Váš CRM systém je jen tak dobrý, jak kvalitní data do něj posíláte. A ta nejlepší data často leží na veřejných webech — ne v předražených databázích třetích stran.
webový extraktor dokáže tenhle chaotický webový obsah přetavit do přehledných tabulek. Ty povedené to zvládnou během pár minut a bez programování.
Tyhle nástroje jsem používal v reálných projektech — při stavbě lead listů, hlídání cen konkurence i stahování produktových katalogů. Tady je 12, které se mi v praxi osvědčily, seřazené podle toho, jak dobře obstály při skutečných firemních úkolech.
Proč jsou webové extraktory pro firmy nezbytné
Řekněme si to bez obalu: web je největší databáze na světě — a zároveň jedna z nejvíc „rozsypaných“. A v roce 2026 budou mít náskok firmy, které tenhle chaos umí proměnit v použitelné insighty. Podle jsou datově řízené firmy o 5 % produktivnější a o 6 % ziskovější než konkurence. To už není žádná kosmetika — to je tvrdá konkurenční výhoda.
Nástroje pro extrakce dat z webu (někdy se jim říká také web page extractors nebo řešení pro web extracting) jsou v tomhle směru taková tajná přísada. Obchodní týmy díky nim dokážou stahovat data z veřejných katalogů, sociálních sítí a firemních webů a skládat cílené seznamy potenciálních zákazníků — bez nákupu zastaralých lead listů a bez toho, aby se všechno sesypalo ve chvíli, kdy stážista uprostřed „copy‑paste maratonu“ skončí (). Marketingové a e‑commerce týmy používají webové extraktory ke sledování cen konkurence, monitoringu skladové dostupnosti a porovnávání produktů v reálném čase — například John Lewis připisuje web scrapingu nárůst prodejů o 4 % jen díky chytřejšímu nacenění ().
Nejde ale jen o čísla. Webové extraktory šetří obrovské množství času (jeden uživatel mluvil o úspoře „stovek hodin“ díky automatizaci sběru dat) a snižují chybovost, která vzniká ruční prací (). Provozní týmy dnes nastavují scrapery tak, aby průběžně sbíraly data, která by jinak stážisté dávali dohromady celé týdny — a uvolňují tak hodiny, které dřív mizely v únavném kopírování (). A díky AI extraktorům mohou i netechnicky zaměření lidé převádět weby do strukturovaných dat připravených k analýze ().
Pointa? Pokud v roce 2026 nepoužíváte webový extraktor, dost možná necháváte cenné poznatky (a peníze) ležet na stole.
Jak jsme vybrali top 12 webových extraktorů
Nabídka nástrojů pro web extracting je obrovská — jak se v tom neztratit a vybrat správně? Prošel jsem desítky možností, ale do finálního výběru se dostalo jen 12. Díval jsem se hlavně na:
- Snadnost použití: Dokáže s tím začít i netechnický uživatel bez psaní kódu? Upřednostnil jsem no‑code/low‑code nástroje s intuitivním ovládáním ().
- AI schopnosti: Moderní nástroje, které využívají AI ke zjednodušení scrapingu — automaticky rozpoznají pole, zvládnou navigaci po webu nebo umožní popsat požadavek běžnou češtinou/angličtinou ().
- Automatizace a plánování: Nejlepší webové extraktory jedou „na autopilota“. Vybral jsem ty, které umí plánovat opakované sběry nebo dlouhodobě monitorovat weby ().
- Export a integrace: Jde data snadno poslat do Excelu, Google Sheets, Airtable nebo Notion? Plusové body za integrace do workflow ().
- Škálovatelnost a spolehlivost: Ať už stahujete jednu stránku nebo tisíce, nástroj to musí ustát. Bral jsem v potaz i recenze uživatelů.
- Firemní využití: Upřednostnil jsem nástroje oblíbené u obchodních, marketingových, e‑commerce a provozních týmů — nejen u vývojářů.
Některé nástroje jsou nové a stojí na AI, jiné jsou prověřené klasiky. Všechny ale míří na stejný cíl: pomoct vám udělat z webu vlastní firemní databázi — bez zbytečných komplikací.
