají. Tady je rámec, který pomůže vybrat nejlepší variantu:
Hodnocení použitelnosti a dostupnosti
Pro většinu byznys uživatelů a novinářů je snadné použití naprostý základ. Potřebujete nástroj, který funguje hned, bez programování a složitého nastavování. No-code a low-code platformy jako , a umožňují stavět scrapery vizuálně – ukázat, kliknout, vytěžit.
Thunderbit vyniká hlavně dvoukrokovým postupem: popíšete, co chcete, AI navrhne pole a vy jen kliknete na „Scrape“. I netechnický uživatel tak nastaví pipeline na data ze zpráv během minut, ne hodin.
Bezpečnost a ochrana soukromí
S daty přichází i odpovědnost. Nástroje pro scraping zpráv často pracují s citlivým obsahem, takže bezpečnost a compliance musí být priorita. Hledejte:
- Šifrování dat (při přenosu i v úložišti)
- Srozumitelné zásady ochrany soukromí (Thunderbit například uvádí, že neprodává uživatelská data a přistupuje jen k obsahu, který si zvolíte scrapovat)
- Jemně nastavitelné oprávnění (u rozšíření do prohlížeče vždy zkontrolujte, k jakým datům má nástroj přístup)
- Soulad s místní legislativou (GDPR, CCPA a pro EU také )
Pro větší klid vybírejte prověřené dodavatele, ověřujte oprávnění rozšíření a omezujte přístup jen na nezbytné minimum.
Sladění nástrojů s typy zpráv a potřebami odvětví
Některé nástroje jsou silné v konkrétních doménách:
- Finance: API jako a nabízí clustering, sentiment i detekci událostí pro finanční zprávy.
- Tech & startupy: Vlastní scraping přes Thunderbit nebo Octoparse umožní cílit na niche blogy, tiskové zprávy nebo seznamy akcí.
- Politika & regulace: Licencované databáze jako a poskytují přístup k prémiovým zdrojům a archivům.
Pokud potřebujete hlídat mix mainstreamu, specializovaných i mezinárodních zdrojů – včetně těch bez API – nejlépe poslouží flexibilní AI scrapery jako Thunderbit.
Jedinečné výhody Thunderbit pro extrakci dat ze zpráv v reálném čase
Teď k tomu, proč je skvělou volbou pro automatizovanou extrakci zpráv – hlavně pokud chcete data ze zpráv v reálném čase bez technických komplikací.
Thunderbit je AI Web Scraper rozšíření pro Chrome navržené pro byznys uživatele, novináře a analytiky, kteří potřebují aktuální, strukturovaný zpravodajský obsah z libovolného webu. Proč je to můj favorit:
- AI Suggest Fields: Thunderbit přečte stránku se zprávami a automaticky navrhne nejlepší sloupce k extrakci – titulek, čas, autor, shrnutí a další. Bez hraní si se selektory nebo šablonami.
- Subpage Scraping: Potřebujete celý článek, ne jen titulek? Thunderbit umí projít každý odkaz, vytáhnout text, entity i tagy a vše sloučit do jedné strukturované tabulky.
- Hromadný export a okamžité aktualizace: Data vyexportujete jedním kliknutím do Excelu, Google Sheets, Airtable nebo Notion. Konec copy-paste maratonů a ruční práce s CSV.
- Scheduled Scraper: Nastavte opakované běhy (každou hodinu, denně nebo v libovolném intervalu), aby byl váš news feed stále čerstvý – ideální pro breaking news, monitoring trhu i průběžný výzkum.
- Přizpůsobivost: AI v Thunderbit se přizpůsobí změnám layoutu i „long-tail“ webům, takže méně času strávíte opravami a více analýzou.
S více než a hodnocením 4,8 hvězdy mu důvěřují týmy po celém světě – od PR monitoringu po competitive intelligence.
AI detekce polí a Subpage Scraping
Jednou z nejsilnějších funkcí Thunderbit je AI detekce polí. Stačí kliknout na „AI Suggest Fields“ a nástroj proskenuje stránku se zprávami – rozpozná klíčová pole jako název, datum, autor a shrnutí. Pole můžete upravit nebo přidat vlastní (například „označ článek jako ‚výsledky‘, pokud zmiňuje kvartální výsledky“) a zbytek zařídí AI.
Subpage Scraping je pro zprávy zásadní: nejdřív vytěžíte titulky z homepage nebo rubriky a pak necháte Thunderbit navštívit URL každého článku, aby stáhl celý text, entity a klidně i obrázky. Výsledkem jsou kompletní, obohacené záznamy připravené pro vyhledávání, dashboardy nebo navazující AI analýzu.
