

Před několika měsíci se nás jeden uživatel zeptal na otázku, která mě zastavila uprostřed doušku kávy: „Když budu stahovat veřejné ceny produktů z Coupangu, skončím u korejského soudu?“ Upřímně, neměl jsem po ruce jistou jednovětou odpověď — a stejně na tom byla i většina právních průvodců, které jsem našel online.
Ta otázka mi zůstala v hlavě, protože ji si tiše googlí každý týden tisíce provozovatelů e-shopů, obchodních týmů i zakladatelů SaaS firem. Globální trh služeb web scrapingu dosáhl v roce 2024 zhruba 1,03 miliardy USD a rychle roste. Více firem než kdy dřív sbírá webová data — a čím dál víc z nich přemýšlí, kde přesně v Koreji leží právní hranice. Korea scraping přímo nezakazuje.
Ale podle toho, co scrapujete, jak to scrapujete a proč, mohou se uplatnit čtyři hlavní zákony. Nejznámější případ, na který všichni odkazují, je rozhodnutí korejského Nejvyššího soudu ve věci Yanolja (2021Do1533, rozhodnuto 12. května 2022), který v trestní rovině zprostil viny nástroj konkurenta pro scraping — a pak v samostatném civilním řízení uložil stejné společnosti škodu ve výši zhruba 1 miliardy KRW. Právě tenhle dvojí výsledek je to nejdůležitější, co by měl laik o korejském právu týkajícím se scrapingu vědět, a je páteří tohoto průvodce. Právnický titul nepotřebujete — stačí praktický rámec rizik, který můžete opravdu použít.
Obtížnost: Začátečník (není třeba právní ani technické znalosti)
Čas potřebný: přibližně 15 minut čtení; průběžná reference
Co budete potřebovat: Základní představu o tom, co web scraping dělá (pokud si to chcete osvěžit, podívejte se na náš článek co je web scraping)
Je web scraping v Koreji legální? Stručná odpověď
Samotný web scraping v Koreji nelegální není. Je to neutrální technologie — podobně jako webový prohlížeč nebo vzorec v tabulce. Korejské soudy se dlouhodobě nezaměřují na nástroj, ale na chování spojené s jeho používáním.
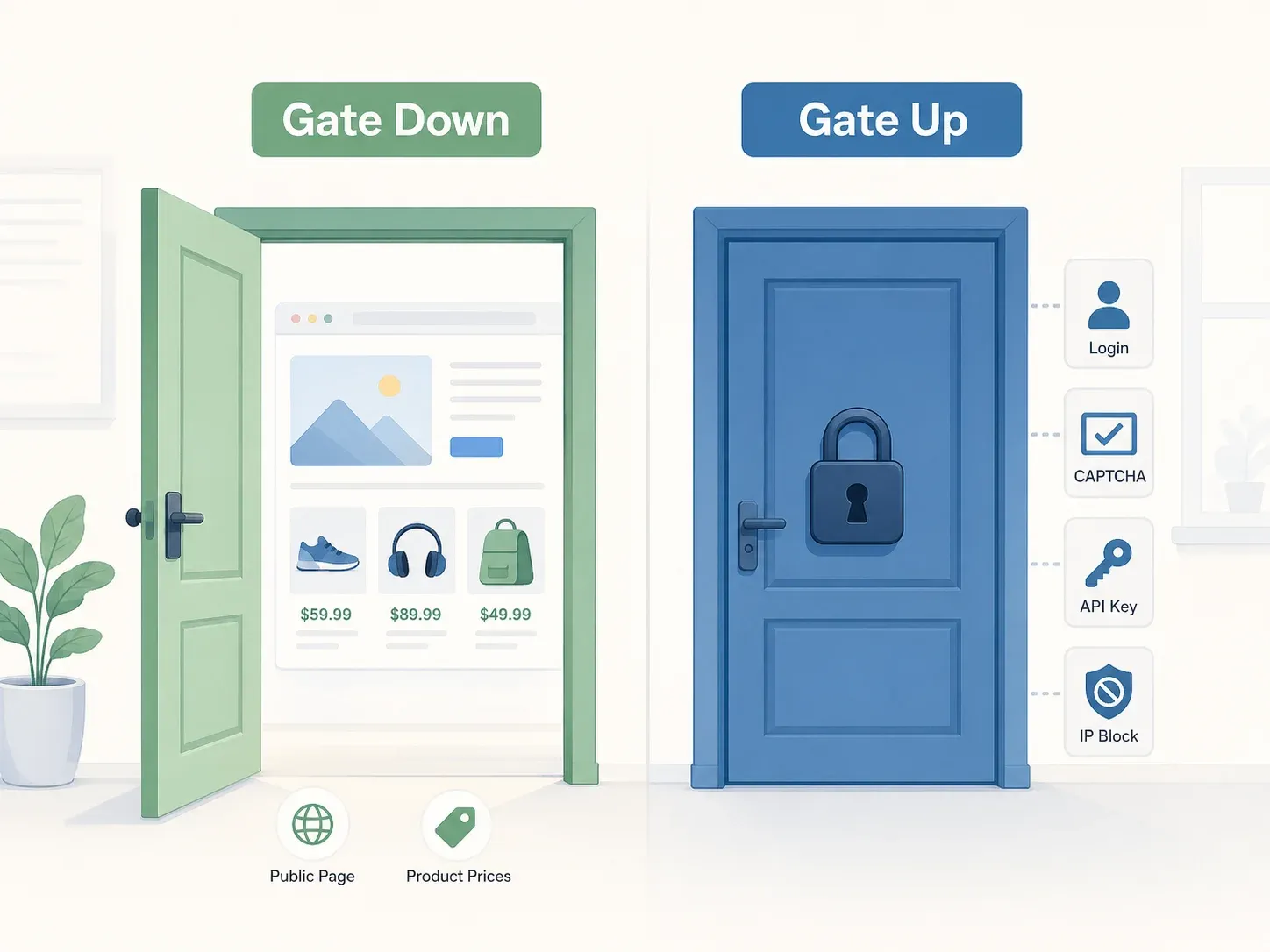
Nejlepší mentální model nabízí rozhodnutí Nejvyššího soudu ve věci Yanolja: princip „brána nahoře vs. brána dole“. Pokud web nemá žádná objektivní omezení přístupu — žádnou přihlašovací bránu, CAPTCHA, požadavek na API klíč ani blokování IP adres — je brána „dole“ a přístup k veřejně dostupným datům obvykle nepředstavuje trestný čin podle korejského zákona o informačních a komunikačních sítích (ICNA). Soud se konkrétně zabýval tím, zda přístup omezovaly „ochranné prostředky, podmínky použití a další objektivně zjevné okolnosti“, a dospěl k závěru, že server API Yanolja byl volně dostupný přes veřejnou aplikaci.
