

Můj dashboard v OpenRouteru ukázal do úterý před obědem utracených 47 dolarů. Stihl jsem asi tucet programovacích úkolů — nic divokého, jen refactoring a pár oprav chyb. V tu chvíli mi došlo, že výchozí nastavení OpenClaw tiše posílá úplně každou interakci, včetně background heartbeat pingů, přes Claude Opus za víc než 15 dolarů za milion tokenů.
Jestli vás někdy překvapil podobný účet — a podle fór nejste sami („už jsem utratil 40 dolarů a ani to pořádně nepoužívám,“ napsal jeden uživatel) — tenhle průvodce vás provede celým postupem auditu a optimalizace, díky kterému jsem dostal měsíční náklady zhruba o 90 % dolů. Nejde jen o „přepnutí na levnější model“, ale o systematické rozebrání toho, kam tokeny opravdu mizí, jak je sledovat, které budget modely obstojí i při reálné agentní práci, a o tři hotové konfigurace, které můžete použít hned dnes. Celé to zabralo jedno odpoledne.
Co je využití tokenů v OpenClaw (a proč je ve výchozím stavu tak vysoké)?
Tokeny jsou účetní jednotkou pro každou AI interakci v OpenClaw. Představ si je jako malé úseky textu — zhruba 4 anglické znaky na jeden token. Každá zpráva, kterou odešleš, každá odpověď, kterou dostaneš, i každý background proces, který se spustí, se účtuje v tokenech.
Problém je v tom, že výchozí nastavení OpenClaw je laděné na maximální výkon, ne na minimální cenu. V základu je primární model nastavený na anthropic/claude-opus-4-5 — tedy na nejdražší dostupnou volbu. Heartbeat pings? I ty běží na Opusu. Sub-agenti, kteří se spouštějí pro vedlejší úkoly? Také Opus. Používat Opus na heartbeat ping je jako najmout neurochirurga, aby ti nalepil náplast. Technicky to funguje, ale je to katastrofálně předražené.
Většina uživatelů si vůbec neuvědomuje, že platí prémiové sazby za triviální background úlohy. Výchozí konfigurace v podstatě předpokládá, že chcete nejlepší model na všechno, pořád — a odpovídajícím způsobem si to účtuje.
Proč snížení využití tokenů v OpenClaw šetří víc než jen peníze
Nejzřejmější přínos je úspora nákladů. Ale časem se přidávají i další výhody.
Levnější modely bývají často rychlejší. Gemini 2.5 Flash-Lite zvládá zhruba 214 tokenů za sekundu oproti Opusu s asi 51 — tedy zhruba 4× rychleji při každé interakci. GPT-OSS-120B na Cerebras dosahuje 1 917 tokenů za sekundu, což je přibližně 35× víc než Opus. V agentním cyklu s více než 50 koly volání nástrojů tenhle rozdíl znamená dokončení za minuty místo čekání na bolestivých 13,6 sekundy do prvního tokenu u Opusu při každém zpětném okruhu.
Získáte také větší rezervu před limity, méně zadržených session a prostor škálovat využití bez toho, abyste škálovali i úzkost z účtu.
Odhadované úspory podle různých profilů použití:
| Typ uživatele | Odhadovaná měsíční útrata (výchozí stav) | Po plné optimalizaci | Měsíční úspora |
|---|---|---|---|
| Lehký (~10 dotazů/den) | ~$100 | ~$12 | ~88% |
| Střední (~50 dotazů/den) | ~$500 | ~$90 | ~82% |
| Těžký (~200+ dotazů/den) | ~$1,750 | ~$220 | ~87% |
Tohle nejsou hypotézy. Jeden vývojář zdokumentoval, že se dostal z $600–750/měsíc na $3–4/den — skutečné snížení o 90 % — díky kombinaci modelového routování a oprav skrytých průsaků, které rozebírám níže.
Anatomie využití tokenů v OpenClaw: kam se každý token opravdu poděje
Tuhle část většina průvodců přeskočí, a přitom je nejdůležitější. Nemůžeš opravit to, co nevidíš.
