
Webových dat přibývá raketovou rychlostí — a s tím roste i tlak držet tempo. Z vlastní zkušenosti vím, že obchodní a provozní týmy často stráví víc času zápasením s tabulkami a nekonečným kopírováním z webů než tím, co je opravdu důležité: rozhodováním. Podle Salesforce dnes obchodníci věnují a Asana uvádí, že . To jsou hodiny vyhozené za ruční sběr dat — hodiny, které by se daly proměnit v uzavřené obchody nebo spuštěné kampaně.
Dobrá zpráva: web scraping je dnes už úplně běžná věc a nemusíš být vývojář, abys z něj vytěžil(a) maximum. Ruby je dlouhodobě oblíbené pro automatizaci sběru dat z webu, ale když ho spojíš s moderními AI nástroji pro scraping, jako je , dostaneš to nejlepší z obou světů — flexibilitu pro programátory a web scraper bez kódu pro všechny ostatní. Ať už jsi marketér, e‑commerce manažer, nebo prostě někdo, koho už nebaví věčné copy‑paste, tenhle průvodce ti ukáže, jak dostat web scraping v Ruby a s AI do ruky — klidně i bez psaní kódu.
Co je web scraping v Ruby? Váš vstup do automatizovaného sběru dat
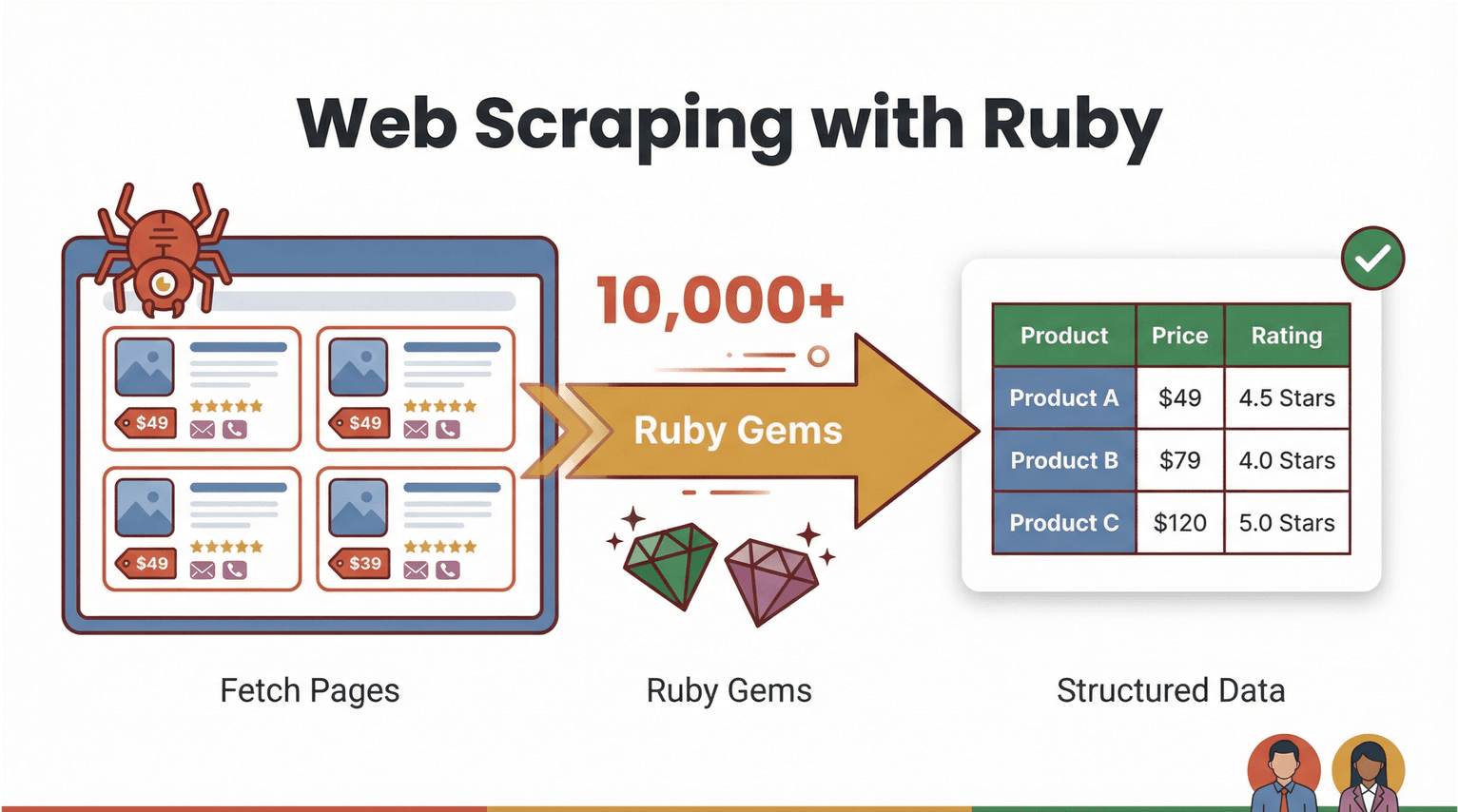
Pojďme od podlahy. Web scraping je proces, kdy software stáhne webovou stránku a vytáhne z ní konkrétní informace — třeba ceny produktů, kontakty nebo recenze — do strukturované podoby (například CSV nebo Excel). V Ruby je scraping zároveň výkonný i docela přívětivý. Jazyk je proslulý čitelnou syntaxí a obrovským ekosystémem „gemů“ (knihoven), které automatizaci výrazně zjednodušují ().