Ale „není to trestné“ neznamená „je to bez rizika“.
Civilní odpovědnost je úplně jiná otázka. Trestnímu stíhání se můžete vyhnout a přesto čelit náhradě škody ve výši jedné miliardy wonů. Případ Yanolja to ukázal bolestivě jasně.
Na web scraping se mohou vztahovat čtyři korejské zákony:
- ICNA (Information and Communications Network Act) — pravidlo „zákaz vniknutí“
- Autorský zákon — práva výrobce databáze
- PIPA (Personal Information Protection Act) — pravidla pro sběr osobních údajů
- UCPA (Unfair Competition Prevention Act) — zastřešující pravidlo „neparazitovat“
Zbytek tohoto průvodce mapuje tyto zákony na reálné situace, abyste zjistili, kam váš scraping projekt skutečně spadá.
Zeleno-žluto-červený rámec rizik pro web scraping v Koreji
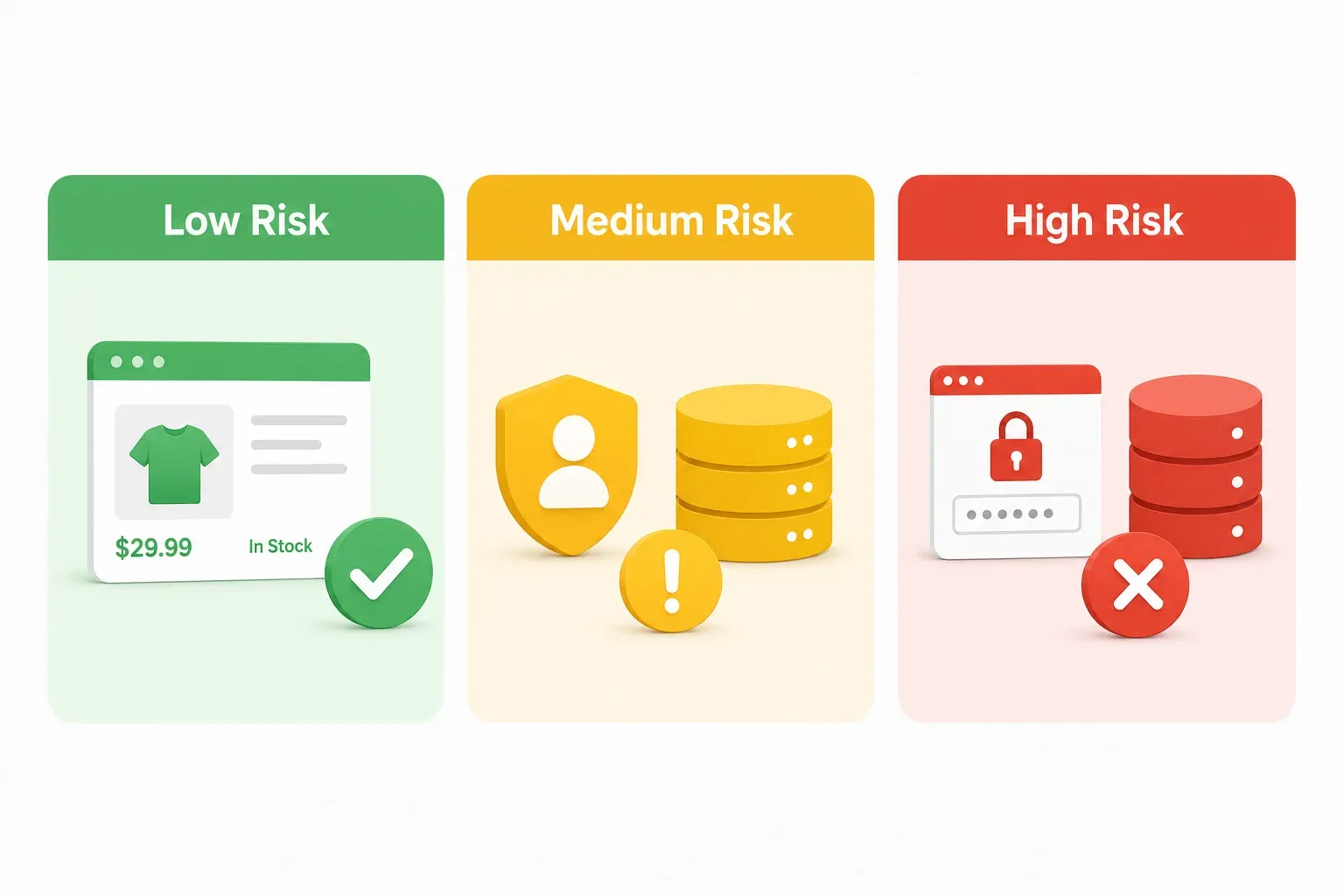
Každý právní článek, který jsem ke korejskému scrapingu našel, působí, jako by byl napsaný pro advokáty. Pokud jste manažer e-shopu nebo zakladatel SaaS firmy, nepotřebujete čtyřicetistránkovou právní analýzu — potřebujete rychlý způsob, jak odhadnout riziko, než projekt spustíte. Představte si to jako semafor. Zelená znamená jít dál (s běžnou opatrností). Žlutá znamená zpomalit a zkontrolovat zpětná zrcátka. Červená znamená zastavit a zavolat právníkovi.