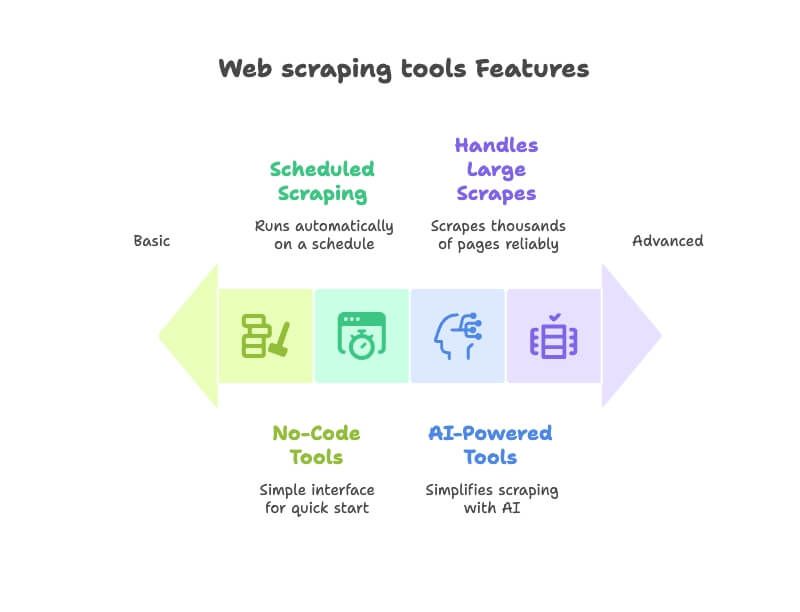
Rychlé srovnání: webové extraktory na první pohled
Tady je rychlý přehled 12 nástrojů, které v článku projdu, abyste hned viděli rozdíly:
| Nástroj | AI automatizace | Snadnost použití | Nejlepší využití |
|---|---|---|---|
| Thunderbit | Ano – AI navrhne pole a automaticky prochází stránky | Velmi snadné (Chrome rozšíření, bez kódu) | Rychlé získání leadů, cen apod. pro netechnické uživatele, kteří chtějí výsledek během minut. |
| Octoparse | Omezeně (šablony, bez AI) | Pro většinu snadné (vizuální drag‑and‑drop) | Vlastní scraping workflow (přihlášení, stránkování) pro analytiky, kteří chtějí kontrolu bez programování. |
| Browse AI | Částečně – „roboti“ na principu point‑and‑click | Snadné (no‑code, cloud) | Automatizované monitorování dat (ceny, nabídky apod.) podle plánu, s upozorněními a integracemi. |
| WebScraper.io | Ne (ruční konfigurace) | Střední (rozšíření + nastavení sitemap) | Vizuální scraping vícestupňových webů pro uživatele ochotné nastavit jednotlivé kroky. |
| ScraperAPI | N/A (API služba, proxy řeší přes API) | Vyžaduje kód (integrace přes API) | Vysoké objemy extrakce pro technické týmy — proxy a CAPTCHA řešené pro velké scraping projekty. |
| Data Miner | Ne | Velmi snadné (rozšíření s šablonami na jedno kliknutí) | Rychlá jednorázová extrakce z webů (hlavně tabulky/seznamy) přímo do CSV/Excelu. |
| Simplescraper | Ne (některé AI asistované funkce) | Snadné (tvorba „receptů“ point‑and‑click) | No‑code scraping s integracemi — ideální pro posílání dat do Google Sheets, Airtable nebo přes API. |
| Instant Data Scraper | Ano – automaticky rozpozná tabulky | Velmi snadné (klik a hotovo) | Okamžitý bezplatný scraping HTML tabulek a seznamů pro kohokoli (ideální pro rychlé získání dat). |
| ScrapeStorm | Ano – AI rozpozná prvky stránky | Snadné (vizuální rozhraní; multiplatformní aplikace) | Velké nebo složité scraping projekty bez kódu, včetně plánovaných crawlů. |
| Apify | Něco ano – dostupní předpřipravení „actor“ boti | Střední (webové rozhraní; kód volitelně) | Škálovatelný cloud scraping a automatizace přes hotové nebo vlastní skripty. |
| ParseHub | Ne (bez skriptů, ale ruční nastavení) | Snadné pro základ (vizuální editor; desktop) | Scraping dynamických/složitých webů (AJAX) přes no‑code rozhraní. |
| OutWit Hub | Ne | Snadné (desktop GUI) | Jednoduchá offline extrakce dat a archivace obsahu pro menší projekty. |
Většina nástrojů nabízí bezplatnou verzi nebo zkušební období a několik úrovní předplatného. Tady se soustředím hlavně na schopnosti a typické scénáře použití, ne na cenu.