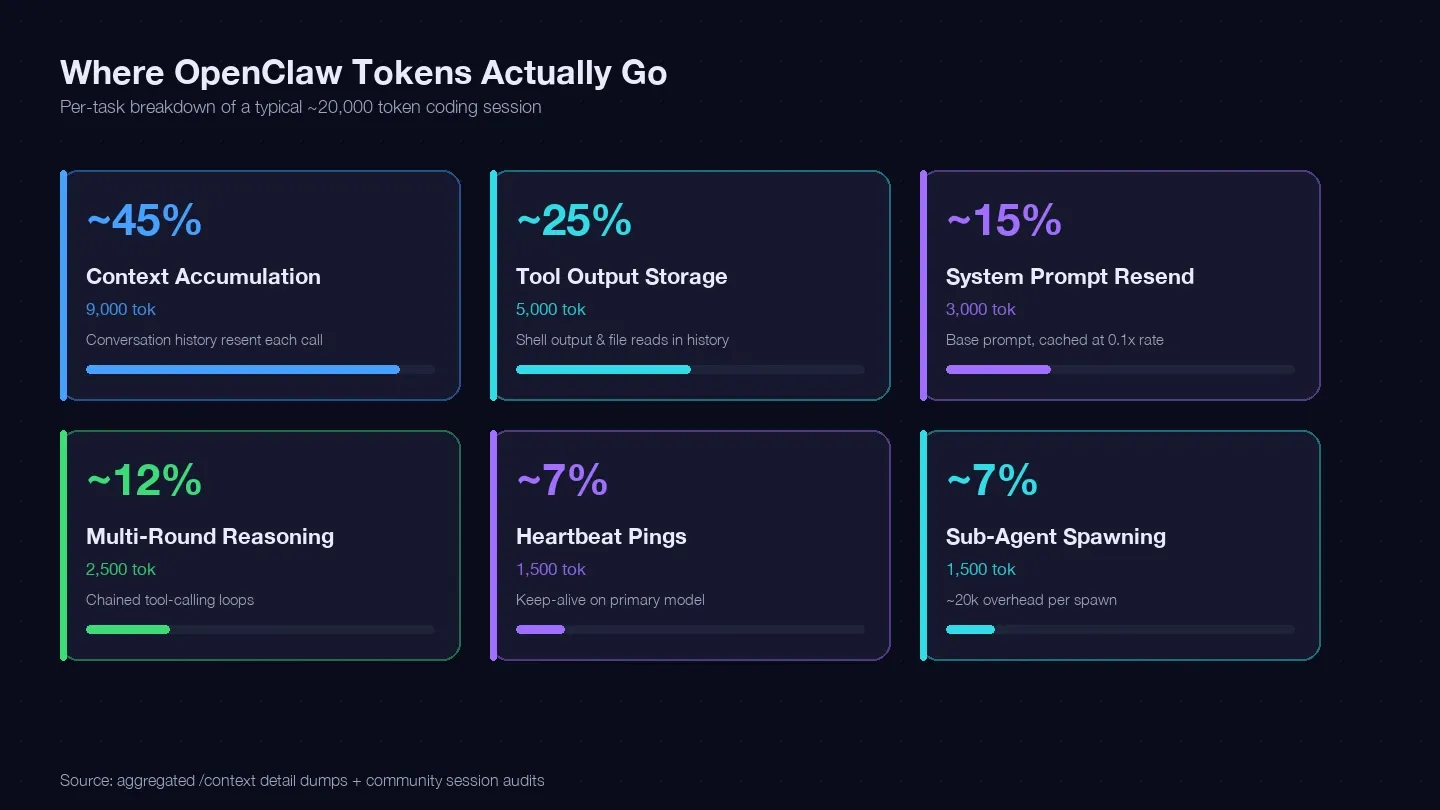
Prošel jsem několik session a porovnal je s LaoZhang cost optimization guide a komunitními /context dumpy, abych vytvořil tokenový rozpis pro typický jeden programovací úkol. Přibližně 20 000 tokenů šlo sem:
Jestli vás někdy překvapil podobný účet — a podle fór nejste sami („už jsem utratil 40 dolarů a ani to pořádně nepoužívám,“ napsal jeden uživatel) — tenhle průvodce vás provede celým postupem auditu a optimalizace, díky kterému jsem dostal měsíční náklady zhruba o 90 % dolů. Nejde jen o „přepnutí na levnější model“, ale o systematické rozebrání toho, kam tokeny opravdu mizí, jak je sledovat, které budget modely obstojí i při reálné agentní práci, a o tři hotové konfigurace, které můžete použít hned dnes. Celé to zabralo jedno odpoledne.
Co je využití tokenů v OpenClaw (a proč je ve výchozím stavu tak vysoké)?
Tokeny jsou účetní jednotkou pro každou AI interakci v OpenClaw. Představte si je jako malé úseky textu — zhruba 4 anglické znaky na jeden token. Každá zpráva, kterou odešlete, každá odpověď, kterou dostanete, i každý background proces, který se spustí, se účtuje v tokenech.
Problém je v tom, že výchozí nastavení OpenClaw je laděné na maximální výkon, ne na minimální cenu. V základu je primární model nastavený na anthropic/claude-opus-4-5 — tedy na nejdražší dostupnou volbu. Heartbeat pings? I ty běží na Opusu. Sub-agenti, kteří se spouštějí pro vedlejší úkoly? Také Opus. Používat Opus na heartbeat ping je jako najmout neurochirurga, aby vám nalepil náplast. Technicky to funguje, ale je to katastrofálně předražené.