Zelená zóna: Scénáře scrapingu s nízkým rizikem
| Scénář | Úroveň rizika | Klíčový zákon | Proč |
|---|---|---|---|
| Scraping veřejných produktových nabídek (bez přihlášení, bez CAPTCHA) | 🟢 Nízké | ICNA, autorský zákon | Rozhodnutí Yanolja: žádné omezení přístupu = žádné porušení ICNA; faktická data (ceny, dostupnost) nejsou tvůrčí projev |
| Scraping veřejných cen pouze pro interní analytiku | 🟢 Nízké | UCPA, autorský zákon | Faktická data, omezený rozsah, žádná konkurenční redistribuce |
| Sběr nefyzických, nechráněných faktů z veřejných stránek | 🟢 Nízké | ICNA, autorský zákon | Nebylo obejito žádné omezení přístupu; jednotlivá fakta nejsou chráněna |
Tuto zónu ukotvuje trestní rozhodnutí ve věci Yanolja. Nejvyšší soud neshledal zásah do ICNA, protože server API byl volně dosažitelný — běžní uživatelé k němu mohli přistupovat přes aplikaci s členstvím i bez něj a žádná samostatná technická ochrana přístupu k API neexistovala.
Pro uživatele Thunderbit je to ideální scénář. Pokud scrapujete veřejné e-commerce nebo realitní weby v cloudovém režimu — sbíráte názvy produktů, ceny, dostupnost nebo metadata nabídek a zároveň vynecháváte osobní údaje — obvykle se pohybujete v zelené zóně. (To ale neznamená „vždy“, a nuance vysvětlím níže.)
Vyzkoušejte Thunderbit pro scraping veřejných dat
Žlutá zóna: Scénáře scrapingu se středním rizikem
| Scénář | Úroveň rizika | Klíčový zákon | Proč |
|---|---|---|---|
| Scraping osobních údajů (jména, e-maily, telefonní čísla) i z veřejných stránek | 🟡 Střední | PIPA, ICNA | PIPA platí bez ohledu na veřejnou viditelnost; novela z roku 2023 zpřísnila pravidla pro souhlas |
| Scraping velkých objemů, které mohou tvořit „podstatnou část“ databáze konkurenta | 🟡 Střední | Autorský zákon, UCPA | Kvantitativní i kvalitativní test podle korejského práva |
| Ignorování signálů robots.txt | 🟡 Střední | Důkaz zlé víry | Sice nejde samo o sobě o trestný čin, ale u soudu to může hrát proti vám |
| Scraping veřejných dat a jejich přímé využití ke konkurenci zdroji | 🟡 Střední | UCPA | Parazitování na investicích jiné platformy |
Osobní údaje jsou největším spouštěčem žluté zóny.
I když je telefonní číslo nebo e-mail viditelný na veřejné webové stránce, PIPA se stejně uplatní. Reforma PIPA z roku 2023 rozšířila práva subjektů údajů a zpřísnila požadavky na souhlas. A v roce 2024 vydala korejská Komise pro ochranu osobních údajů (PIPC) pokyny věnované veřejně dostupným osobním údajům v kontextu AI a sběru dat — a jasně uvedla, že samotná veřejná dostupnost není obecné povolení.
Na objemu také záleží. Nejvyšší soud ve věci Yanolja uvedl, že o tom, zda jste zkopírovali „podstatnou část“ databáze, rozhodují kvantitativní i kvalitativní faktory. Porovnejte zkopírovanou část s celou databází a zeptejte se, zda odráží podstatnou investici výrobce.
Červená zóna: Scénáře scrapingu s vysokým rizikem
| Scénář | Úroveň rizika | Klíčový zákon | Proč |
|---|---|---|---|
| Scraping za přihlašovací bránou nebo obcházení přístupových kontrol | 🔴 Vysoké | ICNA čl. 48 | „Brána nahoře“ = neoprávněný přístup; vysoké riziko stíhání |
| Obcházení CAPTCHA, IP blokací nebo systémů detekce botů | 🔴 Vysoké | ICNA čl. 48(4) | Novela z roku 2024 výslovně cílí na nástroje a zařízení k obejití ochrany |
| Kopírování a další prodej celé databáze konkurenta | 🔴 Vysoké | Autorský zákon (práva k databázi), UCPA | Podstatné rozmnožení + komerční parazitování |
| Sběr osobních údajů bez právního základu pro marketing nebo oslovení | 🔴 Vysoké | PIPA | Až 5 let / pokuta 50 mil. KRW; správní sankce až 3 % obratu |
Nově přidané ustanovení v ICNA z roku 2024 — článek 48(4) — nyní výslovně zakazuje instalaci, přenos nebo distribuci programů či technických zařízení, která bez legitimního důvodu obcházejí „běžné ochranné nebo ověřovací postupy“.