Thunderbit: AI webový extraktor pro každého

Začnu Thunderbit — jo, je to „moje dítě“, ale dej mi minutku. Celé odvětví web extractingu se posouvá od „nastav si scraper sám“ k „řekni AI, co chceš“. Thunderbit je první nástroj, který jsem viděl (a pomáhal stavět) a který opravdu působí jako AI datový asistent, ne jen další „crawler“.
S nemusíš řešit XPath, CSS selektory ani regulární výrazy. Prostě popíšeš, co chceš vytáhnout — třeba „vezmi název, autora a datum z téhle stránky“ — a AI to zařídí (). Klikneš na „AI Suggest Fields“ a Thunderbit stránku přečte, navrhne sloupce a automaticky si poradí i s podstránkami a stránkováním ().
Nejde ale jen o samotné stažení dat. Thunderbit umí data během scrapingu čistit, transformovat, kategorizovat a dokonce i překládat. Potřebuješ sjednotit formát telefonních čísel, shrnout popisy nebo přeložit názvy produktů? Stačí krátká instrukce a AI to udělá. A hotová data pak vyexportuješ rovnou do Excelu, Google Sheets, Airtable nebo Notion ().
Co Thunderbit odlišuje nejvíc, je nulové nastavování a téměř žádná křivka učení. Je to Chrome rozšíření, takže jsi připravený během pár vteřin. Žádné pluginy, žádná konfigurace, žádný technický slovník. I proto si ho oblíbily obchodní, marketingové a provozní týmy, které potřebují výsledek rychle (). Bezplatná verze ti umožní vyzkoušet celý postup a placené tarify jsou pro většinu týmů dostupné.
Pokud chceš zažít, jak vypadá AI web extracting v praxi, stáhni si a vyzkoušej ho. Možná tím skončí tvoje éra copy‑paste.
Octoparse: vizuální webový extraktor pro vlastní workflow
Octoparse je klasika mezi vizuálními nástroji pro web scraping. Je to desktopová aplikace s point‑and‑click rozhraním — na stránce si klikáním vybereš, co chceš, a Octoparse na pozadí poskládá workflow (). Bez kódu zvládneš přihlášení, stránkování i automatické odesílání formulářů.
Silná stránka Octoparse je knihovna 500+ hotových šablon pro populární weby (Amazon, Twitter, LinkedIn atd.), takže často stačí šablonu načíst a rovnou extrahovat (). U složitějších webů přepneš do manuálního režimu a vizuálně nastavíš jednotlivé kroky. Octoparse umí pracovat i s obsahem, který se načítá až po kliknutí nebo scrollování, podporuje proxy a řešení CAPTCHA. Nechybí ani cloudová varianta pro plánování a běh ve větším měřítku.
Nevýhoda? U pokročilejších scénářů počítej s určitou křivkou učení. Pro neprogramátory a datové analytiky, kteří chtějí vlastní scraping workflow bez kódu, je ale Octoparse hodně solidní volba ().
Browse AI: automatizovaný web extracting s předpřipravenými roboty
Browse AI na to jde hravě: „natrénuješ robota“ tím, že klikneš na data, která chceš, a nástroj se naučí extrahovat je i z podobných stránek (). Všechno běží v cloudu a bez kódu, takže neřešíš skripty ani servery.
Browse AI vyniká hlavně v automatizaci a monitoringu. Roboty můžeš plánovat na pravidelné běhy a dostávat upozornění při změnách (např. když konkurence zlevní nebo se objeví nová pracovní nabídka). K dispozici je i knihovna hotových robotů pro běžné úkoly, takže často začneš s předpřipraveným řešením a jen ho doladíš ().
Browse AI se přes Zapier a Make propojí s tisíci aplikacemi a data umí posílat přímo do Google Sheets nebo přes API/webhooky (). Skvěle se hodí pro průběžné sledování a opakovaný sběr dat, pokud chceš upozornění a integrace bez práce navíc.
WebScraper.io: webový extraktor v prohlížeči

WebScraper.io (často jen „Web Scraper“) je rozšíření do prohlížeče, ve kterém si vytváříš „sitemapy“ — vizuální plán, jak se má web procházet a co se má extrahovat (). Nastavíš selektory pro data a odkazy, které se mají následovat (např. „klikni na další stránku“ nebo „otevři detail produktu“).
