Najmout vývojáře na web scraping bývalo spíš takové „nice to have“ — něco, co řešili hlavně datoví vědci nebo občas technicky zdatný marketér. Jenže v roce 2025 mám pocit, že skoro každý tým ze sales, operativy nebo marketingu, se kterým mluvím, shání freelance experta na web scraping nebo specialistu na extrakci webových dat. Proč? Protože web je největší a zároveň nejchaotičtější databáze na světě — a tlak proměnit tenhle zmatek v použitelné insighty pořád roste. Na vlastní oči jsem viděl, jak správný (nebo špatný) člověk dokáže projekt zachránit, nebo ho naopak potopit — někdy opravdu velkolepě.
Trh s web scrapingem a extrakcí dat letí nahoru; globální výdaje se mají během příští dekády zčtyřnásobit (). Jenže weby se pořád mění, anti-bot ochrany jsou čím dál chytřejší a byznys uživatelé chtějí čistší data rychleji — ideálně „včera“. Proto je výběr správného člověka (nebo správného nástroje) důležitější než kdy dřív. Ať už jste zakladatel, vedoucí týmu, nebo „ten datový člověk“, na kterého to zbylo, pojďme si rozebrat, jak najmout vývojáře pro web scraping — a kdy ho možná vůbec nepotřebujete.
Co dělá vývojář pro web scraping?
Vývojář pro web scraping je v praxi takový „překladatel“ mezi divokým internetem a přehlednými tabulkami, které váš tým fakt využije. Jeho práce je převést proměnlivé, často neuhlazené webové stránky do strukturovaných a spolehlivých datasetů — typicky CSV, JSON nebo rovnou napojení do databáze. Nejde ale jen o rychlý skript „na zkoušku“. Ta skutečná dřina je zajistit, aby to běželo i zítra: když se web změní, když je potřeba řešit stránkování, podstránky, anti-bot překážky a všechny ty moderní webové „vychytávky“ ().
Typické odpovědnosti zahrnují:
- Analýzu webových stránek a volbu nejlepší metody získání dat (HTML scraping, API volání, headless prohlížeče)
- Zpracování dynamického obsahu, renderování JavaScriptu a přihlašovacích toků
- Řešení stránkování a obohacování přes podstránky (např. stáhnout seznam produktů a pak navštívit detail každého produktu)
- Export čistých dat připravených pro analýzu (CSV, JSON, databáze nebo přímá integrace)
- Nastavení monitoringu, opakování pokusů a upozornění, když se něco rozbije (protože rozbije)
- Dokumentaci datové specifikace, definic polí a harmonogramu obnovy
Freelance experti na web scraping se často berou na jednorázovky, konkrétní cíle nebo rychlé prototypy. Interní specialisté na extrakci webových dat dávají smysl ve chvíli, kdy je získávání dat klíčová a dlouhodobá součást byznysu — třeba denní monitoring cen, generování leadů nebo napájení interního dashboardu ().
Pro netechnické týmy jsou tyhle role k nezaplacení: mění hodiny ručního kopírování a vkládání na automatizované workflow a uvolňují analytiky i obchodníky pro práci, která má reálný dopad.
