Optimalizace dotazů nad seznamy v Apollo není jen nějaká „vývojářská hračka“ – je to zásadní skill pro každého, kdo jede na čerstvých zpravodajských datech, automatizované extrakci zpráv nebo potřebuje rychlé obchodní a provozní workflow. Na vlastní oči jsem viděl, jak jeden pomalý dotaz na seznam dokáže z jinak hezkého dashboardu udělat úzké hrdlo: obchodníci zírají na nekonečné načítání a operativa to pak zachraňuje improvizací v tabulkách. Ve světě, kde už , se počítá fakt každá milisekunda.

Jak tedy zařídit, aby dotazy na seznamy v Apollo Client byly rychlé jak blesk, stabilní a škálovatelné – hlavně když sbíráš zprávy z webu, hlídáš leady nebo krmíš kritické dashboardy? V tomhle průvodci dávám dohromady postupy, které se mi v praxi osvědčily (a pár jsem si bohužel musel „odžít“): od návrhu dotazů přes cache a stránkování až po zapojení no‑code nástrojů jako , které automatizují rutinu kolem extrakce zpráv. Ať jsi vývojář, produktový manažer, nebo ten člověk, na kterého všichni ukážou, když je dashboard pomalý – tady máš praktický playbook pro výkon seznamů v Apollo GraphQL.
Proč optimalizovat dotazy na seznamy v Apollo? (apollo client list performance, optimize apollo list queries)
Řekněme si to na rovinu: nikdo nechce čekat, než se načtou titulky nebo obchodní leady. Ve firmách – obzvlášť tam, kde se jede na nebo na datech v reálném čase – pomalé dotazy na seznamy v Apollo uživatele nejen štvou. Stojí peníze, brzdí rozhodování a tlačí lidi zpátky k ruční práci. navíc říká, že kancelářští pracovníci tráví zhruba třetinu dne úkoly s nízkou přidanou hodnotou, často právě kvůli pomalým nebo roztříštěným nástrojům.
Co se typicky děje, když dotazy na seznamy nejsou vyladěné:
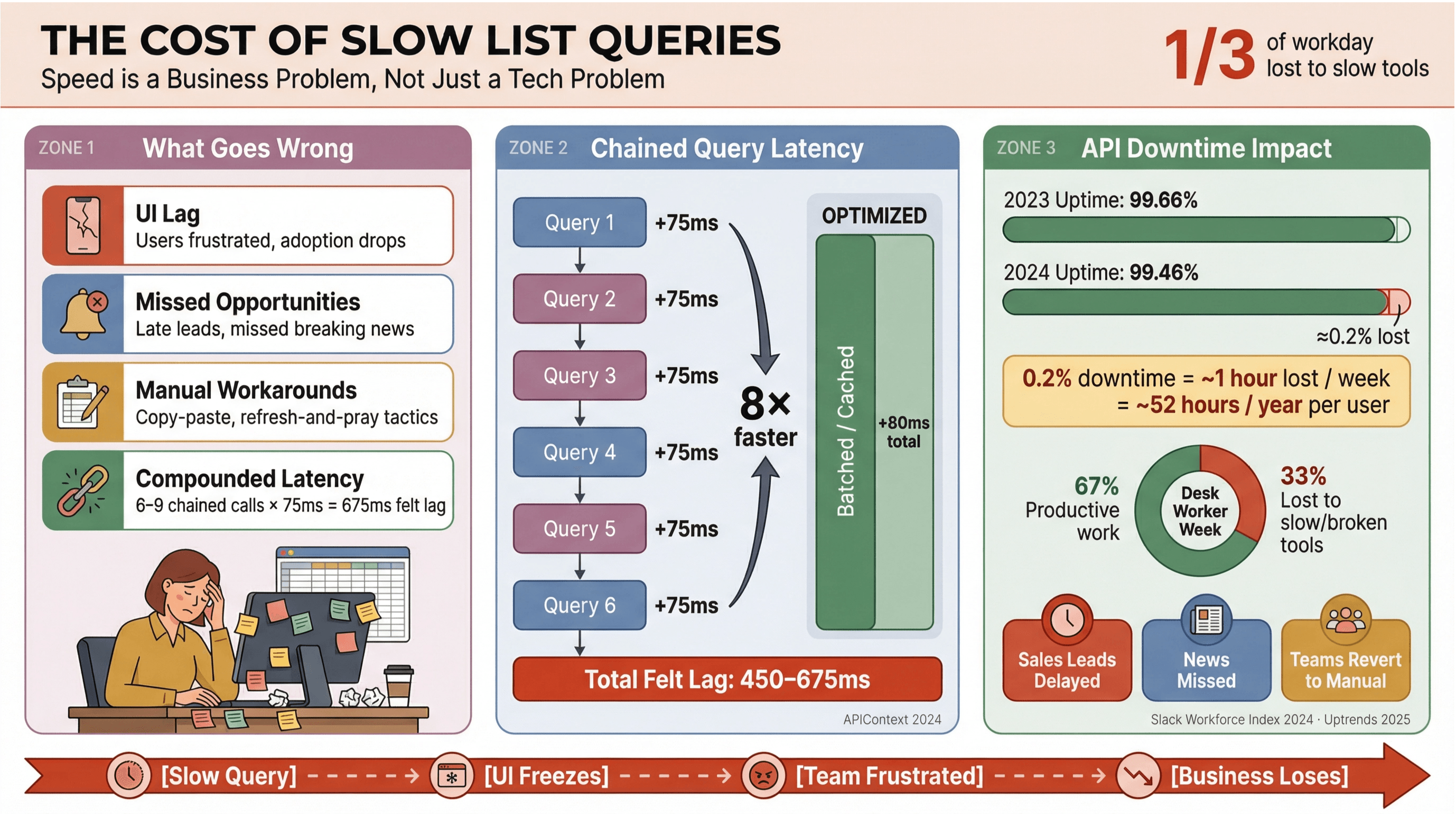
- Zpožděné UI: Lidi čekají, roste frustrace a klesá adopce.
- Zmeškané příležitosti: V prodeji nebo monitoringu zpráv může i pár sekund znamenat ztrátu horkého leadu nebo „breaking news“.