Je tu určitá křivka učení, ale kód psát nemusíš — jen vybíráš prvky a definuješ akce. Web Scraper podporuje víceúrovňovou navigaci, stránkování i nekonečné scrollování (kroky ale musíš nastavit ručně). Běží v prohlížeči, takže zvládne i weby za přihlášením, pokud se přihlásíš ty.
WebScraper.io je ideální pro „občanské datové analytiky“, kteří se vyznají ve struktuře webů a chtějí flexibilní (často i bezplatný) nástroj. Když si sitemapy jednou nastavíš, je to spolehlivý dříč.
ScraperAPI: API‑first webový extraktor pro vývojáře a týmy
Ne každý tým chce point‑and‑click rozhraní — někdy potřebuješ backendové řešení, které posílá webová data rovnou do aplikací nebo databází. ScraperAPI je API‑first webový extraktor: pošleš URL a dostaneš zpět HTML nebo extrahovaná data, přičemž služba za tebe řeší proxy, geo IP rotaci, headless prohlížeče i CAPTCHA ().
ScraperAPI provozuje síť přes 40 milionů proxy ve více než 50 zemích a zpracuje 36 miliard požadavků měsíčně (). Hodí se pro velkoobjemový automatizovaný scraping, kde je klíčová spolehlivost a odolnost proti blokování. Budeš potřebovat programátorské znalosti, ale pro datové pipeline nebo integraci scrapingu do produktu je to špičková volba.
Data Miner: Chrome rozšíření pro rychlou extrakci z webu

Data Miner je Chrome rozšíření pro business uživatele a výzkumníky, kteří potřebují data získat rychle. Nabízí point‑and‑click scraping a knihovnu hotových „receptů“ pro běžné vzory jako tabulky, seznamy nebo konkrétní weby ().
Stačí rozšíření nainstalovat, otevřít cílovou stránku a kliknout na ikonu Data Miner. Vybereš recept, nebo si vytvoříš vlastní označením prvků na stránce. Skvělé pro jednorázové úkoly a rychlé potřeby — třeba když obchodník tahá leady z katalogu, nebo e‑commerce manažer kopíruje ceny konkurence.
Data Miner je jednoduchý, přímo v prohlížeči a ideální pro interaktivní scraping na vyžádání.
Simplescraper: no‑code webový extraktor pro okamžité výsledky

Simplescraper dělá čest svému názvu. Je to no‑code Chrome rozšíření (a webová aplikace), kde si vizuálně vybereš data na stránce a vytvoříš „recept“ pro extrakci (). Umí následovat odkazy na podstránky, řešit stránkování a jedním kliknutím z tvého scrapingu udělat API endpoint.
Nejvíc boduje v integracích — data můžeš posílat rovnou do Google Sheets, Airtable nebo do nástrojů jako Zapier (). Nechybí cloud scraping, plánování opakovaných běhů a funkce „AI Enhance“ pro čištění či analýzu dat pomocí GPT.
Pokud chceš rychlý výsledek a snadné napojení na další nástroje, Simplescraper je takový švýcarský nůž mezi lehkými scrapery.
Instant Data Scraper: rychlá extrakce tabulek a seznamů
Někdy potřebuješ data hned a bez nastavování. Přesně na to je Instant Data Scraper (IDS). Jde o bezplatné Chrome rozšíření známé tím, že umí na jedno kliknutí vytáhnout tabulková data (). Zapneš rozšíření a IDS automaticky rozpozná tabulky nebo seznamy. Zvládne i stránkování a nekonečný scroll tím, že stránky automaticky prokliká.
IDS je 100% zdarma, bez registrace, bez kódu, bez čekání. Ideální pro rychlé nebo urgentní potřeby — třeba když obchodník potřebuje okamžitě seznam kontaktů, nebo student tahá data z tabulek na Wikipedii. Pokud IDS tvoje data najde, máš je během pár vteřin.
ScrapeStorm: cloudový webový extraktor s AI asistencí
ScrapeStorm je AI nástroj pro web scraping, který kombinuje vizuální rozhraní s výkonnými algoritmy (). Zadáš URL a AI automaticky rozpozná datová pole — seznamy, tabulky, tlačítka „další stránka“ a další.
ScrapeStorm funguje napříč platformami (Windows, Mac, Linux) a nabízí desktop i cloud. Umí plánovat úlohy, spouštět více jobů paralelně a exportovat do Excelu, CSV, JSON nebo nahrávat do databáze (). Je oblíbený hlavně v e‑commerce a market research a díky AI zvládne parsovat data i z obrázků nebo PDF.