Klíčové dovednosti a zkušenosti, které hledat při najímání vývojáře pro web scraping
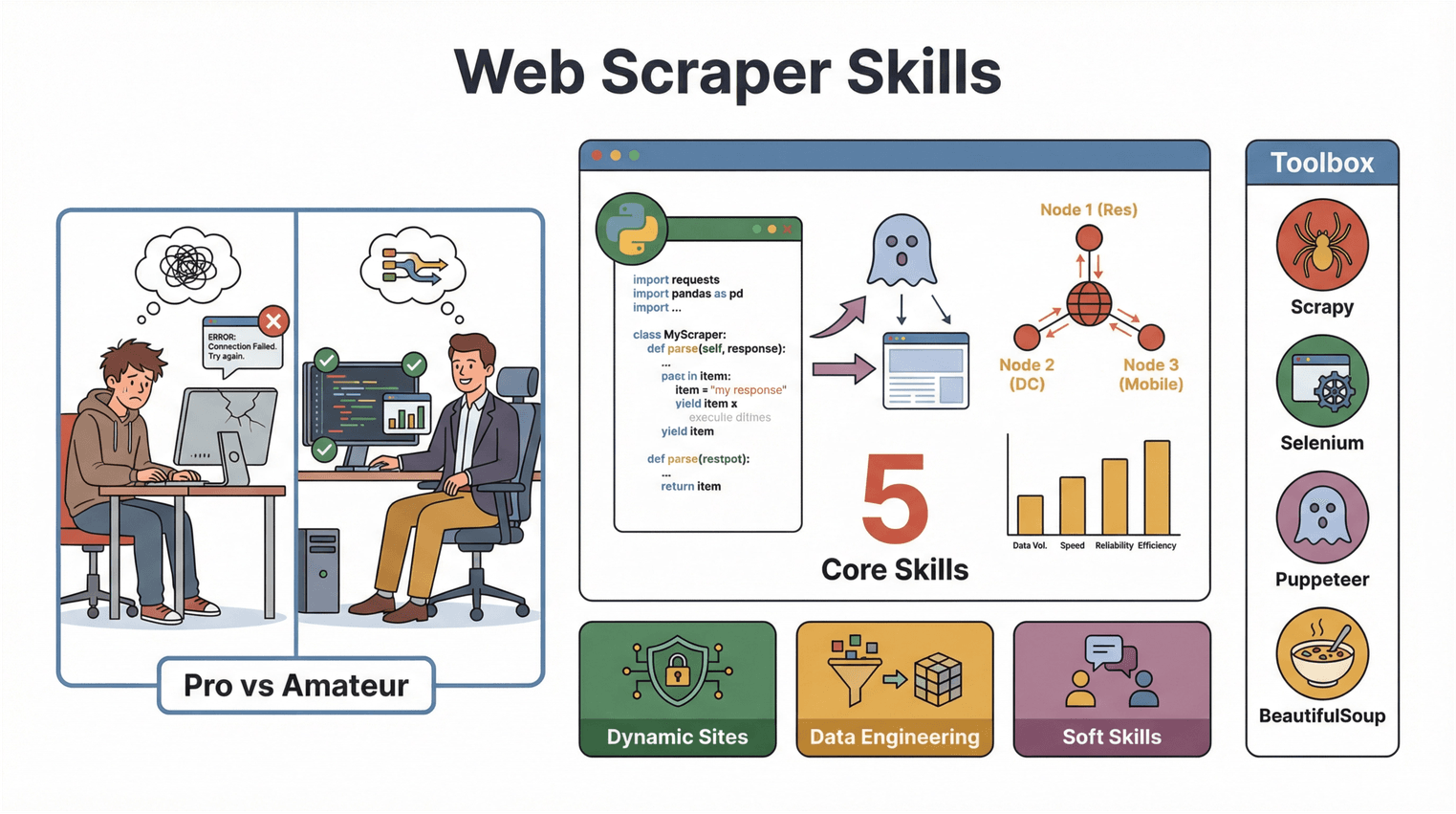
Ne každý scraper je stejně dobrý. Za ta léta jsem potkal vývojáře, kteří napíšou skript za odpoledne — ale udržet ho v chodu déle než týden je pro ně mission impossible. Tohle obvykle odděluje profíky od amatérů:
- Pokročilé programování: Nejčastěji Python, ale běžný je i JavaScript, Node.js nebo Go. Hledejte zkušenost s knihovnami jako BeautifulSoup, Scrapy, Selenium nebo Puppeteer.
- Zkušenost s nástroji pro web scraping: Plus je znalost jak kódových, tak no-code nástrojů (např. ). Nejlepší kandidáti vědí, kdy použít nástroj a kdy stavět řešení na míru.
- Práce s dynamickými a chráněnými weby: Moderní weby milují JavaScript a anti-bot obranu. Vývojář by měl umět headless prohlížeče, proxy, CAPTCHA i práci se sessions.
- Data engineering přístup: Nejde jen o získání dat — stejně důležité je čištění, deduplikace, validace a strukturování.
- Měkké dovednosti: Komunikace, pečlivost a schopnost řešit problémy. Chcete někoho, kdo se doptá na detaily, ne jen někoho, kdo řekne „jasně, to seškrábu“.
Checklist technických dovedností
Rychlý seznam, který můžete použít při prvním třídění kandidátů:
| Nezbytné dovednosti | Příjemné navíc |
|---|---|
| Python (nebo JS/Node) | Zkušenost s cloudovými scraping platformami |
| Parsování HTML/CSS/DOM | Znalost kontejnerizace (Docker) |
| Řešení stránkování a podstránek | Nastavení monitoringu, logování a alertů |
| Anti-bot strategie (proxy, throttling) | Integrace do datových pipeline (ETL, API) |
| Validace dat a QA | Povědomí o compliance a ochraně soukromí |
| Zkušenost s nástroji jako Thunderbit, Octoparse | Zkušenost s AI asistovanou extrakcí |
Bonus: kandidáti, kteří umí pracovat s nástroji jako , často dodají výsledek rychleji a s menšími nároky na údržbu — hlavně u běžných byznysových úloh.