Jak tedy „web scraping v Ruby“ vypadá v reálu? Představ si, že chceš z e‑shopu stáhnout názvy produktů a jejich ceny. V Ruby si můžeš napsat skript, který:
- Stáhne webovou stránku (například pomocí knihovny )
- Zpracuje HTML a najde požadovaná data (s )
- Vyexportuje výsledek do tabulky nebo databáze
A teď to nejlepší: ne vždycky musíš psát kód. AI nástroje pro web scraper bez kódu, jako je , dnes zvládnou velkou část práce za tebe — přečtou stránku, rozpoznají pole a vyexportují čistou tabulku na pár kliknutí. Ruby zůstává skvělé jako „lepidlo“ pro automatizaci vlastních workflow, ale ai web scraper otevírá dveře i lidem z byznysu.
Proč je web scraping v Ruby důležitý pro firemní týmy

Řekněme si to na rovinu: nikdo nechce prosedět den u kopírování a vkládání dat. Poptávka po automatizovaném získávání dat z webu roste raketově — a dává to smysl. Takhle web scraping v Ruby (a AI nástroje) mění firemní provoz:
- Generování leadů: Rychle vytáhneš kontakty z katalogů nebo LinkedIn do obchodního pipeline.
- Monitoring cen konkurence: Sleduj změny cen napříč stovkami SKU — bez ručních kontrol.
- Tvorba produktového katalogu: Agreguj parametry produktů a obrázky pro vlastní e‑shop nebo marketplace.
- Průzkum trhu: Sbírej recenze, hodnocení nebo články pro analýzu trendů.
Návratnost je jasná: týmy, které automatizují sběr dat z webu, ušetří hodiny týdně, sníží chybovost a získají aktuálnější a spolehlivější data. Ve výrobě například , i když se objem dat za poslední dva roky zdvojnásobil. To je obrovský prostor pro automatizaci.
Rychlé shrnutí, jak web scraping v Ruby a AI nástroje přinášejí hodnotu:
| Použití | Bolest ruční práce | Přínos automatizace | Typický výsledek |
|---|---|---|---|
| Generování leadů | Ruční opisování e-mailů | Tisíce kontaktů během minut | 10× více leadů, méně rutiny |
| Monitoring cen | Denní kontrola webů | Plánované, automatické stahování cen | Cenová inteligence v reálném čase |
| Tvorba katalogu | Ruční zadávání dat | Hromadná extrakce a formátování | Rychlejší spuštění, méně chyb |
| Průzkum trhu | Ruční čtení recenzí | Sběr a analýza ve velkém | Hlubší a čerstvější insighty |
A nejde jen o rychlost — automatizace znamená méně chyb a konzistentnější data, což je zásadní, když .
Přehled řešení: Ruby skripty vs. AI Web Scraper nástroje
Napsat si vlastní Ruby skript, nebo radši sáhnout po ai web scraper bez kódu? Pojďme to rozebrat.
Ruby skriptování: maximální kontrola, vyšší nároky na údržbu
Ekosystém Ruby je nabitý gemy pro různé scraping scénáře:
- : Klasika na parsování HTML a XML.
- : Na stahování webových stránek a API.
- : Na weby s cookies, formuláři a navigací.
- / : Na automatizaci skutečného prohlížeče (ideální pro weby postavené na JavaScriptu).
S Ruby skripty máš plnou flexibilitu — vlastní logiku, čištění dat i napojení na interní systémy. Jenže tím na sebe bereš i údržbu: jakmile web změní rozložení, skript se může rozpadnout. A pokud ti kód není blízký, čeká tě i křivka učení.