Pokud potřebuješ chytrého pomocníka pro velké nebo složité scraping projekty, ScrapeStorm stojí za vyzkoušení.
Apify: marketplace webových extraktorů a automatizační platforma

Apify není jen scraper — je to platforma pro web scraping a automatizaci. Spouštíš v ní „actors“, tedy skripty pro scraping nebo automatizaci prohlížeče. Největší výhoda je marketplace hotových actorů pro běžné úkoly (). Potřebuješ stáhnout všechny recenze z e‑shopu? Je dost možné, že na to už actor existuje.
Vývojáři si mohou psát vlastní scrapery v Node.js nebo Pythonu a nasadit je v cloudu. Apify je škálovatelné, automatizovatelné a napojitelné přes API. Hodí se pro power uživatele a organizace, které berou webová data jako strategický zdroj — tedy pro dlouhodobý scraping ve velkém nebo integraci do datových pipeline.
ParseHub: vizuální webový extraktor pro složité weby

ParseHub je desktopová aplikace (s cloudovými možnostmi), která je známá tím, že zvládá složité a dynamické weby. Webem procházíš v rozhraní podobném prohlížeči, klikáš na datové body a ParseHub z toho poskládá scraper (). Podporuje podmínky, vnořené extrakce, AJAX obsah a další.
ParseHub často přichází na řadu ve chvíli, kdy jiné nástroje selžou. Používají ho výzkumníci, analytici i menší firmy, které potřebují zvládnout „záludné“ weby. Je tu křivka učení, ale pokud máš komplexní web a nechceš programovat, ParseHub je výborná volba.
OutWit Hub: desktopový webový extraktor pro archivaci obsahu

OutWit Hub je trochu old‑school, ale jako desktopová aplikace je skvělý pro stahování různých typů obsahu (odkazy, obrázky, e‑maily atd.) a jejich organizaci (). Funguje jako kombinace prohlížeče a tabulky — otevřeš stránku a OutWit Hub umí vytáhnout tabulky, seznamy, obrázky a další.
Hodí se hlavně pro archivaci obsahu a research — třeba stáhnout všechny příspěvky z fóra nebo hromadně stáhnout soubory. Je to desktopový nástroj, takže běží lokálně a data zůstávají u tebe. Nejlépe sedí na malé až střední úlohy, kde chceš jednoduché desktopové ovládání.
Který webový extraktor je nejlepší právě pro vás?
Dvanáct nástrojů, tisíc scénářů. Jak vybrat? Tady je moje rychlá nápověda:
-
Pro úplné začátečníky nebo jednorázové rychlé úkoly:
Zkus Instant Data Scraper na základní tabulky a seznamy (je zdarma a okamžitý). Data Miner je další přívětivá volba s více šablonami, pokud často extrahuješ podobné stránky.
-
Pro netechnické uživatele, kteří potřebují pravidelný scraping nebo integrace:
Thunderbit nabízí nejjednodušší workflow díky AI přístupu — ideální pro business uživatele, kteří chtějí rychlé a opakované výsledky. Browse AI je skvělé pro průběžné sledování a upozornění. Simplescraper se hodí, pokud chceš, aby data tekla do Google Sheets nebo interní aplikace přes API.
-
Pro složité weby nebo vlastní workflow bez programování:
Sáhni po vizuálních nástrojích jako Octoparse nebo ParseHub. Octoparse je přívětivý a má spoustu šablon. ParseHub zvládá velmi komplexní dynamické weby a dává jemnou kontrolu. WebScraper.io je taky skvělý, pokud si chceš sitemapy nastavit sám.
-
Pro vývojáře a data inženýry, kteří potřebují škálovat:
ScraperAPI je dělané pro integraci web scrapingu do softwaru nebo velké projekty. Apify je ideální, když chceš škálovatelnou platformu s marketplace hotových i vlastních skriptů.
-
Pro extrakci obsahu a offline použití:
OutWit Hub je dobrá volba pro systematický sběr a archivaci obsahu, zvlášť pokud preferuješ desktopový nástroj kvůli soukromí nebo kontrole.
Upřímně: spousta týmů používá víc nástrojů podle typu úkolu. Můžeš začít s Instant Data Scraper na něco jednoduchého, přejít na Thunderbit nebo Octoparse u většího projektu a ScraperAPI či Apify vytáhnout ve chvíli, kdy potřebuješ proces „zindustrializovat“. Dobrá zpráva je, že většina nástrojů má free tier nebo trial, takže si je můžeš v klidu osahat.