Svépomocí vs. najmutí experta na web scraping: srovnání nákladů a efektivity
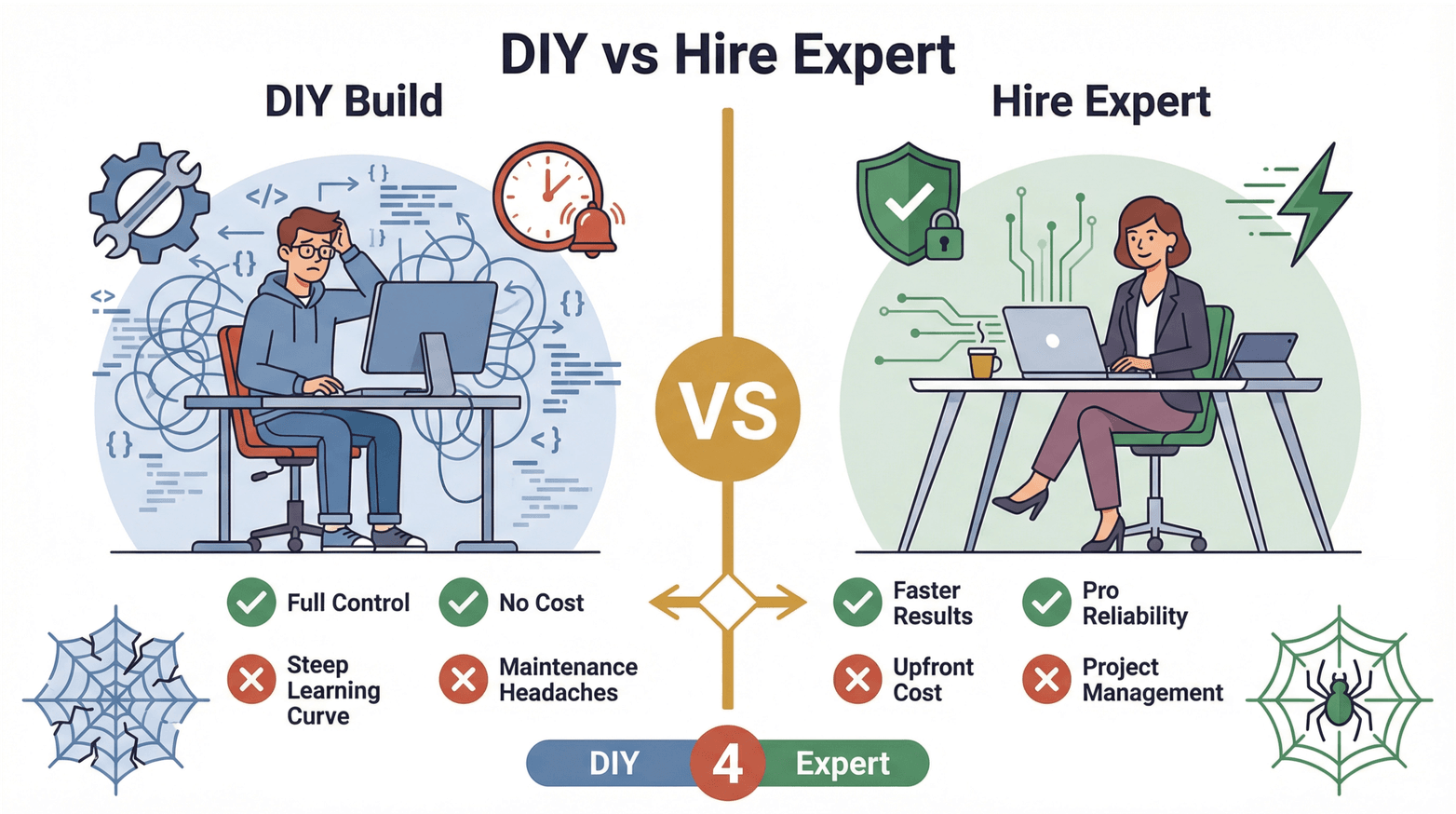
Tak co je lepší: vyhrnout si rukávy a postavit scraper sami, nebo přizvat freelance experta na web scraping? Pojďme to rozebrat.