AI Web Scraper a no‑code nástroje: rychlé, přívětivé a adaptivní
Moderní web scraper bez kódu jako mění pravidla hry. Místo psaní kódu:
- Otevřeš rozšíření v Chromu
- Klikneš na „AI Suggest Fields“ a necháš AI rozpoznat, co se má vytáhnout
- Stiskneš „Scrape“ a data vyexportuješ
AI v Thunderbitu se umí přizpůsobit změnám layoutu, zvládá podstránky (např. detail produktu) a exportuje rovnou do Excelu, Google Sheets, Airtable nebo Notion. Pro byznys uživatele je to ideální: výsledek bez nervů.
Srovnání vedle sebe:
| Přístup | Výhody | Nevýhody | Nejlepší pro |
|---|---|---|---|
| Ruby skripty | Plná kontrola, vlastní logika, flexibilita | Strmější učení, údržba | Vývojáři, pokročilí uživatelé |
| AI Web Scraper | Bez kódu, rychlé nastavení, přizpůsobí se změnám | Méně detailní kontrola, určité limity | Byznys uživatelé, ops týmy |
Trend je jasný: jak jsou weby složitější (a „obrannější“), ai web scraper nástroje se pro většinu firemních workflow stávají volbou číslo jedna.
Začínáme: nastavení prostředí pro web scraping v Ruby
Pokud si chceš vyzkoušet skriptování v Ruby, nejdřív si připravíme prostředí. Dobrá zpráva: Ruby se instaluje snadno a běží na Windows, macOS i Linuxu.
Krok 1: Nainstalujte Ruby
- Windows: Stáhni a projdi instalací. Nezapomeň přidat MSYS2 pro kompilaci nativních rozšíření (potřebné pro gemy jako Nokogiri).
- macOS/Linux: Použij pro správu verzí. V Terminálu:
1brew install rbenv ruby-build
2rbenv install 4.0.1
3rbenv global 4.0.1(Aktuální stabilní verzi najdeš na stránce .)
Krok 2: Nainstalujte Bundler a základní gemy
Bundler pomáhá spravovat závislosti:
1gem install bundlerVytvoř si v projektu Gemfile:
1source 'https://rubygems.org'
2gem 'nokogiri'
3gem 'httparty'Pak spusť:
1bundle installTím si zajistíš konzistentní prostředí připravené na scraping.
Krok 3: Otestujte instalaci
Zkus v IRB (interaktivní shell Ruby):
1require 'nokogiri'
2require 'httparty'
3puts Nokogiri::VERSIONPokud se vypíše číslo verze, máš hotovo.
Krok za krokem: váš první Web Scraper v Ruby
Projdeme si reálný příklad — získání produktových dat z webu , který je určený pro trénink scrapingu.
Tady je jednoduchý Ruby skript, který vytáhne názvy knih, ceny a dostupnost:
1require "net/http"
2require "uri"
3require "nokogiri"
4require "csv"
5BASE_URL = "https://books.toscrape.com/"
6def fetch_html(url)
7 uri = URI.parse(url)
8 res = Net::HTTP.get_response(uri)
9 raise "HTTP #{res.code} for #{url}" unless res.is_a?(Net::HTTPSuccess)
10 res.body
11end
12def scrape_list_page(list_url)
13 html = fetch_html(list_url)
14 doc = Nokogiri::HTML(html)
15 products = doc.css("article.product_pod").map do |pod|
16 title = pod.css("h3 a").first["title"]
17 price = pod.css(".price_color").text.strip
18 stock = pod.css(".availability").text.strip.gsub(/\s+/, " ")
19 { title: title, price: price, stock: stock }
20 end
21 next_rel = doc.css("li.next a").first&.[]("href")
22 next_url = next_rel ? URI.join(list_url, next_rel).to_s : nil
23 [products, next_url]
24end
25rows = []
26url = "#{BASE_URL}catalogue/page-1.html"
27while url
28 products, url = scrape_list_page(url)
29 rows.concat(products)
30end
31CSV.open("books.csv", "w", write_headers: true, headers: %w[title price stock]) do |csv|
32 rows.each { |r| csv << [r[:title], r[:price], r[:stock]] }
33end
34puts "Wrote #{rows.length} rows to books.csv"Skript stáhne každou stránku, zpracuje HTML, vytáhne data a uloží je do CSV. Soubor books.csv pak otevřeš v Excelu nebo Google Sheets.