Většina uživatelů si vůbec neuvědomuje, že platí prémiové sazby za triviální background úlohy. Výchozí konfigurace v podstatě předpokládá, že chcete nejlepší model na všechno, pořád — a odpovídajícím způsobem si to účtuje.
Proč snížení využití tokenů v OpenClaw šetří víc než jen peníze
Nejzřejmější přínos je úspora nákladů. Ale časem se přidávají i další výhody.
Levnější modely bývají často rychlejší. Gemini 2.5 Flash-Lite zvládá zhruba 214 tokenů za sekundu oproti Opusu s asi 51 — tedy zhruba 4× rychleji při každé interakci. GPT-OSS-120B na Cerebras dosahuje 1 917 tokenů za sekundu, což je přibližně 35× víc než Opus. V agentním cyklu s více než 50 koly volání nástrojů tenhle rozdíl znamená dokončení za minuty místo čekání na bolestivých 13,6 sekundy do prvního tokenu u Opusu při každém zpětném okruhu.
Získáte také větší rezervu před limity, méně zadržených session a prostor škálovat využití bez toho, abyste škálovali i úzkost z účtu.
Odhadované úspory podle různých profilů použití:
| Typ uživatele | Odhadovaná měsíční útrata (výchozí stav) | Po plné optimalizaci | Měsíční úspora |
|---|---|---|---|
| Lehký (~10 dotazů/den) | ~$100 | ~$12 | ~88% |
| Střední (~50 dotazů/den) | ~$500 | ~$90 | ~82% |
| Těžký (~200+ dotazů/den) | ~$1,750 | ~$220 | ~87% |
Tohle nejsou hypotézy. Jeden vývojář zdokumentoval, že se dostal z $600–750/měsíc na $3–4/den — skutečné snížení o 90 % — díky kombinaci modelového routování a oprav skrytých průsaků, které rozebírám níže.
Anatomie využití tokenů v OpenClaw: kam se každý token opravdu poděje
Tuhle část většina průvodců přeskočí, a přitom je nejdůležitější. Nemůžete opravit to, co nevidíte.
Prošel jsem několik session a porovnal je s LaoZhang cost optimization guide a komunitními /context dumpy, abych vytvořil tokenový rozpis pro typický jeden programovací úkol. Přibližně 20 000 tokenů šlo sem:
| Kategorie tokenů | Typické % z celku | Příklad (1 programovací úkol) | Dá se to ovlivnit? |
|---|---|---|---|
| Akumulace kontextu (historie konverzace se posílá znovu při každém volání) | ~40–50% | ~9 000 tokenů | Ano — /clear, /compact, kratší session |
| Ukládání výstupů nástrojů (shell output, čtení souborů v historii) | ~20–30% | ~5 000 tokenů | Ano — menší čtení, užší rozsah nástrojů |
| Znovuposílání systémového promptu (~15K základ) | ~10–15% | ~3 000 tokenů | Částečně — cache reads za 0,1× sazby |
| Vícekrokové uvažování (řetězené cykly volání nástrojů) | ~10–15% | ~2 500 tokenů | Volbou modelu + lepšími prompty |
| Heartbeat / keep-alive pings | ~5–10% | ~1 500 tokenů | Ano — změna konfigurace |
| Volání sub-agentů | ~5–10% | ~1 500 tokenů | Ano — routování modelů |
Největší položka — akumulace kontextu — je vaše historie konverzace, která se při každém API volání posílá znovu. Jeden reálný dump session ukázal 185 400 tokenů jen v bucketu Messages, a to ještě předtím, než model vůbec odpověděl. K tomu systémový prompt a nástroje přidaly dalších zhruba 35 800 tokenů pevného overheadu.
Závěr: pokud mezi nesouvisejícími úkoly nečistíte session, platíte za přenos celé historie konverzace při každém jediném kroku.
Jak sledovat využití tokenů v OpenClaw (co neměříte, to neosekáte)
Než změníte cokoliv jiného, získejte přehled o tom, kam tokeny odcházejí. Skočit rovnou na „použijte levnější model“ bez monitoringu je jako snažit se zhubnout bez vážení.
Zkontrolujte dashboard v OpenRouteru
Pokud routujete přes OpenRouter, stránka Activity je nejjednodušší dashboard bez nastavování. Můžete filtrovat podle modelu, provideru, API klíče i časového období. Zobrazení Usage Accounting rozpadá prompt, completion, reasoning a cached tokeny u každého requestu. K dispozici je i tlačítko Export (CSV nebo PDF) pro delší analýzu.
Na co se dívat: který model spálil nejvíc tokenů a jestli se heartbeat nebo sub-agent requesty neobjevují jako nečekaně velké položky.