Samostatně pak rozhodnutí Nejvyššího soudu z listopadu 2024 (2021Do5555) posílilo závěr, že neoprávněný zásah do sítě může existovat i bez fyzického poškození ochranných prvků. Stačí použít cizí identifikátory nebo nesprávné příkazy, aby se obešly limity přístupu.
Čtyři korejské zákony, které se na web scraping vztahují
| Zákon | Co chrání | Kdy se u scraperů uplatní |
|---|---|---|
| ICNA článek 48 | Stabilitu sítě, oprávnění k přístupu | Obcházení loginu, CAPTCHA, ověření, IP blokací, limitů API klíče |
| Autorský zákon (čl. 93) | Tvůrčí díla + práva výrobce databáze | Kopírování expresivního obsahu, obrázků nebo celé/podstatné části databáze |
| PIPA | Osobní údaje, práva subjektů údajů | Sběr jmen, telefonních čísel, e-mailů, ID — i z veřejných stránek |
| UCPA (čl. 2(1)(k) a (m)) | Férová soutěž, komerčně cenná data | Parazitování na datové investici jiné platformy pro vlastní konkurenční byznys |
ICNA článek 48: Pravidlo „zákaz vniknutí“
ICNA článek 48(1) říká, že nikdo nesmí vstoupit do informační a komunikační sítě „bez legitimního oprávnění k přístupu nebo nad rámec povoleného oprávnění k přístupu“. Ve světě scrapingu to znamená: pokud má web přístupová omezení, která obcházíte, porušujete zákon. Pokud žádná omezení nejsou — veřejná stránka, bez přihlášení — jste pravděpodobně v pořádku.
Trest za porušení může podle ICNA článku 71 činit až pět let odnětí svobody nebo pokutu do 50 milionů KRW.
Jeden důležitý detail: korejský Nejvyšší soud dlouhodobě odlišuje omezení v podmínkách používání od omezení přístupu. Podmínky aplikace Yanolja omezovaly komerční opětovné využití a zakazovaly automatizované programy, které zatěžovaly server, ale soud dospěl k závěru, že tyto klauzule objektivně neomezovaly přístup k samotnému serveru API.
Autorský zákon: Práva výrobce databáze
Korejský autorský zákon chrání výrobce databází odděleně od autorských práv k jednotlivému obsahu. Podle článku 93 je rozmnožování „všech nebo podstatné části“ databáze nezákonné — i když jednotlivé datové body jsou veřejná fakta.
Test je kvantitativní (kolik jste zkopírovali vzhledem k celku?) i kvalitativní (odráží zkopírovaná část podstatnou investici výrobce do budování, ověřování nebo údržby databáze?). Opakované nebo systematické kopírování menších částí se také může počítat, pokud v praxi dosáhne stejného výsledku jako kopírování podstatné části.
Trest za porušení práv výrobce databáze: až tři roky nebo 30 milionů KRW podle článku 136(2)(3). Zákonné náhrady škody podle článku 125-2 umožňují až 10 milionů KRW za dílo, nebo 50 milionů KRW za dílo při úmyslném porušení za účelem zisku.
PIPA: Zákon o ochraně osobních údajů
PIPA upravuje sběr osobních údajů — jmen, kontaktů, identifikátorů — i tehdy, jsou-li veřejně viditelné. Reforma z roku 2023 byla významná: rozšířila práva subjektů údajů, zpřísnila požadavky na souhlas, zavedla pravidla pro automatizované rozhodování a stanovila správní sankce až do 3 % celkových tržeb za vybraná porušení.
Průvodce PIPC z roku 2024 k veřejným datům a AI výslovně zmiňuje data získaná prostřednictvím „web crawlingu a scrapingu“ v kontextu veřejně dostupných osobních údajů. Pokyny objasňují, že v některých situacích může být právním základem oprávněný zájem, ale organizace musí provést vyvážení zájmů, zavést ochranná opatření, chránit práva subjektů údajů a mít odpovídající governance.
A trend je přísnější. V březnu 2026 korejský tisk informoval o novele PIPA, která zvyšuje maximální sankce za závažná opakovaná pochybení při úniku dat až na 10 % obratu, s účinností později v roce 2026.
UCPA: Zastřešující pravidlo proti nekalé soutěži
UCPA je zákon, který v civilní části případu Yanolja dopadl na společnost GC Company. Současný zákon obsahuje dvě relevantní ustanovení:
- Čl. 2(1)(k): pokrývá nekalé užití elektronicky shromážděných a spravovaných technických nebo obchodních dat, která nejsou tajná
- Čl. 2(1)(m): širší zastřešující ustanovení pro využití výsledků práce jiné osoby dosažených podstatnou investicí nebo úsilím, pro vlastní podnikání bez svolení a v rozporu s férovými obchodními praktikami
UCPA je u těchto ustanovení pouze civilní — bez trestních sankcí — ale může vést k zákazu činnosti podle článku 4, náhradě škody podle článku 5 a dokonce k trojnásobné náhradě škody v určených úmyslných případech podle článku 14-2. Civilní část případu Yanolja podle tohoto rámce přiznala zhruba 1 miliardu KRW.
Případ Yanolja: Proč můžete v trestní rovině vyhrát, ale v civilní prohrát
To je ten případ, kterému musí rozumět každý byznysový uživatel v Koreji. Řeknu ho jako jeden příběh, protože přesně tak se odehrál — a protože ten rozdělený výsledek je na tom to podstatné.
Co se stalo: GC Company scrapovala cestovní data Yanolja
GC Company provozovala konkurenční online cestovní platformu. Vyvinula vlastní crawler, který přistupoval k serveru API aplikace Baro Reservation od Yanolja, zjistil adresy API a příkazy požadavků a posílal je na server. Scraper sbíral informace o ubytování — názvy partnerů, adresy, ceny, dostupnost a obrázky. GC Company tato data používala interně pro marketing a konkurenční pozicování.