- Ruční obcházení: Týmy se vrací ke kopírování, tabulkám nebo taktice „obnov a doufej“.
- Kumulovaná latence: Každé pomalé API volání se sčítá – když workflow spouští 6–9 navazujících dotazů, i relativně malých 75 ms na volání se může změnit na 450–675 ms vnímaného zpoždění ().
A nejde jen o rychlost. a průměrná dostupnost spadla z 99,66 % na 99,46 % během jediného roku – což u aplikací, které jedou hodně přes seznamy, znamená skoro hodinu ztracené produktivity týdně. Pokud tvoje firma stojí na zpravodajských datech v reálném čase, je to riziko, které si prostě nemůžeš dovolit.
Volba správné datové struktury a polí (apollo graphql list best practices)
Jedna z nejčastějších chyb, které vídám (a jo, taky jsem si tím prošel), je chovat se k dotazu na seznam jako k dotazu na detail. V GraphQL si můžeš vyžádat přesně to, co potřebuješ – tak toho využij. Overfetching je nepřítel výkonu, zvlášť u nástrojů pro scraping zpráv a u dashboardů v reálném čase.
Přizpůsobení polí pro automatizovanou extrakci zpráv
Představ si, že stavíš news feed. Opravdu potřebuješ v dotazu na seznam celé tělo článku, všechny tagy, komentáře a bio autora? Většinou fakt ne. Rozdíl vypadá takhle:
Efektivní dotaz na seznam:
1query NewsFeed($after: String, $first: Int) {
2 newsFeed(after: $after, first: $first) {
3 edges {
4 cursor
5 node {
6 id
7 title
8 url
9 sourceName
10 publishedAt
11 }
12 }
13 pageInfo { endCursor hasNextPage }
14 }
15}Neefektivní dotaz na seznam (takhle ne):
1query NewsFeedTooHeavy($after: String, $first: Int) {
2 newsFeed(after: $after, first: $first) {
3 edges {
4 node {
5 id title url publishedAt
6 fullText
7 summary
8 entities { ... }
9 relatedArticles { ... }
10 }
11 }
12 }
13}Ten první je lehký a rychlý – ideální pro řazení, filtrování a vykreslení řádků. Ten druhý je detailní dotaz v převleku: tahá velké payloady a brzdí všechno okolo (, ).