Projděte lokální API logy
OpenClaw ukládá session data do ~/.openclaw/agents.main/sessions/sessions.json, kde je u každé session totalTokens. Můžete také spustit openclaw logs --follow --json pro průběžné logování každého requestu v reálném čase.
Jeden důležitý detail: sessions.json totalTokens se po compaction neaktualizuje, takže dashboard může ukazovat staré hodnoty před kompakcí. Spoléhejte spíš na /status a /context detail než na uložené součty.
Použijte tracking třetích stran (pro střední až těžké uživatele)
LiteLLM proxy vám dá endpoint kompatibilní s OpenAI před 100+ providery a automaticky loguje útratu podle virtuálního klíče, modelu, uživatele a týmu. Největší výhoda: tvrdé rozpočty na klíč, které přežijí /clear — rozjetý sub-agent nepřekročí limit, který jste nastavili.
Helicone je ještě jednodušší — jedna změna base URL, která vám přidá Sessions view pro seskupení souvisejících requestů. Jeden prompt „opravte tuhle chybu“, který se rozpadne do 8+ volání sub-agentů, se zobrazí jako jeden řádek session s reálnými celkovými náklady. Free tier: 10 000 requestů/měsíc.
Rychlé kontroly přímo v OpenClaw
Pro každodenní monitoring stačí čtyři příkazy přímo v session:
/status— ukazuje využití kontextu, poslední input/output tokeny, odhad nákladů/usage full— footer s využitím u každé odpovědi/context detail— rozpis tokenů podle souboru, skillu a nástroje/compact [guidance]— vynutí kompakci s volitelným zaměřením
Spusťte /context detail před změnami konfigurace i po nich. Tak zjistíte, jestli optimalizace opravdu fungovala.
Souboj o nejlevnější model OpenClaw: které budget LLM zvládnou agentní práci doopravdy
Většina průvodců tady chybuje. Ukážou tabulku cen, označí nejlevnější řádek a hotovo. Benchmarky ale neříkají moc o reálném agentním výkonu — to komunita opakovaně zdůrazňuje velmi hlasitě. Jak to vyjádřil jeden uživatel: „benchmarky vůbec nepomáhají pochopit, který model funguje nejlépe pro agentní AI.“
Klíčový poznatek: nejlevnější model není vždy nejlevnější výsledná volba. Model, který selže a opakuje pokus čtyřikrát, vás ve skutečnosti stojí víc než střední třída, která uspěje napoprvé. V produkčních agentních systémech počítejte s 5–10% mírou retry — a pokud se pět LLM volání řetězí a krok čtyři selže, naivní retry spustí znovu všech pět kroků.
Tady je moje matice schopností s „Real Agentic Score“ založeným na skutečných hlášeních uživatelů, ne na syntetických benchmarkech:
| Model | Input $/1M | Output $/1M | Spolehlivost tool-calling | Vícekrokové uvažování | Real Agentic Score (1–5) | Nejlepší pro |
|---|---|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | Smíšená — občasné smyčky | Základní | ⭐2.5 | Heartbeat, jednoduché dotazy |
| GPT-OSS-120B | $0.04 | $0.19 | Dostatečná | Dostatečné | ⭐3.0 | Budget experimenty, úlohy citlivé na rychlost |
| DeepSeek V3.2 | $0.26 | $0.38 | Nekonzistentní (6 otevřených issue) | Dobré | ⭐3.0 | Úlohy náročné na reasoning, minimum tool-calling |
| Kimi K2.5 | $0.38 | $1.72 | Dobrá (přes :exacto) | Dostatečné | ⭐3.5 | Jednodušší až středně náročné kódování |
| MiniMax M2.5 / M2.7 | $0.28 | $1.10 | Dobrá | Dobrá | ⭐4.0 | Každodenní univerzální model na programování |
| Claude Haiku 4.5 | $1.00 | $5.00 | Výborná | Dobrá | ⭐4.5 | Spolehlivý mid-tier fallback |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Výborná | Výborná | ⭐5.0 | Složité vícekrokové úkoly |
| Claude Opus 4.5/4.6 | $5.00 | $15.00 | Výborná | Výborná | ⭐5.0 | Rezervovat jen pro nejtěžší problémy |
Varování před DeepSeek a Gemini Flash při tool callingu
DeepSeek V3.2 vypadá na papíře skvěle — 72–74 % na SWE-Bench, 11–36× levnější než Sonnet. V praxi ale šest samostatných GitHub issue v Cline, Roo Code, Continue a NVIDIA NIM popisuje rozbité chování při volání nástrojů. Verdikt Composio v přímém srovnání: „DeepSeek V3.2 zvládl části aplikace, ale selhával při exekuci, rychlosti a spolehlivosti.“ Jednovětý soud Zvi Mowshowitze: „v pohodě a levný, ale.“
Gemini 2.5 Flash má podobnou mezeru. Vlákno na Google AI Developers Forum s názvem „Very frustrating experience with Gemini 2.5 function calling performance“ začíná větou: „chování function calling u modelů Gemini se stalo naprosto nespolehlivým a nepředvídatelným."