Časté problémy:
- Pokud hlásí chybějící gemy, zkontroluj Gemfile a spusť
bundle install. - U webů, které načítají data přes JavaScript, budeš potřebovat automatizaci prohlížeče jako Selenium nebo Watir.
Vylepšete scraping v Ruby s Thunderbit: AI Web Scraper v praxi
Teď se mrkneme, jak ti pomůže posunout scraping o level výš — bez psaní kódu.
Thunderbit je , které umí vytáhnout strukturovaná data z libovolného webu doslova na dvě kliknutí. Funguje to takhle:
- Otevřeš rozšíření Thunderbit na stránce, ze které chceš data.
- Klikneš na „AI Suggest Fields“. AI projde stránku a navrhne nejlepší sloupce (např. „Název produktu“, „Cena“, „Skladem“).
- Klikneš na „Scrape“. Thunderbit data stáhne, zvládne stránkování a v případě potřeby projde i podstránky.
- Vyexportuješ data rovnou do Excelu, Google Sheets, Airtable nebo Notion.
Thunderbit boduje tím, že si poradí i se složitými a dynamickými stránkami — bez křehkých selektorů a bez kódu. A pokud chceš workflow kombinovat, můžeš data vytáhnout v Thunderbitu a pak je dál zpracovat nebo obohatit Ruby skriptem.
Tip: Funkce scrapingu podstránek je k nezaplacení pro e‑commerce a realitní týmy. Vytáhneš seznam odkazů na produkty a Thunderbit pak každý detail navštíví a doplní specifikace, obrázky nebo recenze — automaticky tak obohatí dataset.
Příklad z praxe: scraping produktů a cen v e‑commerce pomocí Ruby a Thunderbit
Pojďme to spojit do praktického workflow pro e‑commerce týmy.
Scénář: Chceš sledovat ceny konkurence a detaily produktů napříč stovkami SKU.
Krok 1: Thunderbit pro scraping hlavního seznamu produktů
- Otevři stránku s výpisem produktů konkurence.
- Spusť Thunderbit a klikni na „AI Suggest Fields“ (např. Název produktu, Cena, URL).
- Klikni na „Scrape“ a exportuj do CSV.
Krok 2: Obohacení dat přes scraping podstránek
- V Thunderbitu použij „Scrape Subpages“ a nech projít detail každého produktu a vytáhnout další pole (např. popis, dostupnost nebo obrázky).
- Exportuj obohacenou tabulku.
Krok 3: Zpracování nebo analýza v Ruby
- Pomocí Ruby skriptu data dočisti, transformuj nebo analyzuj. Například můžeš:
- Přepočítat ceny do jednotné měny
- Odfiltrovat vyprodané položky
- Vygenerovat souhrnné statistiky
Jednoduchý Ruby příklad pro výběr položek skladem:
1require 'csv'
2rows = CSV.read('products.csv', headers: true)
3in_stock = rows.select { |row| row['stock'].include?('In stock') }
4CSV.open('in_stock_products.csv', 'w', write_headers: true, headers: rows.headers) do |csv|
5 in_stock.each { |row| csv << row }
6endVýsledek:
Z webových stránek se během chvíle dostaneš k čisté, použitelné tabulce — připravené pro cenovou analýzu, plánování zásob nebo marketingové kampaně. A zvládl(a) jsi to bez jediné řádky „scraping“ kódu.
Bez kódu? Žádný problém: automatizovaný sběr webových dat pro každého
Na Thunderbitu je super, jak dává sílu do rukou i netechnickým lidem. Nemusíš znát Ruby, HTML ani CSS — stačí otevřít rozšíření, nechat AI pracovat a data vyexportovat.
Křivka učení: U Ruby skriptů se musíš naučit základy programování a pochopit strukturu webu. U Thunderbitu je nastavení otázka minut, ne dnů.
Integrace: Thunderbit exportuje přímo do nástrojů, které týmy běžně používají — Excel, Google Sheets, Airtable, Notion. Navíc si můžeš nastavit pravidelné (plánované) scrapingy pro průběžné sledování.
Zkušenosti z praxe: Viděl jsem marketingové týmy, sales ops i e‑commerce manažery, jak s Thunderbitem automatizují všechno od tvorby seznamů leadů po sledování cen — bez zapojení IT.
Best practices: jak kombinovat Ruby a AI Web Scraper pro škálovatelnou automatizaci
Chceš robustní a škálovatelné workflow? Tady jsou moje top tipy:
- Počítej se změnami webu: AI Web Scraper jako Thunderbit se přizpůsobí automaticky, ale u Ruby skriptů musíš při změnách webu upravit selektory.