Tip z praxe: Jeď dvouvrstvě – v seznamu načítej jen „light“ pole a „těžké“ detaily (třeba plný text nebo NLP obohacení) dotahuj až ve chvíli, kdy uživatel položku otevře nebo na ni najede.
Využití cache v Apollo Client pro rychlejší dotazy (apollo client list performance)
Cache v Apollo Client je taková tajná zbraň pro svižné seznamy. Když je dobře nastavená, umí:
- Vrátit opakované dotazy okamžitě (bez síťového round‑tripu)
- Snížit zátěž serveru a náklady na API
- Zajistit plynulou navigaci zpět/vpřed a změny filtrů
Cache ale není magie – chce to trochu nastavení a hlavně disciplínu.
Nastavení vhodných cache politik
Apollo podporuje několik :
| Policy | Co dělá | Nejlepší použití pro seznamy zpráv |
|---|---|---|
| cache-first | Čte z cache, na síť jde jen když data chybí | Návrat na seznam, přepínání filtrů, navigace zpět/vpřed |
| network-only | Vždy načítá ze sítě | Ruční refresh, „nejnovější titulky“ |
| cache-and-network | Nejprve vrátí cache, pak aktualizuje odpovědí ze sítě | Rychlé první vykreslení + update na pozadí (skvělé pro feedy) |
| no-cache | Vždy načítá, nic neukládá | Jednorázové citlivé dotazy (u seznamů spíš výjimečně) |
Pro zpravodajská data v reálném čase mám nejradši cache-and-network – uživatel něco uvidí hned a data se pak potichu aktualizují na pozadí. Jen bacha na „blikání“ UI, když se při refreshi přehází pořadí položek ().
Tipy k nastavení cache:
- Používej stabilní ID (
idnebo_id) pro normalizaci (). - U velkých seznamů dolaď velikost cache a garbage collection ().
- Neukládej obří nenormalizované bloky pod
ROOT_QUERY– umí to aplikaci citelně zpomalit ().
Stránkování a omezení počtu položek (apollo graphql list best practices)
Jestli se snažíš naráz natáhnout stovky nebo tisíce článků či leadů, koleduješ si o průšvih. Stránkování není jen UX „nice to have“ – je to nutnost pro výkon.
Apollo podporuje jak , tak stránkování. Rychlé srovnání:
| Typ stránkování | Výhody | Nevýhody | Hodí se pro |
|---|---|---|---|
| Offset-based | Jednoduché, snadná implementace | Při změnách dat může vynechat/duplikovat | Neměnné nebo malé seznamy |
| Cursor-based | Stabilní, dobře zvládá změny dat | O něco složitější | News feedy, velké seznamy |
Pro většinu seznamů zpráv nebo leadů v reálném čase je nejlepší cursor-based stránkování. Drží konzistenci i ve chvíli, kdy přibývají nové položky nebo se staré mažou ().
Tipy pro stránkování v Apollo:
- Nastav
keyArgs, ať máš pod kontrolou cache klíče pro stránkovaná pole (). - Implementuj
mergefunkci pro skládání stránek v cache. - Používej
fetchMorepro načtení dalších stránek bez přepsání předchozích výsledků.
Praktické vzory stránkování pro nástroje na scraping zpráv
Typické UI pro scraping zpráv:
- Ukáže posledních 20–50 titulků (jen lehká pole)
- Další položky dotahuje při scrollu nebo kliknutí na „další stránku“
- Detaily načítá až na vyžádání
Výsledek: rychlé UI, spokojené API a produktivní lidi.
Integrace Thunderbit pro automatizovanou extrakci zpráv
A teď ta zásadní otázka: odkud se vlastně berou strukturovaná zpravodajská data? Tady nastupuje .