OpenRouter upozornil na důležitý detail: „sklon modelu volat nástroje a přesnost těchto volání se může dramaticky lišit napříč hosty se stejnými váhami.“ Pokud levné modely routujete přes OpenRouter, hledejte štítek :exacto — tichá změna providera může z levného a spolehlivého modelu přes noc udělat drahou retry smyčku.
Kdy použít který model
- Gemini Flash-Lite: Heartbeat, keep-alive pings, jednoduché Q&A. Nikdy ne pro vícekrokové volání nástrojů.
- MiniMax M2.5/M2.7: Váš každodenní model pro obecné programovací úlohy. SWE-Pro 56.22, Terminal-Bench 2 57.0 % za zlomek ceny Sonnetu.
- Claude Haiku 4.5: Spolehlivý fallback, když levné modely selhávají při volání nástrojů. Výborná spolehlivost tool-callingu za asi 3× nižší cenu než Sonnet.
- Claude Sonnet 4.6: Složité vícekrokové agentní úlohy. Tady dostáváte za peníze skutečnou hodnotu.
- Claude Opus: Nechte si ho jen pro opravdu nejtěžší problémy. Nenechte z něj dělat výchozí volbu pro cokoliv.
(Ceny modelů se často mění — před nasazením konfigurace si ověřte aktuální sazby na OpenRouter nebo na stránkách příslušného providera.)
Skryté průsaky tokenů, které většina průvodců vynechává
Uživatelé na fórech hlásí, že vypnutí konkrétních funkcí dramaticky sníží náklady, ale žádný průvodce, který jsem našel, nedává dohromady jednotný checklist všech skrytých průsaků i s jejich skutečným dopadem na tokeny. Tady je kompletní rozklad:
| Skrytý průsak | Cena v tokenech na výskyt | Jak to opravit | Klíč v konfiguraci |
|---|---|---|---|
| Výchozí heartbeat na Opusu | ~100 000 tokenů/spuštění bez izolace | Override na Haiku + isolatedSession | heartbeat.model, heartbeat.isolatedSession: true |
| Spouštění sub-agentů | ~20 000 tokenů na spawn ještě před samotnou prací | Směrovat sub-agenty na Haiku | subagents.model |
| Načítání plného kontextu codebase | ~3 000–15 000 tokenů na auto-explore | .clawignore pro node_modules, dist, lockfiles | .clawrules + .clawignore |
| Automatické shrnování paměti | ~500–2 000 tokenů/session | Vypnout nebo snížit frekvenci | memory: false nebo memory.max_context_tokens |
| Hromadění historie konverzace | ~500+ tokenů/turn (kumulativně) | Začínat nové session mezi nesouvisejícími úkoly | Disciplína s /clear |
| Přetížení nástroji MCP serverů | ~7 000 tokenů pro 4 servery; 50 000+ pro 5+ | Držet MCP na minimu | Odstranit nepoužívané MCP |
| Inicializace skillů/pluginů | 200–1 000 tokenů za načtený skill | Vypnout nepoužívané skills | skills.entries.<name>.enabled: false |
| Agent Teams (plan mode) | ~7× cena standardní session | Používat jen pro opravdu paralelní práci | Upřednostnit sekvenční postup |
Heartbeat dren si zaslouží vlastní upozornění. Ve výchozím stavu heartbeat každých 30 minut běží na primárním modelu (Opus). Nastavení isolatedSession: true to srazí zhruba z ~100 000 tokenů na spuštění na 2 000–5 000 tokenů — tedy o 95–98 % u jediné položky.
Tři rychlé výhry, které ušetří nejvíc tokenů za méně než dvě minuty
Všechny tři jsou bezrizikové a zvládnete je do dvou minut:
-
/clearmezi nesouvisejícími úkoly (5 sekund). Tohle je největší úspora tokenů. Shoda na fórech mluví o 50–70% snížení už jen tím, že před novou prací smažete historii session. Pamatujete na bucket Messages s 185k tokeny z /context dumpu?/clearho vymaže. -
/model haiku-4.5pro rutinní práci (10 sekund). Taktické přepínání modelů přináší 60–80% snížení nákladů u běžných úkolů. Haiku bez problémů zvládne většinu jednoduchého kódování, hledání v souborech i commit message. -
Zkraťte
.clawrulesna méně než 200 řádků + přidejte.clawignore(90 sekund). Soubor s pravidly se načítá při každé jediné zprávě. Při 200 řádcích je to asi 1 500–2 000 tokenů na turn; při 1 000 řádcích už permanentně zatěžujete každý request o 8 000–10 000 tokenů. V kombinaci s.clawignore, který vyloučínode_modules/,dist/, lockfiles a generovaný kód, jeden vývojář tvrdí, že z toho dostal 92% snížení tokenů už jen díky této disciplíně.