Hromadný export a okamžité aktualizace
Thunderbit zjednodušuje export dat ze zpráv na maximum. Jedním kliknutím pošlete strukturovaný feed do Google Sheets, Airtable, Notion nebo stáhnete jako CSV/Excel. Pro týmy, které žijí v tabulkách nebo BI nástrojích, je to obrovská úspora času.
A protože Thunderbit podporuje Scheduled Scraper, můžete nastavit běh každou hodinu, denně nebo podle vlastního harmonogramu – a mít jistotu, že data jsou stále aktuální. Už žádné čekání, až Google Alerts zaindexuje článek o několik dní později.
Jak zvládnout provozní výzvy u řešení pro data ze zpráv v reálném čase
I s nejlepšími nástroji má extrakce zpráv v reálném čase své výzvy. Tady je, jak řešit ty nejčastější:
Řízení latence a čerstvosti dat
- Plánujte scraping podle rychlosti tématu: U breaking news nastavte běh každých 15–30 minut (v souladu s ). U pomalejších témat stačí denně nebo po hodinách.
- Sledujte rozdíl mezi publikací a stažením: Měřte, jak dlouho trvá od publikace článku do jeho získání. Pokud se zpoždění zvětšuje, může jít o blokace nebo zpomalení.
- Opakujte scraping kvůli „tichým úpravám“: Články se často po vydání upravují. Naplánujte druhý běh po 24 hodinách, abyste zachytili opravy nebo nenápadné editace ().
Limity API a proměnlivost zdrojů
- Respektujte kvóty API: Pokud používáte news API, hlídejte rate limit – rozložte požadavky v čase a kde to jde, cacheujte výsledky ().
- Deduplikace a kanonizace: Zprávy se často objeví na více URL nebo se aktualizují. Ukládejte canonical URL a používejte hashe (např. titulek + datum), abyste se vyhnuli duplicitám ().
- Dynamický obsah: U webů s nekonečným scrollováním nebo lazy loadingem používejte nástroje, které umí dynamické vykreslení, a hlídejte změny layoutu ().
Chytrá analýza dat ze zpráv: role AI a machine learningu
Extrakce zpráv je teprve start. Skutečná hodnota vzniká až analýzou a následnou akcí – a právě tady AI a machine learning opravdu září.
- Extrakce entit: Pomocí NLP vytáhněte osoby, organizace a místa zmíněná v článku ().
- Klasifikace témat: Automaticky tagujte články podle tématu, sentimentu nebo naléhavosti – pro chytřejší dashboardy a alerty ().
- Shlukování událostí: Seskupujte duplicitní nebo související články napříč médii, abyste viděli celek (ne jen záplavu podobných titulků).
- Personalizace a cílení: Využijte data ze zpráv v reálném čase pro segmentaci publika, lepší cílení reklamy nebo doporučování obsahu – a zvyšujte engagement i ROI.
Například PR týmy díky analýze zpráv v reálném čase odhalí vznikající krize dřív, než se rozjede naplno, a obchodní týmy obohacují seznamy kontaktů o „spouštěcí události“ jako investiční kola nebo nábory do vedení.
Checklist osvědčených postupů pro automatizovanou extrakci zpráv
Tady je rychlý checklist, aby vaše pipeline běžela spolehlivě:
| Osvědčený postup | Proč je důležitý | Jak ho zavést |
|---|---|---|
| Plánujte časté scrapování | Minimalizuje zpoždění, zachytí breaking news | Přizpůsobte frekvenci rychlosti tématu (např. každých 15 min u rychlých rubrik) |
| Používejte AI extrakci | Lépe zvládá změny layoutu, zkracuje nastavení | Nástroje jako Thunderbit, Diffbot, Zyte API |
| Deduplikujte a kanonizujte | Zabrání duplicitním alertům, udrží data čistá | Ukládejte canonical URL, používejte hashe pro deduplikaci |
| Sledujte kvalitu extrakce | Odhalí chybějící pole, drift nebo výpadky | Měřte % kompletních záznamů, zpoždění a chybovost |
| Respektujte právní/compliance hranice | Snižuje právní riziko, buduje důvěru | Preferujte oficiální API/feedy, kontrolujte podmínky, minimalizujte osobní data |
| Exportujte do strukturovaných formátů | Umožní navazující analýzu | CSV, Excel, Sheets, Notion, Airtable |
| Plánujte opakované běhy kvůli editacím | Zachytí změny po publikaci | Vraťte se k článkům po 24 h / 1 týdnu (model GDELT) |
| Zabezpečte pipeline | Chrání citlivá data | Šifrování, řízení přístupu, prověřené nástroje |
Jak postavit robustní workflow pro automatizovanou extrakci zpráv
Chcete si postavit vlastní „černou skříňku“ na data ze zpráv? Tady je postup krok za krokem:
- Vyberte zdroje: Sepište weby, blogy nebo API, které chcete sledovat.