Thunderbit je no‑code AI 웹 스크래퍼 rozšíření pro Chrome, které umí z prakticky jakéhokoli webu vytáhnout titulky, URL, zdroje, autory, datum publikace, shrnutí i obrázky – bez programování. Viděl jsem týmy, které s Thunderbit zautomatizovaly celý proces extrakce zpráv: z nestrukturovaných stránek udělaly čistá strukturovaná data, která pak rovnou posílají do databáze nebo GraphQL API.
Jak kombinovat Thunderbit s Apollo pro zpravodajská data v reálném čase
Workflow, který se mi osvědčil pro obchod a operativu, když potřebují aktuální zprávy:
- Vrstva extrakce: Použij Thunderbit šablonu a pravidelně stahuj strukturovaná data z cílových webů.
- Vrstva uložení: Ulož data do databáze optimalizované na rychlé čtení.
- GraphQL vrstva: Vystav přes API seznamové pole
newsFeeda detailní polenewsArticle(id). - Klientská vrstva: V Apollo Client načítej seznam (lehké pole, stránkování) a detaily dotahuj jen když jsou potřeba.
Tahle pipeline „scrape → store → query“ znamená, že Apollo dotazy pracují s čerstvými, strukturovanými daty – bez ručního kopírování a bez křehkých skriptů.
Bonus: Thunderbit umí seznamy i obohacovat o další pole (třeba sentiment nebo kategorii) díky AI návrhům polí, takže tvůj feed může být ještě chytřejší.
Podrobný postup: optimalizace dotazů na seznamy v Apollo
Chceš to převést do praxe? Tady je můj checklist pro optimalizaci dotazů na seznamy v Apollo:
-
Odlehči dotazy
- Ptej si jen pole nutná pro vykreslení seznamu (titulek, URL, čas atd.).
- Těžká pole (plný text, obrázky, obohacení) přesuň do detailních dotazů.
-
Zaveď stránkování
- Pro velké nebo dynamické seznamy použij cursor-based stránkování.
- Nastav
keyArgsamergefunkce, aby cache fungovala správně.
-
Využij Apollo cache
- Normalizuj entity pomocí stabilních ID.
- Vyber správnou fetch policy (
cache-and-networkje pro zprávy top). - Dolaď velikost cache a garbage collection podle objemu dat.
-
Zapoj automatizovanou extrakci
- Použij Thunderbit pro automatizaci scrapingu zpráv a udržuj data čerstvá.
- Exportuj strukturovaná data přímo do databáze nebo tabulky.
-
Měř a řeš problémy
- Použij pro kontrolu dotazů, cache a výkonu.
- Hlídej velké zápisy do cache, příliš mnoho „watched queries“ a trhání UI.
- Sleduj p95/p99 latenci a chybovost (, ).
Monitoring a ladění výkonu dotazů
Apollo Devtools jsou v tomhle fakt k nezaplacení. Umožní ti:
- Prohlédnout aktivní dotazy a stav cache
- Odhalit duplicitní dotazy nebo příliš mnoho watcherů
- Najít velké cache bloky nebo problémy s normalizací
Když vidíš lag v UI nebo pomalé aktualizace, zkontroluj:
- Příliš „těžké“ dotazy na seznam (zjednoduš je)
- Špatnou normalizaci cache (oprav ID)
- Problémy se slučováním stránek (projeď
keyArgsamerge)
A nezapomeň měřit i tail latenci, ne jen průměry – právě tam se schovává největší bolest uživatelů.
Srovnání tradičního přístupu vs. AI extrakce zpráv
Upřímně: dřív znamenal scraping zpráv psaní vlastních skriptů, hraní si s headless prohlížeči a modlení, aby se přes noc nezměnil layout webu. Dnes s AI nástroji jako Thunderbit zvládneš celý proces automatizovat – bez kódu a bez nervů.
| Přístup | Silné stránky | Omezení pro byznys uživatele |
|---|---|---|
| Skriptovaný scraping | Plně přizpůsobitelné, levné ve velkém měřítku | Vysoká údržba, vyžaduje čas vývojářů |
| Spravované scraping platformy | Rychlý start, řeší anti-bot ochrany | Pořád je potřeba konfigurace, cena roste s využitím |
| AI extrakce (Thunderbit) | Zvládá „nepořádek“ v layoutu, bez kódu | Výstup chce kontrolu, napojení na vaše schéma |
| No-code vizuální scrapery | Přístupné i bez vývojářů | Může se rozbít při změnách UI, omezené škálování |
| Proxy/unlocker infrastruktura | Obchází blokace, vysoká propustnost | Stále potřebujete extrakční logiku, rizika compliance |
Právní poznámka: Scraping veřejných dat je obecně legální, ale vždy respektuj podmínky služby a rate limity ().