Krok za krokem: tři připravené konfigurace, které dramaticky sníží využití tokenů v OpenClaw

Následují tři kompletní, okomentované konfigurace openclaw.json — od varianty „jen začněte šetřit“ po „plný optimalizační stack“. Každá obsahuje inline komentáře i odhad měsíčních nákladů.
Než začnete:
- Obtížnost: Začátečník (Config A) → Středně pokročilý (Config B) → Pokročilý (Config C)
- Časová náročnost: ~5 minut pro Config A, ~15 minut pro Config C
- Co budete potřebovat: nainstalovaný OpenClaw, textový editor, přístup k
~/.openclaw/openclaw.json
Config A: Začátečník — prostě ušetřit peníze
Pět řádků. Žádná složitost. Mění výchozí model z Opusu na Sonnet, vypíná memory overhead a izoluje heartbeat na Haiku.
// ~/.openclaw/openclaw.json
{
"agents": {
"defaults": {
"model": { "primary": "anthropic/claude-sonnet-4-6" }, // dříve Opus — okamžitá úspora 3–5×
"heartbeat": {
"every": "55m", // sladěno s 1h TTL cache pro maximum cache hitů
"model": "anthropic/claude-haiku-4-5", // Haiku na pingy, ne Opus
"isolatedSession": true // ~100k → 2–5k tokenů na spuštění
}
}
},
"memory": { "enabled": false } // ušetří ~500–2k tokenů/session
}
Co byste měli vidět po použití: Spusťte /status předtím a potom. Cena na jeden request by měla viditelně spadnout a heartbeat položky v OpenRouter Activity by měly ukazovat Haiku místo Opusu.
| Úroveň použití | Výchozí stav (Opus) | Config A (Sonnet + Haiku heartbeats) | Úspora |
|---|---|---|---|
| Lehká (~10 dotazů/den) | ~$100 | ~$35 | 65% |
| Střední (~50 dotazů/den) | ~$500 | ~$250 | 50% |
| Těžká (~200 dotazů/den) | ~$1,750 | ~$900 | 49% |
Config B: Středně pokročilý — chytré tříúrovňové routování
Primární Sonnet pro skutečnou práci. Haiku pro sub-agenty a kompakci. Gemini Flash-Lite jako budget fallback, když je Claude přetížený. Fallback řetězce řeší výpadky providera automaticky.
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"anthropic/claude-haiku-4-5", // pokud je Sonnet throttled
"google/gemini-2.5-flash-lite" // ultra-levná poslední záchrana
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m", // 55 min < 1h cache TTL = cache hit
"model": "google/gemini-2.5-flash-lite", // pár haléřů za ping
"isolatedSession": true,
"lightContext": true // minimum kontextu u heartbeat callů
},
"subagents": {
"maxConcurrent": 4, // dolů z výchozích 8
"model": "anthropic/claude-haiku-4-5" // sub-agenti nepotřebují Sonnet
},
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5", // shrnutí kompakce přes Haiku
"memoryFlush": { "enabled": true }
}
}
}
}
Očekávaný výsledek: Položky pro sub-agenty v logu by teď měly ukazovat ceny Haiku. Heartbeat by měl být téměř zdarma. Váš fallback chain zajistí, že výpadek Claude nezastaví session — plynule se přepne na Gemini.
| Úroveň použití | Výchozí stav | Config B | Úspora |
|---|---|---|---|
| Lehká | ~$100 | ~$20 | 80% |
| Střední | ~$500 | ~$150 | 70% |
| Těžká | ~$1,750 | ~$500 | 71% |
Config C: Power user — plný optimalizační stack
Model po sub-agentovi, kompakce kontextu připnutá na Haiku, vision routování na Gemini Flash, úzký .clawrules + .clawignore, vypnuté nepoužívané skills. Tohle je konfigurace, která vás dostane do pásma 85–90% úspory.
