
Jaký programovací jazyk zvolit pro web scraping? Záleží na tom, co přesně stavíš — a už jsem viděl vývojáře, kteří to úplně zabalili jen proto, že na začátku sáhli vedle.
Trh se softwarem pro web scraping měl v roce 2024 hodnotu . Správně zvolený jazyk znamená rychlejší výsledky a míň údržby. Špatná volba naopak končí rozbitými scrapery a víkendy utopenými v ladění.
Automatizační nástroje stavím už roky. Níže najdeš sedm jazyků, které jsem pro scraping reálně používal — včetně ukázek kódu, férových kompromisů a taky situací, kdy je lepší programování úplně přeskočit a místo toho sáhnout po .
Jak jsme vybírali nejlepší jazyk pro web scraping
U web scrapingu si nejsou všechny jazyky rovné. Viděl jsem projekty, které díky správné volbě vystřelily nahoru — i takové, které na ní tvrdě narazily. Nejvíc obvykle rozhodují tyhle věci:
- Snadnost použití: Jak rychle se dostaneš do tempa? Je syntaxe přívětivá, nebo potřebuješ půlku semestru jen na „Hello, World“?
- Podpora knihoven: Jsou po ruce kvalitní knihovny na HTTP požadavky, parsování HTML a práci s dynamickým obsahem? Nebo budeš znovu vynalézat kolo?
- Výkon: Utáhne to scraping milionů stránek, nebo se to začne dusit po pár stovkách?
- Práce s dynamickým obsahem: Moderní weby jedou na JavaScriptu. Umí s tím tvůj jazyk držet krok?
- Komunita a podpora: Až narazíš (a narazíš), bude kde hledat pomoc?
Podle těchto kritérií — a po spoustě nočního testování — se podíváme na těchto sedm jazyků:
- Python: univerzální volba pro začátečníky i profíky.
- JavaScript & Node.js: král dynamického obsahu.
- Ruby: čistá syntaxe, rychlé skripty.
- PHP: jednoduchost na serveru.
- C++: když potřebuješ surovou rychlost.
- Java: připravené pro enterprise a škálování.
- Go (Golang): rychlé a paralelní.
A jestli si říkáš „Shuai, já nechci psát žádný kód“, vydrž — na konci čeká Thunderbit.
Web scraping v Pythonu: přívětivý tahoun pro začátečníky
Začněme favoritem davu: Pythonem. Když se zeptáš místnosti plné datových lidí „Jaký je nejlepší jazyk pro web scraping?“, Python se ozve skoro jako sbor na koncertě Taylor Swift.
Proč právě Python?
- Syntaxe pro lidi: Pythonový kód si často můžeš přečíst nahlas a zní skoro jako angličtina.
- Bezkonkurenční ekosystém knihoven: Od na parsování HTML, přes pro velké crawlery, pro HTTP až po pro automatizaci prohlížeče — Python má prakticky všechno.
- Obrovská komunita: Jen na Stack Overflow je přes k web scrapingu v Pythonu.
Ukázka v Pythonu: získání titulku stránky
1import requests
2from bs4 import BeautifulSoup
3response = requests.get("<https://example.com>")
4soup = BeautifulSoup(response.text, 'html.parser')
5title = soup.title.string
6print(f"Page title: {title}")Silné stránky:
- Rychlý vývoj a prototypování.
- Hromada návodů a odpovědí.
- Skvělé pro práci s daty — scraping v Pythonu, analýza v pandas, vizualizace v matplotlib.
Slabiny:
- U obřích úloh je pomalejší než kompilované jazyky.
- U extrémně dynamických webů může být práce trochu neohrabaná (i když Selenium a Playwright hodně pomáhají).
- Není ideální, pokud chceš škrábat miliony stránek „na plný plyn“.
Verdikt:
Pokud se scrapingem začínáš nebo potřebuješ rychle doručit výsledek, Python je nejlepší jazyk pro web scraping — tečka. .
JavaScript & Node.js: snadné scrapování dynamických webů
Jestli je Python švýcarský nůž, JavaScript (a Node.js) je výkonná vrtačka — hlavně když potřebuješ scrapovat moderní weby postavené na JavaScriptu.
Proč JavaScript/Node.js?
- Přirozená volba pro dynamický obsah: Běží v prohlížeči, takže „vidí“ to, co uživatel — i když je stránka postavená na Reactu, Angularu nebo Vue.
- Asynchronně od základu: Node.js zvládne obsloužit stovky požadavků současně.
- Známé prostředí pro web vývojáře: Pokud jsi někdy dělal web, JavaScript už máš aspoň trochu v ruce.
Klíčové knihovny:
- : automatizace Headless Chrome.
- : automatizace napříč prohlížeči.
- : parsování HTML v Node ve stylu jQuery.