DIY (udělej si sám):
- Výhody: Plná kontrola, žádné externí náklady, dobré pro učení.
- Nevýhody: Strmá křivka učení, časová náročnost, bolestivá údržba, snadné podcenění složitosti.
Najmutí freelance experta na web scraping:
- Výhody: Rychlejší dodání, profesionální spolehlivost, menší riziko, že se to „rozbije“ při změně webu, přístup ke specializovanému know-how.
- Nevýhody: Počáteční náklad, potřeba řídit projekt, možné komunikační šumy.
Tabulka srovnání nákladů:
| Přístup | Typické náklady | Čas dodání | Údržba |
|---|---|---|---|
| DIY | Váš čas (náklad ušlé příležitosti) | Dny až týdny (pokud se učíte) | Všechny opravy jsou na vás |
| Freelance (hodinově) | $20–$40/h (upwork.com) | 1–2 týdny u většiny projektů | Lze domluvit průběžnou podporu |
| Freelance (fixně) | $500–$5,000+ (upwork.com) | 1–4 týdny podle rozsahu | Údržba může být extra |
| Interní pozice | $100k+/rok (glassdoor.com) | Průběžně | Plné vlastnictví (i náklady) |
Kdy dává DIY smysl? Když máte technické zázemí, úloha je jednoduchá a nevadí vám si s tím pohrát. U čehokoli kritického pro byznys, ve velkém objemu nebo s častými změnami se specialista obvykle rychle zaplatí.
Kdy zvolit specialistu na extrakci webových dat
Zvažte najmutí specialisty na extrakci webových dat, pokud:
- potřebujete získávat data z komplexních, dynamických nebo chráněných webů
- data jsou pro byznys zásadní nebo se musí pravidelně obnovovat
- potřebujete integraci do dalších systémů (CRM, databáze, API)
- řešíte compliance, soukromí nebo právní aspekty
- chcete se vyhnout dlouhodobé údržbě a řešení incidentů
Pro rychlé jednorázové stažení nebo jednoduché budování seznamů vám může stačit nástroj jako .
Kde hledat a najmout vývojáře pro web scraping a freelance experty
Míst, kde sehnat lidi na web scraping, je spousta — každá platforma má ale svoje „ale“ a specifika.
- : Největší výběr od juniorů po zkušené profíky. Můžete jet hodinově i fixně a riziko si pohlídat přes milníky.
- : Fajn pro cenově citlivé projekty s jasnými výstupy. Milníkové platby pomáhají hlídat postup.
- : Prémiová, předem prověřená komunita. Ideální, pokud chcete outsourcovat samotné prověřování a nevadí vám vyšší cena.
- Fiverr: Nejlepší pro malé, přesně vymezené úkoly („gigs“). U složitých nebo dlouhodobých projektů buďte opatrní.
Tipy, jak kandidáty filtrovat:
- Hledejte profily s konkrétní zkušeností s web scrapingem (ne jen „Python developer“)
- Ověřte relevantní zkušenost z oboru (např. ecommerce, reality, B2B leady)
- Projděte portfolio a vyžádejte si ukázkové projekty nebo úryvky kódu
- Pečlivě čtěte recenze a hodnocení
Tipy pro screening a pohovor
Nespoléhejte jen na sliby. Takhle kandidáty rád prověřuji:
Klíčové otázky:
- Můžete popsat nedávný projekt web scrapingu, který jste dodal/a? Jaké byly největší výzvy?
- Jak řešíte weby s JavaScriptem nebo anti-bot ochranou?
- Jak zajišťujete kvalitu a spolehlivost dat?
- Jak dokumentujete práci pro předání nebo budoucí údržbu?
- Jaký je váš compliance checklist před startem nového projektu?
Praktické testy:
- Dejte ukázkový web se strukturou seznam + detail. Požádejte o CSV s obohacenými daty.
- Nechte kandidáta připravit krátký „datový kontrakt“ (definice polí, povinnost, frekvence obnovy) ještě před kódováním.
- Požádejte o krátké demo scrapingu tabulky, která se renderuje přes JavaScript.
Jak Thunderbit snižuje závislost na vývojářích pro web scraping
Malé tajemství: většina byznys uživatelů nepotřebuje pro každý úkol scraper na míru. Nástroje jako zásadně změnily hru pro netechnické týmy.