{
"agents": {
"defaults": {
"workspace": "~/clawd",
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"openrouter/anthropic/claude-sonnet-4-6", // jiný provider jako záloha
"minimax/minimax-m2-7", // levný denní fallback
"anthropic/claude-haiku-4-5" // poslední záchrana
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
},
"minimax/minimax-m2-7": {
"params": { "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m",
"model": "google/gemini-2.5-flash-lite",
"isolatedSession": true,
"lightContext": true,
"activeHours": "09:00-19:00" // v noci bez heartbeatů
},
"subagents": {
"maxConcurrent": 4,
"model": "anthropic/claude-haiku-4-5"
},
"contextPruning": { "mode": "cache-ttl", "ttl": "1h" },
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5",
"identifierPolicy": "strict",
"memoryFlush": { "enabled": true }
},
"bootstrapMaxChars": 12000, // dolů z výchozích 20000
"imageModel": "google/gemini-3-flash" // vision úlohy přes levný model
}
},
"memory": { "enabled": true, "max_context_tokens": 800 }, // minimální paměť
"skills": {
"entries": {
"web-search": { "enabled": false },
"image-generation": { "enabled": false },
"audio-transcribe": { "enabled": false }
}
}
}
Příklad override pro konkrétní sub-agent — vložte do ~/.openclaw/agents/lint-runner/SOUL.md:
---
name: lint-runner
description: Spouští lint/format kontroly a aplikuje triviální opravy
tools: [Bash, Read, Edit]
model: anthropic/claude-haiku-4-5
---
Minimum viable .clawignore — už to samo o sobě stáhne typické bootstrapy ze 150k znaků někam k 30–50k:
node_modules/
dist/
build/
.next/
coverage/
.venv/
vendor/
*.lock
package-lock.json
yarn.lock
pnpm-lock.yaml
*.min.js
*.min.css
**/__snapshots__/
**/*.snap
| Úroveň použití | Výchozí stav | Config C | Úspora |
|---|---|---|---|
| Lehká | ~$100 | ~$12 | 88% |
| Střední | ~$500 | ~$90 | 82% |
| Těžká | ~$1,750 | ~$220 | 87% |
Tato čísla odpovídají dvěma nezávislým reportům reálných uživatelů: zdokumentovanému poklesu Praney Behlových nákladů z $600–750/měsíc na $3–4/den (snížení o 90 %) a případovým studiím LaoZhang, kde šlo z $943 → $347 (63 %), $1 750 → $1 000 (64 %), $200 → $70 (65 %) při částečné optimalizaci.
Jak používat příkaz /model ke kontrole využití tokenů v OpenClaw za běhu
Příkaz /model přepne aktivní model pro další turn, ale zachová kontext vaší konverzace — žádný reset, žádná ztracená historie. To je každodenní návyk, který postupně přináší velké úspory.
Praktický workflow:
- Pracujete na ošklivém refactoru ve více souborech? Zůstaňte na Sonnetu.
- Rychlý dotaz „co dělá tenhle regex?“?
/model haiku, zeptejte se, pak/model sonnetpro návrat. - Commit message nebo úprava dokumentace?
/model flash-lite, hotovo.
Můžete si nastavit aliasy v openclaw.json pod commands.aliases, které mapují krátká jména (haiku, sonnet, opus, flash) na plné provider řetězce. Ušetří to pár stisků kláves při každém přepnutí.
Počty: 50 dotazů denně na Sonnetu je zhruba 3 dolary denně. Stejných 50 dotazů rozdělených v poměru 70/20/10 mezi Haiku/Sonnet/Opus je asi 1,10 dolaru denně. Za měsíc je to $90 → $33 — o 63 % levnější bez změny nástrojů, jen díky návykům.
Bonus: Jak sledovat ceny modelů OpenClaw napříč providery pomocí Thunderbit
Sledujte ceny modelů napříč providery pomocí AI Get Started Free
S tolika modely a providery — OpenRouter, přímé Anthropic API, Google AI Studio, DeepSeek, MiniMax — se ceny často mění. Anthropic přes noc snížil cenu výstupu u Opusu zhruba o 67 %. Google v prosinci 2025 stáhl limity free tieru o 50–80 %. Udržovat statickou cenovou tabulku ručně aktuální je prohraný boj.
Thunderbit to řeší bez jakéhokoli scraping kódu. Je to AI web scraper jako Chrome extension, navržený přesně pro tenhle typ strukturované extrakce dat.
Postup, který používám:
- Otevřu stránku modelů v OpenRouteru v Chromu a kliknu na Thunderbit „AI Suggest Fields“. Projde stránku a navrhne sloupce — název modelu, input price, output price, context window, provider.
- Kliknu na Scrape a hned to vyexportuju do Google Sheets.
- Nastavím scheduled scrape obyčejnou angličtinou — „každé pondělí v 9 ráno znovu projdi seznam modelů v OpenRouteru“ — a poběží to automaticky v cloudu.
Od té chvíle se váš vlastní tracker cen aktualizuje sám. Jakýkoli model, který zlevní o 30 %, nebo provider, který dostane štítek Exacto, se objeví v pondělní tabulce bez toho, abyste se o něco starali. Více jsme o AI data extraction pro byznys psali na blogu.