Yanolja podala trestní oznámení i civilní žalobu.
Trestní verdikt: Nevinný ve všech bodech (Nejvyšší soud 2021Do1533)
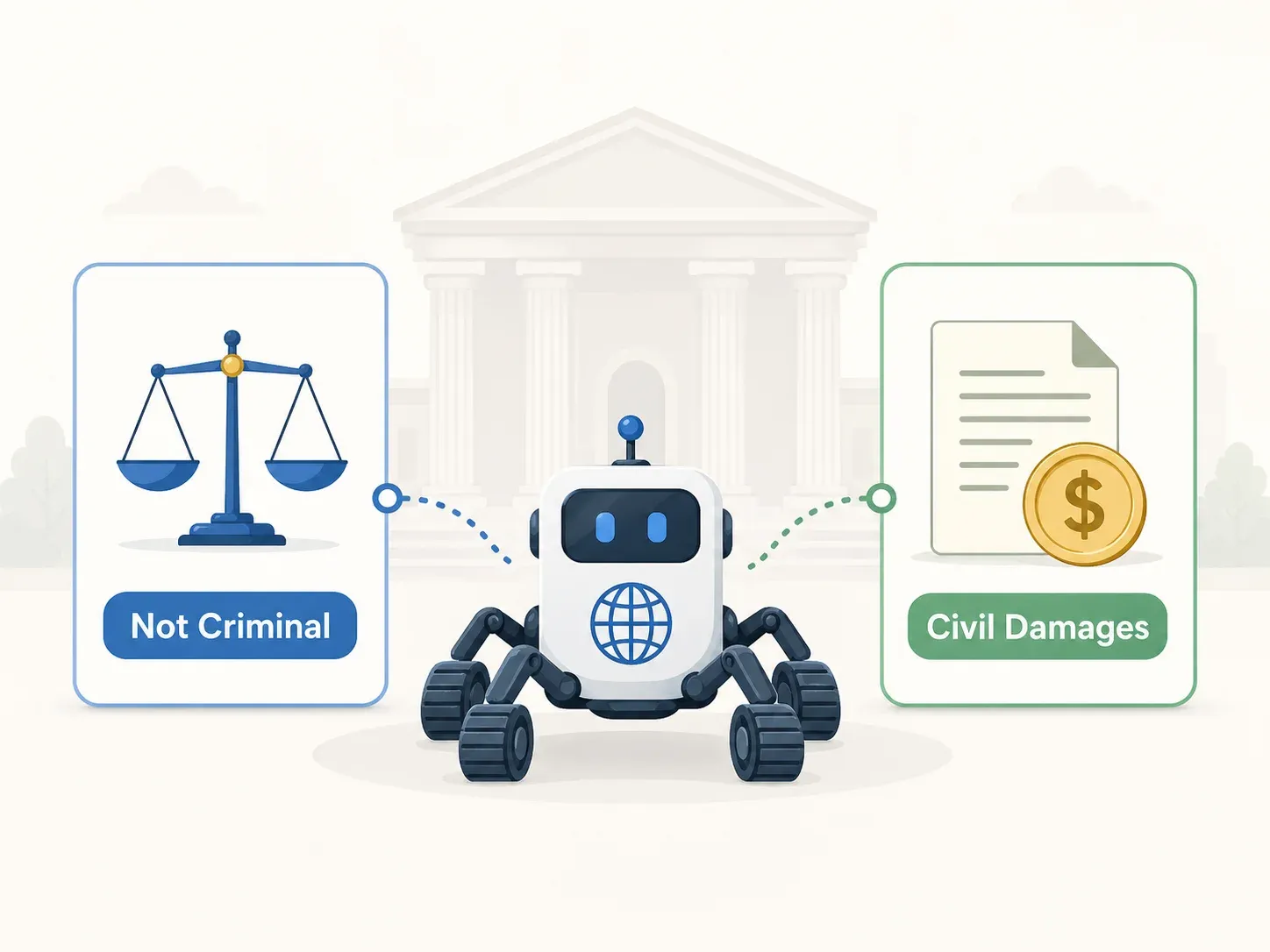
Nejvyšší soud 12. května 2022 potvrdil zproštění viny odvolacím soudem ve všech třech bodech:
- ICNA čl. 48 (vniknutí): Neexistovala žádná omezení přístupu. Server API byl veřejně dostupný přes prohlížeč i mobilní aplikaci. Nebylo použito žádné technické blokování. Podmínky používání omezovaly užití, ne přístup.
- Autorský zákon (práva výrobce databáze): Obžalovaní nereprodukovali „vše nebo podstatnou část“ databáze. Zkopírovaná data byla už veřejně známá a důkazy neprokázaly, že kopírovaná část odrážela podstatnou investici Yanolja.
- Trestní zákon čl. 314 (narušení podnikání): Nebylo prokázáno skutečné narušení provozu serveru API Yanolja. Nedošlo ke změně dat. Nebyl prokázán úmysl pro narušení podnikání.
Citovatelná zásada zní: omezení přístupu musí být posuzována podle „ochranných opatření, podmínek použití a dalších objektivně zjevných okolností“. Když je brána dole, projít jí není vniknutí.
Civilní verdikt: Náhrada škody 1 miliarda KRW podle UCPA
A tady se příběh láme. Ústřední okresní soud v Soulu — a poté i Soulský vrchní soud (spis 2021Na2034740, rozhodnuto 25. srpna 2022) — dospěly k závěru, že GC Company porušila zastřešující ustanovení UCPA. Soud přiznal přibližně 1 miliardu KRW (asi 800 tisíc USD) jako náhradu škody a nařídil ukončení dalšího kopírování dat.