Thunderbit je , která vám umožní vytáhnout strukturovaná data téměř z jakéhokoli webu na pár kliknutí. Stačí popsat, co chcete, kliknout na „AI Suggest Fields“ a AI v Thunderbitu doplní zbytek. Umí i scraping podstránek, stránkování a export přímo do Excelu, Google Sheets, Airtable nebo Notion.
Proč je to důležité při najímání? Protože Thunderbit zmenšuje počet projektů, které skutečně vyžadují vývojáře. Pro sales, ecommerce a výzkumné týmy je často rychlejší (a levnější) použít Thunderbit na rutinní tahání dat, seznamy leadů nebo monitoring cen. Těžké inženýrství si nechte na opravdu složité případy.
Thunderbit vs. tradiční přístupy k web scrapingu
Porovnejme workflow Thunderbitu s najmutím freelance experta na web scraping:
| Faktor | Thunderbit | Freelance expert |
|---|---|---|
| Čas nastavení | Minuty (bez kódu) | Dny až týdny |
| Cena | Free tier, poté $15–$249/měs. (Thunderbit Pricing) | $500–$5,000+ za projekt |
| Údržba | AI se přizpůsobuje změnám webu | Nutné ruční úpravy |
| Možnosti exportu | Excel, Sheets, Airtable, Notion, CSV, JSON | Různé (často CSV/JSON) |
| Podstránky/stránkování | Vestavěné, na 2 kliknutí | Nutný kód na míru |
| Nejlepší pro | Rychlé, časté, lehké úlohy | Složité, velkoobjemové, vlastní integrace |
Kdy má pořád smysl najmout vývojáře? U kritických datových pipeline, „tvrdých cílů“ (např. weby za loginem nebo s agresivní ochranou) nebo když potřebujete vlastní integrace a monitoring.
Jak řídit úspěšné outsourcované projekty web scrapingu
Najít správného člověka je teprve start. Dobré řízení projektu je to, co udrží všechno na kolejích (a zabrání momentům typu „kde jsou moje data?“).
Doporučené postupy:
- Jasně definujte „datový kontrakt“ hned na začátku: Seznam požadovaných polí, datové typy, frekvence obnovy a akceptační kritéria ().
- Používejte milníky a escrow: Rozdělte projekt na části (vzorek datasetu, plný běh, plánované spouštění, monitoring) a uvolňujte platbu až po dodání ().
- Nastavte QA brány: Ověřte deduplikaci, validaci a připravenost dat pro váš use case.
- Počítejte s údržbou: Scraper se rozbije. Pokud jsou data kritická, domluvte si retainer nebo plán údržby.
- Všechno dokumentujte: Trvejte na README, runbooku a popisu známých režimů selhání. Dobrá dokumentace vás později ochrání před drahými překvapeními.
Tipy pro komunikaci a spolupráci
- Pravidelné check-iny: Týdenní update nebo demo udrží sladění.
- Sdílené nástroje pro řízení práce: Trello, Asana nebo Google Docs pro postup a zpětnou vazbu.
- Jasná eskalace: Předem si určete, jak se budou řešit blokery a incidenty.
- Podporujte dotazy: Nejlepší freelanceři se doptávají brzy a často.
Právní, etické a compliance aspekty při najímání vývojáře pro web scraping
Web scraping už není taková „divočina“ jako dřív. Existují reálná právní i etická rizika — hlavně u osobních údajů, podmínek používání a obcházení anti-bot ochran.
Hlavní body:
- Veřejná data ≠ cokoliv je dovoleno: I scraping veřejně dostupných dat může nést právní rizika, zejména pokud obcházíte technické bariéry nebo ignorujete podmínky služby ().
- Záleží na zákonech o soukromí: GDPR, CCPA a další regulace vyžadují odůvodnění sběru, minimalizaci dopadu a respektování opt-outů ().
- Compliance checklist: Omezte scraping na schválené weby a typy dat, vyhněte se citlivým/osobním údajům bez výslovného povolení, dokumentujte postup a bezpečně pracujte s přihlašovacími údaji ().
- Transparentnost: Řekněte vývojáři jasně, jaké compliance požadavky máte, a zahrňte je do zadání.
Nástroje jako Thunderbit pomáhají tím, že se zaměřují na veřejná, byznysově relevantní data a usnadňují dokumentaci toho, co sbíráte a proč.