Porovnáváte ceny na přímých stránkách providerů (Anthropic, Google, DeepSeek)? Thunderbit umí subpage scraping, takže otevře každou stránku modelu a vytáhne sazby podle providera — hodí se, když chcete vědět, jestli je routování Kimi K2.5 přes OpenRouter levnější než přímé použití přes NVIDIA Build. Podívejte se na ceny Thunderbit pro informace o free tieru a plánech.
Klíčové závěry pro snížení využití tokenů v OpenClaw
Rámec je jednoduchý: Pochopit → Sledovat → Routovat → Optimalizovat.
Největší dopad mají tyto kroky, seřazené podle důležitosti:
- Nenechávejte jako výchozí Opus. Přepněte primární model na Sonnet nebo MiniMax M2.7. Už to samo o sobě znamená 3–5× nižší náklady.
- Izolujte heartbeat. Nastavte
isolatedSession: truea routujte heartbeat na Gemini Flash-Lite. Z průsaku ~100k tokenů uděláte ~2–5k. - Směrujte sub-agenty na Haiku. Každý spawn načte kolem 20k tokenů kontextu ještě před tím, než začne pracovat. Nenechávejte to běžet na Opusu.
- Používejte
/clearbez výjimky. Je zdarma, trvá 5 sekund a podle komunity šetří víc než jakýkoli jiný jednotlivý krok. - Přidejte
.clawignore. Vyloučenínode_modules, lockfiles a build artefaktů dramaticky zmenší bootstrap kontext. - Monitorujte přes
/context detailpřed změnami i po nich. Co neměříte, nemůžete zlepšit.
Nejlevnější model závisí na úkolu. Gemini Flash-Lite na heartbeat. MiniMax M2.7 na každodenní kódování. Haiku na spolehlivé volání nástrojů. Sonnet na složitou vícekrokovou práci. Opus jen pro opravdu nejtěžší problémy — a nic jiného.
Většina čtenářů může během jediného odpoledne ušetřit 50–70 % s Config A nebo B. Plných 85–90 % vyžaduje naskládat všechno dohromady — modelové routování, opravy skrytých průsaků, .clawignore, disciplínu se session — ale je to dosažitelné a výsledky drží.
Často kladené otázky
1. Kolik stojí OpenClaw měsíčně?
Záleží čistě na vaší konfiguraci, objemu použití a volbě modelu. Lehcí uživatelé (~10 dotazů/den) obvykle utratí po optimalizaci 5–30 dolarů měsíčně, zatímco ve výchozím stavu přes 100 dolarů. Střední uživatelé (~50 dotazů/den) se pohybují zhruba na 90–400 dolarech měsíčně. Těžcí uživatelé mohou na defaultu dosáhnout 600–2 000+ dolarů/měsíc — jeden zdokumentovaný extrém byl 5 623 dolarů za jediný měsíc. Interní telemetrie Anthropic naznačuje medián kolem 13 dolarů na vývojáře a aktivní den.
2. Jaký je nejlevnější model OpenClaw, který je pořád dobrý na kódování?
MiniMax M2.5/M2.7 je nejlepší obecný denní model — dobrá spolehlivost tool-callingu, SWE-Pro 56.22, za zhruba $0.28/$1.10 za milion tokenů. Pro heartbeat a jednoduché dotazy je Gemini 2.5 Flash-Lite za $0.10/$0.40 těžké porazit. Claude Haiku 4.5 za $1/$5 je spolehlivý mid-tier fallback, když potřebujete výborné volání nástrojů bez cen Sonnetu.
3. Můžu v OpenClaw používat modely z free tieru?
Technicky ano. GPT-OSS-120B je zdarma přes tag :free v OpenRouteru i na NVIDIA Build. Gemini Flash-Lite má free tier (15 RPM, 1 000 requestů denně). DeepSeek dává 5 milionů tokenů zdarma při registraci. Free tier ale mívá tvrdé rate limity, nižší rychlost a horší dostupnost. Levné placené modely — pár haléřů za milion tokenů — jsou pro běžné používání mnohem spolehlivější.
4. Ztratím po přepnutí modelu uprostřed konverzace přes /model kontext?
Ne. /model zachová celý kontext session — další turn se pošle novému modelu, ale s kompletní historií. Je to potvrzené v dokumentaci OpenClaw k pojmům a funguje to stejně i v Claude Code. Můžete volně přecházet mezi Haiku pro rychlé otázky a Sonnetem pro složitou práci, aniž byste o cokoliv přišli.
5. Jaký je nejrychlejší způsob, jak dnes snížit účet za OpenClaw?
Zadejte /clear mezi nesouvisejícími úkoly. Je to zdarma, trvá pět sekund a smaže historii konverzace, která se při každém API volání posílá znovu. Jedna reálná session ukázala 185 000 tokenů nashromážděné historie zpráv — a vše se přenášelo a účtovalo znovu při každém kroku. Vymazat to před začátkem nové práce je návyk s nejvyšší návratností.