- Plánuj scraping: Využij plánování v Thunderbitu pro pravidelné stahování dat. U Ruby nastav cron nebo plánovač úloh.
- Zpracování po dávkách: U velkých datasetů scrapuj po dávkách, ať snížíš riziko blokace a zbytečně nezatěžuješ systém.
- Formátování dat: Před analýzou data vždy vyčisti a validuj — exporty z Thunderbitu jsou strukturované, ale vlastní Ruby skripty můžou potřebovat extra kontrolu.
- Soulad s pravidly: Scrapuj jen veřejně dostupná data, respektuj
robots.txta mysli na ochranu soukromí (v EU obzvlášť — ). - Záložní plán: Pokud je web příliš složitý nebo scraping blokuje, hledej oficiální API nebo alternativní zdroje dat.
Kdy použít co?
- Ruby skripty použij, když potřebuješ plnou kontrolu, vlastní logiku nebo integraci s interními systémy.
- Thunderbit použij, když chceš rychlost, jednoduchost a adaptabilitu — hlavně pro jednorázové i opakované byznys úkoly.
- Kombinuj obojí pro pokročilé scénáře: Thunderbit pro extrakci, Ruby pro obohacení, kontrolu kvality nebo integrace.
Závěr a hlavní poznatky
web scraping v ruby byl vždycky taková „superschopnost“ pro automatizaci sběru dat — a díky ai web scraper nástrojům jako Thunderbit je dnes dostupný prakticky každému. Ať jsi vývojář, který chce flexibilitu, nebo byznys uživatel, který chce hlavně výsledek, můžeš automatizovat získávání dat z webu, ušetřit hodiny ruční práce a rozhodovat se rychleji a líp.
Co si z toho odnést:
- Ruby je skvělý nástroj pro web scraping a automatizaci — zejména s gemy jako Nokogiri a HTTParty.
- AI Web Scraper nástroje jako Thunderbit zpřístupňují extrakci dat i lidem bez programování, díky funkcím jako „AI Suggest Fields“ a scraping podstránek.
- Kombinace Ruby a Thunderbitu přináší to nejlepší z obou světů: rychlá extrakce bez kódu plus vlastní automatizace a analýza.
- Automatizovaný sběr webových dat je silná strategie pro sales, marketing i e‑commerce týmy — méně ruční práce, vyšší přesnost a nové insighty.
Chceš začít hned? , zkus jednoduchý Ruby skript a uvidíš, kolik času ušetříš. A pokud chceš jít víc do hloubky, mrkni na — najdeš tam další návody, tipy i příklady z praxe.
Nejčastější dotazy (FAQ)
1. Musím umět programovat, abych mohl(a) používat Thunderbit pro web scraping?
Ne. Thunderbit je postavený pro netechnické uživatele. Stačí otevřít rozšíření, kliknout na „AI Suggest Fields“ a nechat AI udělat zbytek. Data pak vyexportuješ do Excelu, Google Sheets, Airtable nebo Notion — bez kódování.
2. Jaké jsou hlavní výhody Ruby pro web scraping?
Ruby nabízí silné knihovny jako Nokogiri a HTTParty pro flexibilní a plně přizpůsobitelné workflow. Hodí se pro vývojáře, kteří chtějí maximální kontrolu, vlastní logiku a integrace s dalšími systémy.
3. Jak funguje funkce „AI Suggest Fields“ v Thunderbitu?
AI v Thunderbitu projde webovou stránku, rozpozná nejrelevantnější datová pole (např. názvy produktů, ceny, e‑maily) a navrhne strukturovanou tabulku. Před scrapingem si můžeš sloupce upravit.
4. Můžu kombinovat Thunderbit s Ruby skripty pro pokročilé workflow?
Ano. Spousta týmů používá Thunderbit pro extrakci dat (hlavně ze složitých nebo dynamických webů) a pak data dál zpracuje nebo analyzuje v Ruby. Tenhle hybridní přístup je skvělý pro vlastní reporting nebo obohacování dat.
5. Je web scraping legální a bezpečný pro firemní použití?
Web scraping je legální, pokud sbíráš veřejně dostupná data a respektuješ podmínky webu a zákony o ochraně soukromí. Vždy zkontroluj robots.txt a neškrábej osobní data bez odpovídajícího souhlasu — zejména v EU pod GDPR.
Zajímá tě, jak může web scraping změnit tvoje workflow? Vyzkoušej bezplatný tarif Thunderbitu nebo si dnes otestuj Ruby skript. A když se zasekneš, a jsou plné návodů a tipů, jak zvládnout automatizaci webových dat — bez kódu.
Zjistěte více