- Nastavte extrakci: V Thunderbit (nebo jiném nástroji) definujte pole (s „AI Suggest Fields“ je to otázka chvilky).
- Naplánujte scraping: Frekvenci nastavte podle rychlosti tématu – hodinově pro breaking news, denně pro pomalejší rubriky.
- Obohacení přes podstránky: Ke každému titulku stáhněte celý článek včetně textu, entit a tagů.
- Deduplikace a normalizace: Ukládejte canonical URL, hashujte záznamy a sjednoťte formáty polí.
- Export a integrace: Pošlete strukturovaná data do Excelu, Google Sheets, Airtable nebo Notion.
- Monitoring a úpravy: Sledujte kvalitu extrakce, hlídejte změny layoutu a podle potřeby upravujte.
- Dodržujte pravidla: Kontrolujte podmínky, respektujte robots.txt a minimalizujte osobní data.
Jako vizuální tok si to představte takto:
Zdroje → Extrakce (AI pole) → Obohacení podstránek → Deduplikace → Export → Analýza/Alerty → Monitoring
Závěr a hlavní poznatky
Automatizovaná extrakce zpráv už není jen „nice-to-have“ – je to nutnost pro každého, kdo chce být napřed ve světě, kde se zprávy lámou (a mění) po minutách. Když budete držet osvědčené postupy a vyberete správné nástroje, proměníte požární hadici digitálních zpráv ve stabilní proud strukturovaných, akceschopných informací.
Hlavní takeaway:
- Rozsah a rychlost online zpráv vyžadují automatizaci – ruční monitoring to nezvládne.
- Nástroje pro automatizovanou extrakci šetří čas i náklady a umožní malým týmům dosáhnout pokrytí jako mnohem větší organizace.
- Správná volba nástroje je o rovnováze mezi jednoduchostí, bezpečností a přizpůsobivostí – Thunderbit vyniká AI jednoduchostí a exportem v reálném čase.
- Workflow stavte na čerstvosti dat, deduplikaci, compliance a kontrole kvality, aby byla data spolehlivá a použitelná.
- AI a machine learning přidávají další vrstvu hodnoty – chytřejší cílení, personalizaci i rozhodování.
Pokud stále kopírujete titulky ručně nebo čekáte, až Google Alerts „doběhne“, je čas posunout se dál. a uvidíte, jak snadná může automatizovaná extrakce zpráv být. Další tipy, workflow a detailní návody najdete na .
Nejčastější dotazy (FAQ)
1. Co je automatizovaná extrakce zpráv a jak funguje?
Automatizovaná extrakce zpráv je proces, kdy software sbírá zpravodajské články a převádí je do strukturovaných dat (např. tabulky nebo JSON) pro analýzu, vyhledávání nebo alerty. Nástroje jako Thunderbit využívají AI k rozpoznání klíčových polí (titulek, čas, autor, text) a automaticky je vytěží z webových stránek nebo API.
2. Proč jsou data ze zpráv v reálném čase pro firmy tak důležitá?
Data v reálném čase umožňují rychle reagovat na tržní události, PR krize nebo kroky konkurence. Ať jste v obchodu, PR nebo výzkumu, aktuální zprávy znamenají rychlejší a lepší rozhodování a náskok před konkurencí.
3. Jak Thunderbit usnadňuje scraping zpráv netechnickým uživatelům?
Thunderbit nabízí jednoduchý dvoukrokový postup: popíšete, jaká data chcete, a AI navrhne pole. Díky funkcím jako Subpage Scraping a okamžitý export do Excelu nebo Google Sheets zvládnou i netechnické týmy postavit spolehlivou pipeline během pár minut.
4. Jaké jsou právní a compliance aspekty scrapingu zpráv?
Vždy si projděte podmínky použití cílových webů, preferujte oficiální API nebo feedy, pokud existují, a respektujte robots.txt. Bez povolení nescrapujte obsah za přihlášením nebo paywallem a minimalizujte sběr osobních údajů, abyste byli v souladu se zákony o ochraně soukromí.
5. Jak zajistit, aby workflow pro extrakci zpráv zůstalo dlouhodobě spolehlivé?
Plánujte pravidelné běhy, sledujte kvalitu extrakce a používejte nástroje, které se umí přizpůsobit změnám layoutu (např. AI extrakce v Thunderbit). Deduplikujte záznamy, měřte zpoždění mezi publikací a extrakcí a nastavte upozornění na výpadky nebo chybějící pole, aby pipeline zůstala zdravá a aktuální.
Zjistit více