Klíčové poznatky: osvědčené postupy pro seznamy v Apollo GraphQL
To nejdůležitější v kostce:
- Optimalizuj pro rychlost a přehlednost: odlehči dotazy na seznam, stránkuj a využij cache naplno.
- Struktura rozhoduje: načítej jen to, co potřebuješ – těžká pole přesuň do detailů.
- Cache je tvůj parťák: normalizace a fetch policy v Apollo umí doručit data skoro okamžitě.
- Automatizuj extrakci: nástroje jako zpřístupní scraping a obohacování seznamů každému.
- Měř a iteruj: Devtools a observability dashboardy ti pomůžou odhalit úzká místa včas.
Pro obchod, operativu i zpravodajské týmy to znamená míň čekání, víc akce – a hlavně výrazně méně zpráv typu „proč je to zase tak pomalé?“ na Slacku.
Závěr: další kroky pro optimalizaci seznamů v Apollo
Jestli pořád používáš těžké dotazy bez stránkování nebo dotazy, které si s cache nerozumí, je nejvyšší čas udělat audit a pár úprav. Začni jednoduše: omez pole, přidej stránkování a dolaď cache. Pak přidej vyšší level – integraci automatizovaných extrakčních nástrojů jako , aby data byla čerstvá a použitelná.
Chceš jít víc do hloubky? Mrkni na , nebo se přidej do pro tipy z praxe a řešení problémů. A pokud chceš automatizovat extrakci zpráv, vyzkoušej Thunderbit šablonu – pro každého, kdo potřebuje data v reálném čase bez bolesti, je to game changer.
Ať se dotazy daří – a ať se tvoje seznamy načtou dřív, než ti vystydne kafe.
Nejčastější dotazy (FAQ)
1. Proč se dotazy na seznamy v Apollo zpomalují u dashboardů se zprávami nebo prodejem v reálném čase?
Seznamové dotazy bývají pomalé, když tahají příliš mnoho dat, nemají stránkování nebo nejsou správně cachované. U workflow s vysokou frekvencí (např. monitoring zpráv) se i malé prodlevy sčítají, což vede k lagům v UI a ztrátě produktivity.
2. Jak nejlépe strukturovat dotazy na seznamy v Apollo pro automatizovanou extrakci zpráv?
Vyžádej si jen pole potřebná pro vykreslení seznamu (např. titulek, URL, čas). Těžká pole (např. plný text článku nebo obrázky) přesuň do detailních dotazů a výsledky stránkuj, aby payload zůstal malý a rychlý.
3. Jak cache v Apollo Client zlepšuje výkon seznamů?
Apollo cache ukládá dříve načtená data, takže opakované dotazy můžou být okamžité. Správná normalizace a vhodné fetch policy (např. cache-and-network) dokážou výrazně zrychlit seznamy a snížit zátěž serveru.
4. Jak může Thunderbit pomoct se scrapingem zpráv a integrací s Apollo?
Thunderbit je no‑code AI 웹 스크래퍼, který z libovolného webu vytáhne strukturovaná zpravodajská data. Můžeš s ním automatizovat extrakci a pak data posílat do databáze nebo GraphQL API, které používá Apollo Client.
5. Jaké nástroje použít pro monitoring a ladění výkonu dotazů na seznamy v Apollo?
ti umožní v reálném čase kontrolovat dotazy, stav cache i výkon. Doplň to observability dashboardy (např. New Relic nebo Uptrends) pro sledování latence a chybovosti a průběžně upravuj návrh dotazů.
Chceš víc tipů k web scrapingu, automatizaci a práci s daty v reálném čase? Podívej se na – najdeš tam detailní články, návody i novinky z oblasti produktivity s AI.
Zjistit více