Odůvodnění: databáze ubytování Yanolja měla komerční hodnotu a odrážela podstatnou investici — sběr, ověřování a aktualizaci údajů o ubytování. GC Company na této investici parazitovala. Civilní rozsudek byl na úrovni Soulského vrchního soudu pravomocně potvrzen.
Praktický závěr: Zproštění viny v trestním řízení neznamená civilní bezpečí
Tohle je nejvíc proti intuici působící lekce z korejského práva o scrapingu. Trestně legální přístup nechrání před civilně nekalým využitím. „Mohou mě stíhat?“ a „Můžou mě žalovat?“ jsou dvě různé otázky s potenciálně opačnými odpověďmi.
Pro byznys uživatele: i když je vaše metoda scrapingu z trestního hlediska jasně v zelené zóně, vaše využití dat — zejména pokud přímo konkuruje zdroji — určuje civilní riziko.
Korea vs. USA vs. EU: Jak se pravidla pro web scraping srovnávají
Nenašel jsem jiného průvodce, který by to shrnul do jedné tabulky — což je zvláštní, když uvážíte, kolik firem scrapuje napříč hranicemi.
| Oblast | Jižní Korea | Spojené státy | EU / EHP |
|---|---|---|---|
| Hlavní zákon | ICNA čl. 48, autorský zákon | CFAA (18 U.S.C. §1030), státní zákony | GDPR, směrnice o databázích (96/9/ES) |
| Přelomový případ | Yanolja v. GC Company (Nejvyšší soud 2021Do1533, 2022) | hiQ v. LinkedIn (9. okruh, 2022), Van Buren v. US (2021) | Ryanair v. PR Aviation (SDEU C-30/14, 2015) |
| Scraping veřejných dat | Legální, pokud neexistují objektivní překážky přístupu („brána dole“) | Legální podle logiky hiQ (veřejná data); Van Buren zúžil CFAA | Záleží na právech k databázi, smlouvě, autorském právu, GDPR a právu členského státu |
| Pravidla pro osobní údaje | PIPA (po novele 2023) — souhlas nebo právní základ | Sektorové: CCPA (Kalifornie), státní zákony o ochraně soukromí | GDPR — přísný souhlas / oprávněný zájem; max. pokuta 20 mil. € nebo 4 % globálního obratu |
| Porušení ToS = trestný čin? | Ne (soudy drží ToS ≠ porušení ICNA) | Ne (Van Buren 2021: ToS ≠ CFAA) | Obvykle ne, ale může jít o porušení smlouvy (Ryanair) |
| Ochrana databází | Práva výrobce databáze podle autorského zákona | Žádné federální právo k databázi | Sui generis právo k databázi |
| Maximální trestní sankce | Až 5 let / 50 mil. KRW (ICNA) | Až 10 let / 250 tis. USD (CFAA) | Liší se podle členského státu |
Hlavní rozdíly, které jsou pro váš byznys důležité
- Korea nemá obecnou výjimku pro text and data mining (TDM) jako směrnice EU DSM. Pokud trénujete AI modely na scrapovaných korejských datech, nemáte zákonnou výjimku.
- Zastřešující ustanovení UCPA v Koreji je širší a méně předvídatelné než americké právo nekalé soutěže. Civilní výsledek ve věci Yanolja by bylo mnohem těžší zopakovat podle amerického práva.
- Všechny tři jurisdikce se shodují: samotné porušení podmínek používání není trestným činem.
- Korejská ochrana databází je zákonná (podobně jako v EU), zatímco USA nemají obecné federální právo k databázi. To dává korejským platformám více civilních nástrojů.
- Když scrapujete napříč hranicemi, platí nejpřísnější relevantní zákon. Projekt zasahující korejská, americká i evropská data musí splnit všechny tři režimy.
Scénáře podle odvětví: Je web scraping v Koreji legální pro váš obor?
Rizikový profil se podle odvětví dramaticky liší a žádný průvodce, který jsem našel, nemapoval korejské právo pro scraping na konkrétní segmenty. Proto jsem si to musel poskládat sám.
E-commerce: Sledování cen a produktová data

Scraping veřejných cen produktů z Coupangu, Gmarketu nebo 11Street je nejčistší příklad v zelené zóně — držte se faktických polí (cena, dostupnost, název produktu), vyhýbejte se částem dostupným jen po přihlášení, neobcházejte technické blokace a používejte data interně pro benchmarking.
Riziko roste, když scrapujete produktové popisy (tvůrčí obsah → autorské právo), kontaktní údaje prodejců (PIPA), obrázky (autorské právo) nebo celý katalog (práva výrobce databáze + UCPA).
Nenalezl jsem žádný zásadní korejský spor o scraping v e-commerce, který by se dal srovnat s Yanolja. Vyspělejší precedens je v cestovním ruchu a náboru — ale absence sporů neznamená absenci rizika.
Thunderbit Scheduled Scraper a cloudový režim scrapingu jsou přesně pro tenhle scénář: pravidelné kontroly cen a zásob na veřejných stránkách, přičemž funkce AI Suggest Fields vám umožní vybrat požadované sloupce a vyloučit osobní údaje.
Reality: Nabídky nemovitostí
Reality jsou přirozeně v žluté zóně. Nabídky na platformách jako Zigbang nebo Naver Real Estate kombinují faktická data (cena, plocha, čtvrť) s jmény makléřů, telefonními čísly kanceláří, mobilními čísly, fotografiemi a kurátorovanými databázemi platformy.
Scraping veřejných údajů o nemovitostech může být méně rizikový. Ale sběr kontaktních sloupců makléřů okamžitě spouští PIPA — a scraping všech nabídek v regionu už začíná vypadat jako podstatné kopírování databáze.