Postup krok za krokem: jak najmout vývojáře pro web scraping
Chcete začít? Tady je jednoduchý, praktický postup:
- Ujasněte potřeby: Jaká data potřebujete? Z jakých webů? Jak často? V jakém formátu?
- Sepište „datový kontrakt“: Požadovaná pole, datové typy, frekvence obnovy a akceptační kritéria.
- Vyberte platformu: Upwork, Freelancer, Toptal nebo Fiverr — podle rozpočtu, termínu a míry prověřování.
- Zveřejněte poptávku: Buďte konkrétní v deliverables, termínech i compliance požadavcích.
- Prosejte kandidáty: Použijte checklist a otázky výše. Vyžádejte si ukázku práce nebo malý placený test.
- Domluvte milníky: Rozdělte projekt na logické části s jasnými výstupy.
- Řiďte realizaci: Pravidelné check-iny, QA brány a sdílené nástroje pro sledování postupu.
- Naplánujte údržbu: Jak se budou řešit aktualizace, opravy a změny.
- Trvejte na dokumentaci: README, runbook a jasný proces předání.
A nezapomeňte: u spousty rutinních úloh možná nemusíte najímat nikoho — nejdřív zkuste a ověřte, jestli vám stačí.
Závěr a hlavní poznatky
Najmout vývojáře pro web scraping už není jen doména technologických gigantů — je to důležitý krok pro každý tým, který chce proměnit webová data v byznysovou hodnotu. Jenže s tím, jak trh web scrapingu a extrakce dat roste o více než , rostou i sázky (a složitost).
Co je nejdůležitější:
- Hledejte vývojáře se silným programováním, reálnou zkušeností se scrapingem a data engineering přístupem.
- Využijte platformy jako Upwork, Freelancer a Toptal pro hledání a prověření — a projekt řiďte přes jasné kontrakty, milníky a QA brány.
- Pro rutinní úlohy s rychlým obratem vám nástroje jako ušetří čas, peníze i nervy — bez kódu.
- Compliance, soukromí a dokumentace musí být vždy na prvním místě.
- Nejlepší výsledky přináší jasná očekávání, pravidelná komunikace a ochota přizpůsobit se tomu, jak se weby (nevyhnutelně) mění.
Než někoho najmete, položte si otázku: je to jednorázovka, opakovaná potřeba, nebo kritická pipeline? Někdy je nejchytřejší posílit tým snadno použitelným nástrojem — a těžkou práci si nechat na chvíli, kdy je opravdu potřeba.
Chcete vidět, kolik toho zvládnete bez vývojáře? a vyzkoušejte to. A pokud chcete další tipy k web scrapingu, automatizaci dat nebo budování moderního data stacku, mrkněte na .
Časté dotazy (FAQ)
1. Jaký je rozdíl mezi freelance expertem na web scraping a interním specialistou na extrakci webových dat?
Freelancer se obvykle najímá na konkrétní krátkodobé projekty nebo úzce zaměřené cíle, zatímco interní specialista spravuje dlouhodobé, pro byznys klíčové datové pipeline a integrace.
2. Kolik stojí najmutí vývojáře pro web scraping?
Freelanceři si typicky účtují $20–$40 za hodinu nebo $500–$5,000+ za projekt podle složitosti. Interní role mohou stát $100k+ ročně. Nástroje jako Thunderbit fungují na předplatném od $15/měsíc.
3. Jaké dovednosti mám hledat při najímání vývojáře pro web scraping?
Hledejte silné programování (Python, JS), zkušenost s dynamickými weby a anti-bot strategiemi, data engineering know-how a orientaci jak v kódových, tak no-code nástrojích typu Thunderbit.
4. Kdy použít nástroj jako Thunderbit místo najímání vývojáře?
Thunderbit je ideální pro rychlé, časté nebo jednorázové tahání dat, generování leadů nebo monitoring cen — zejména když potřebujete strukturovaný export a minimální nastavení. Vývojáře najměte pro složité, kritické nebo vysoce custom projekty.
5. Jaké právní nebo compliance otázky řešit při najímání na web scraping?
Vždy respektujte podmínky webu, zákony o soukromí (např. GDPR/CCPA) a neškrábejte citlivá či osobní data bez výslovného souhlasu. Dokumentujte postup a zajistěte, že vývojář dodržuje best practices pro compliance.
Chcete, aby váš další datový projekt dopadl skvěle? Začněte správným plánem, správnými lidmi a správnými nástroji — a uvidíte, o kolik víc toho zvládnete.
Zjistěte více