Závěr: budoucnost web extractingu pro firemní týmy
Nástroje pro web extracting urazily obrovský kus cesty. V roce 2026 jsou už naprosto mainstream. Hlavní trend? Web scraping je jednodušší, automatizovanější a víc zapadá do každodenních workflow (). AI scrapery znamenají, že i složité dynamické weby zvládneš bez specializovaných dovedností. Jak to popsal jeden data engineer: „Jakmile se na trhu objevily AI nástroje pro web scraping, zvládal jsem úkoly mnohem rychleji a ve větším měřítku… s AI je [čištění dat] automaticky součástí workflow.“
Další velká změna je stírání hranic mezi scrapingem, monitoringem a automatizací. Nástroje jako Browse AI a Thunderbit nejen data vytáhnou, ale udržují je aktuální a někdy umí i provádět akce (např. vyplňovat formuláře nebo spouštět upozornění). Růst adopce je znatelný — jedna velká platforma zaznamenala nárůst měsíčně aktivních uživatelů o více než 140 % během roku (). Firmy všech velikostí si uvědomují, že přístup k veřejným webovým datům (eticky a legálně) je klíčový pro konkurenceschopnost.
Pro firemní týmy z toho plyne hlavně větší samostatnost. Nemusíš čekat týdny na vývojáře ani se rozhodovat podle pocitu. Nástroje v tomto seznamu dávají webová data do rukou obchodním, marketingovým i provozním týmům — s rozhraním a funkcemi navrženými pro reálné scénáře. A podle toho, jak se trh vyvíjí, čekám brzy ještě přívětivější rozhraní, chytřejší AI a hlubší integrace s BI a analytickými platformami.
Jen nezapomeň: respektuj podmínky použití webů a pravidla robots.txt a hlídej soulad se zákony o ochraně osobních údajů. Etický scraping je důležitý pro dlouhodobou udržitelnost.
Ať už začneš s bezplatným rozšířením, nebo nasadíš enterprise „scraping flotilu“, nikdy nebyla lepší doba proměnit informace z webu v konkrétní rozhodnutí. Revoluce webových extraktorů je tady — vyber si nástroj, vyzkoušej ho a odemkni hodnotu, která je často schovaná na očích. Tvoje datově řízená budoucnost je vzdálená jedno kliknutí.
Nejčastější dotazy (FAQ)
1. Co je webový extraktor a proč je pro firmy důležitý?
Webový extraktor je nástroj, který automaticky získává strukturovaná data z webových stránek. Pro firmy je zásadní, protože dokáže převést chaotické online informace na použitelné poznatky — zvyšuje produktivitu, podporuje ziskovost a eliminuje ruční sběr dat.
2. Kdo může webové extraktory používat — potřebuji technické znalosti?
U mnoha moderních webových extraktorů technické znalosti nepotřebuješ. Nástroje jako Thunderbit, Browse AI nebo Instant Data Scraper jsou navržené pro netechnické uživatele: mají intuitivní rozhraní, AI automatizaci a no‑code workflow.
3. Jak mohou obchodní, marketingové a provozní týmy z webových extraktorů těžit?
Obchodní týmy si mohou vytvářet lead listy z online katalogů, marketing může sledovat ceny konkurence a provoz automatizovat sběr dat. Tyto nástroje šetří čas, snižují chybovost a přinášejí čerstvé a spolehlivé podklady pro strategická rozhodnutí.
4. Na co se zaměřit při výběru webového extraktoru?
Důležité jsou: snadnost použití, AI funkce, automatizace/plánování, integrace s nástroji jako Google Sheets nebo Airtable, škálovatelnost a hlavně vhodnost pro váš scénář (např. leady, monitoring cen, archivace obsahu).
5. Existují bezplatné nebo levné webové extraktory?
Ano. Mnoho nástrojů nabízí bezplatné tarify nebo dostupné plány. Instant Data Scraper je pro základní potřeby úplně zdarma, zatímco Thunderbit, Simplescraper a Data Miner mají štědré free plány s možností upgradu.
Chceš se dozvědět víc o web extractingu, AI scrapingu nebo o tom, jak proměnit weby ve vaši další konkurenční výhodu? Podívej se na — najdeš tam další návody, tipy i příběhy z praxe automatizace dat.