Jak riziko zmírnit: vynechte osobní sloupce, omezte geografický rozsah, zdokumentujte legitimní obchodní účel, respektujte limity požadavků a nereplikujte konkurenční službu s nabídkami. AI v Thunderbit můžete nastavit tak, aby extrahovala jen potřebná pole o nemovitosti — cena, metry čtvereční, lokalita — a přeskočila osobní kontaktní údaje.
Nábor: Pracovní nabídky
Nábor je bez debat vysoce rizikový sektor. Korea má přímý precedent: JobKorea v. Saramin. Saramin scrapoval databázi pracovních nabídek JobKorea a byl shledán odpovědným za porušení práv k databázi i nekalou soutěž. Data o pracovních pozicích obvykle kombinují investice platformy (kurátorované, ověřené nabídky), masové kopírování databáze a osobní nebo kontaktní údaje náborářů.
Moje doporučení: obecně se vyhněte scrapování konkurenční pracovní platformy za účelem vytvoření nebo obohacení rivalní databáze pracovních nabídek. Pokud je use case úzký, dejte si právní kontrolu před sběrem, minimalizujte objem, odstraňte osobní kontakty a výsledky dál neredistribuujte.
Kompletní přehled sankcí: Co vám v Koreji hrozí, když se scraping zvrtne
| Korejský zákon | Typ porušení | Max. trestní sankce | Max. civilní/správní náprava | Klíčová změna 2023–2026 |
|---|---|---|---|---|
| ICNA čl. 48 | Neoprávněný přístup / zásah | 5 let / pokuta 50 mil. KRW | Náhrada škody + soudní zákaz | 2024: přidán čl. 48(4), cílí na nástroje k obcházení ochrany |
| Autorský zákon (práva k databázi, čl. 93) | Podstatné rozmnožení databáze | 3 roky / pokuta 30 mil. KRW | Zákonné náhrady až 50 mil. KRW / dílo (úmysl za účelem zisku) | — |
| PIPA | Nezákonný sběr osobních údajů | 5 let / pokuta 50 mil. KRW | Správní sankce až 3 % celkových tržeb; možná hromadná žaloba | Reforma 2023; 2024 pokyny k AI pro veřejná data; trend 2026 směrem k 10 % u opakovaných úniků |
| UCPA čl. 2(1)(k)/(m) | Nekalé získání / užití dat | Jen civilní (u zastřešujícího pravidla bez trestu) | Náhrada škody + soudní zákaz; trojnásobná náhrada pro určené úmyslné případy | 2022: Data Framework Act posílil ustanovení |
| Trestní zákon čl. 314 | Narušení podnikání technickými prostředky | 5 let / pokuta 15 mil. KRW | — | Yanolja: nebylo prokázáno skutečné narušení |
Klíčový bod: trestní a civilní řízení běží nezávisle. Můžete čelit oběma současně — a v jednom vyhrát, zatímco v druhém prohrát.
Váš 10bodový compliance checklist pro web scraping v Koreji
Tady je deset otázek ano/ne, které si projděte, než začnete jakýkoli scraping projekt. Vytiskněte si to, uložte do záložek, přilepte na monitor — cokoli funguje.
- Požaduje cílový web pro přístup k požadovaným datům přihlášení? Pokud je potřeba login, token nebo účet, riziko prudce míří k ICNA čl. 48.
- Nejsou zde žádná technická omezení přístupu? CAPTCHA, IP blokace, API klíče, limity požadavků a bot bariéry jsou silné signály červené zóny.
- Zkontrolovali jste robots.txt webu? Sám o sobě není v korejské judikatuře právně závazný, ale je to užitečný důkaz očekávání provozovatele webu a vaší dobré víry.
- Sbíráte nějaké osobní údaje? Pokud jsou ve hře jména, telefonní čísla, e-maily, ID nebo individuální kontaktní údaje, je nutná analýza PIPA.
- Kopírujete „podstatnou část“ databáze webu? Zvažte kvantitativní i kvalitativní otázku — kolik toho je a odráží zkopírovaná část investici zdroje?
- Definovali jste si účel? Interní analytika je méně riziková než redistribuce nebo budování konkurenční databáze. (Yanolja ale ukazuje, že interní konkurenční využití není úplný štít.)
- Zdokumentovali jste si legitimní obchodní účel písemně? Dokumentace pomáhá u vyvažování oprávněného zájmu podle PIPA a jako důkaz dobré víry.
- Odstranili jste nebo anonymizovali osobní údaje před uložením či použitím? Vyloučení kontaktních údajů často posouvá scraping realit, náboru a adresářů z nejnebezpečnějšího vzorce PIPA.
- Používáte rozumné intervaly požadavků? Vyhněte se přetížení serveru — riziko podle Trestního zákona čl. 314 a ICNA čl. 48(3) roste, když scraping narušuje provoz služby.
- Konzultovali jste korejského právníka pro projekty s vysokým objemem, komerční nebo přeshraniční? Mohou se současně uplatnit korejské zákony i GDPR / americké zákony na ochranu soukromí nebo přístupu k počítačovým systémům.
⚠️ Upozornění: Tento checklist slouží jen pro orientaci, ne jako právní rada. Pro konkrétní situace se vždy obraťte na místního korejského právníka.
Jak Thunderbit pomáhá scrapovat korejské weby zodpovědně
Plná transparentnost: pracuji v marketingovém týmu Thunderbit. Ale opravdu si myslím, že spojení produktu a práva je tady smysluplné — není to jen prodejní řeč.
Thunderbit je navržen pro scénáře ze zelené zóny, které tenhle článek popisuje: scraping veřejně dostupných dat bez nutnosti přihlášení. Takhle konkrétní funkce zapadají do rámce souladu:
- Cloudový režim scrapingu pro veřejné weby — není nutné se přihlašovat, není potřeba lokální relace a zůstáváte v hranicích veřejně dostupných dat. To odpovídá principu Yanolja „brána dole“.
- AI Suggest Fields vám umožní přesně určit, které datové sloupce chcete extrahovat. Potřebujete ceny a dostupnost produktů, ale ne telefonní čísla prodejců? Jednoduše osobní sloupce vynechte. To je nejjednodušší způsob, jak se vyhnout spouštěčům PIPA.
- Scheduled Scraper pro opakované kontroly cen, zásob nebo nabídek v rozumných intervalech — není nutné na server neustále posílat požadavky.
- Bezplatný export dat do Excelu, Google Sheets, Airtable a Notion pro interní analytické workflow.
- Subpage scraping pro obohacení veřejných dat z nabídek (např. kliknutí do jednotlivých produktových stránek pro specifikace) bez přístupu do částí chráněných přihlášením nebo omezením.
- AI adaptace rozvržení — scraper pokaždé znovu načte strukturu webu a přizpůsobí se změnám rozložení bez křehkých napevno zadaných selektorů.
Thunderbit podporuje vícejazyčné použití v desítkách jazyků, což je důležité pro týmy pracující s korejsky psanými weby. Můžete si ho zdarma vyzkoušet přes rozšíření Thunderbit pro Chrome.
Žádný nástroj neeliminuje právní riziko. Ale zodpovědná konfigurace — veřejné stránky, faktická data, vyloučená osobní pole, rozumné intervaly — vás udrží v rámci souladu, který tenhle článek popisuje.
Hlavní poznatky o legálnosti web scrapingu v Koreji
Pět věcí, které stojí za zapamatování:
- Technologie web scrapingu sama o sobě je v Koreji legální. Nejvyšší soud to potvrdil v rozhodnutí Yanolja.
- Riziko závisí na způsobu přístupu (brána nahoře vs. brána dole), typu dat (osobní vs. faktická) a využití (interní vs. konkurenční redistribuce).
- Zproštění v trestním řízení ≠ civilní bezpečí. Případ Yanolja ukazuje, že se můžete vyhnout stíhání, a přesto čelit škodě v řádu miliard wonů.
- Pokud scrapujete veřejná, neosobní, faktická data pro interní použití bez přístupových bariér, obvykle jste v bezpečné zóně. Ale „obvykle“ má váhu — záleží na rozsahu, objemu i účelu.
- U rozsáhlých nebo komerčních projektů se vždy poraďte s místním korejským právníkem. Tento článek slouží pro orientaci, ne jako právní rada.
Pokud chcete začít scrapeovat korejské weby zodpovědně, bezplatný tarif Thunderbit vám umožní otestovat workflow v malém měřítku. Více o tom, jak AI scraping funguje v praxi, najdete v našich průvodcích AI web scraping a web scraping bez programování. A pokud chcete vidět nástroj v akci, náš YouTube kanál má návody pro běžné use-cases.
Často kladené otázky
1. Je scraping veřejně dostupných dat v Koreji legální?
Obecně ano pro trestní účely — podle rozhodnutí Nejvyššího soudu ve věci Yanolja nepředstavuje přístup k datům z webu bez objektivních omezení přístupu porušení ICNA. Civilní odpovědnost podle UCPA nebo autorského zákona ale stále může vzniknout, a to podle objemu, investice zdroje a vašeho komerčního využití dat.
2. Můžu být v Koreji žalován za web scraping, i když není trestný?
Ano. Trestní a civilní řízení jsou nezávislá. GC Company byla zproštěna všech trestních obvinění, ale musela podle zastřešujícího ustanovení UCPA zaplatit přibližně 1 miliardu KRW jako civilní škodu. Zproštění viny vás před civilním nárokem nechrání.
3. Dělá porušení podmínek webu scraping v Koreji nelegálním?
Korejské soudy dlouhodobě zastávají názor, že samotné porušení podmínek používání nepředstavuje podle ICNA trestný čin — soud odlišuje omezení užití (ToS) od omezení přístupu (technické bariéry). To ale neznamená, že porušení ToS nemůže podpořit civilní nárok z porušení smlouvy nebo sloužit jako důkaz zlé víry v analýze nekalé soutěže.
4. Jak si korejské právo o web scrapingu stojí ve srovnání s USA?
Obě jurisdikce chrání scraping veřejných dat (Yanolja v Koreji, hiQ v. LinkedIn v USA) a obě uznávají, že samotné porušení ToS není trestným činem (Van Buren v USA). Hlavní rozdíl: Korea má silnější zákonnou ochranu databází a širší zastřešující pravidlo proti nekalé soutěži než USA, které nemají obecné federální právo k databázi. Korejští provozovatelé platforem mají více civilních nástrojů proti scraperům.
5. Co se stane, když z korejských webů scrapuji osobní údaje?
PIPA se uplatní bez ohledu na to, zda jsou informace veřejně viditelné. Sběr osobních údajů — jména, telefonní čísla, e-maily — bez souhlasu nebo jiného právního základu je porušením. Novela PIPA z roku 2023 tuto ochranu posílila a pokyny PIPC z roku 2024 k veřejně dostupným osobním údajům výslovně řeší web crawling a scraping. Sankce mohou dosáhnout až 5 let odnětí svobody, pokuty 50 milionů KRW a správních sankcí do výše 3 % celkových tržeb.
Vyzkoušejte Thunderbit pro zodpovědný web scraping Get Started Free
Zjistěte více