Ukázka v Node.js: získání titulku stránky přes Puppeteer
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('<https://example.com>', { waitUntil: 'networkidle2' });
6 const title = await page.title();
7 console.log(`Page title: ${title}`);
8 await browser.close();
9})();Silné stránky:
- Nativně zvládá obsah renderovaný JavaScriptem.
- Skvělé pro infinite scroll, pop-upy a interaktivní weby.
- Efektivní pro velké objemy a paralelní scraping.
Slabiny:
- Asynchronní programování umí být pro začátečníky zrádné.
- Headless prohlížeče jsou žravé na paměť, když jich spustíš víc.
- Méně nástrojů pro analýzu dat než Python.
Kdy je JavaScript/Node.js nejlepší volba pro web scraping?
Když je cílový web dynamický nebo potřebuješ automatizovat akce v prohlížeči. .
Ruby: čistá syntaxe pro rychlé scraping skripty
Ruby není jen Rails a elegantní „poezie“ v kódu. Na web scraping je to pořád solidní volba — hlavně pokud si potrpíš na čitelnost a rychlé iterace.
Proč Ruby?
- Čitelná, expresivní syntaxe: Scraper v Ruby se často čte skoro jako nákupní seznam.
- Skvělé na prototypy: Rychle napíšeš, snadno upravíš.
- Klíčové knihovny: na parsování, na automatizaci navigace.
Ukázka v Ruby: získání titulku stránky
1require 'open-uri'
2require 'nokogiri'
3html = URI.open("<https://example.com>")
4doc = Nokogiri::HTML(html)
5title = doc.at('title').text
6puts "Page title: #{title}"Silné stránky:
- Extrémně čitelné a stručné.
- Výborné pro menší projekty, jednorázové skripty nebo pokud Ruby už používáš.
Slabiny:
- U velkých úloh bývá pomalejší než Python nebo Node.js.
- Méně scraping knihoven a menší komunita zaměřená přímo na scraping.
- Na weby těžké na JavaScript se moc nehodí (i když jde použít Watir nebo Selenium).
Pro koho se hodí:
Pokud jsi Rubyista nebo potřebuješ rychle „spíchnout“ skript, Ruby je radost. Pro masivní dynamický scraping se radši koukni jinam.
PHP: jednoduchá serverová cesta k extrakci dat z webu
PHP může působit jako relikt raného webu, ale pořád má svoje místo — zvlášť když chceš scrapovat data přímo na serveru.
Proč PHP?
- Běží skoro všude: Většina webhostingů má PHP už připravené.
- Snadná integrace do webových aplikací: Data můžeš rovnou scrapovat a hned je zobrazit na webu.
- Klíčové knihovny: pro HTTP, pro požadavky, pro headless automatizaci.
Ukázka v PHP: získání titulku stránky
1<?php
2$ch = curl_init("<https://example.com>");
3curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
4$html = curl_exec($ch);
5curl_close($ch);
6$dom = new DOMDocument();
7@$dom->loadHTML($html);
8$title = $dom->getElementsByTagName("title")->item(0)->nodeValue;
9echo "Page title: $title\n";
10?>Silné stránky:
- Snadné nasazení na web server.
- Hodí se, když je scraping součástí webového workflow.
- Rychlé pro jednoduché serverové úlohy.
Slabiny:
- Omezenější podpora knihoven pro pokročilý scraping.
- Není stavěné na vysokou paralelizaci a scraping ve velkém.
- JavaScript-heavy weby jsou složitější (i když Panther pomůže).
Pro koho se hodí:
Pokud už máš stack v PHP nebo chceš data scrapovat a rovnou je zobrazovat na webu, PHP je praktická volba. .
C++: vysoce výkonný web scraping pro velké projekty
C++ je mezi jazyky takové „muscle car“. Když potřebuješ maximální rychlost a kontrolu a nevadí ti víc ruční práce, C++ tě dostane hodně daleko.
Proč C++?
- Bleskový výkon: U CPU náročných úloh překoná většinu jazyků.
- Detailní kontrola: Paměť, vlákna i optimalizace máš ve vlastních rukou.
- Klíčové knihovny: pro HTTP, pro parsování.
Ukázka v C++: získání titulku stránky
1#include <curl/curl.h>
2#include <iostream>
3#include <string>
4size_t WriteCallback(void* contents, size_t size, size_t nmemb, void* userp) {
5 std::string* html = static_cast<std::string*>(userp);
6 size_t totalSize = size * nmemb;
7 html->append(static_cast<char*>(contents), totalSize);
8 return totalSize;
9}
10int main() {
11 CURL* curl = curl_easy_init();
12 std::string html;
13 if(curl) {
14 curl_easy_setopt(curl, CURLOPT_URL, "<https://example.com>");
15 curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
16 curl_easy_setopt(curl, CURLOPT_WRITEDATA, &html);
17 CURLcode res = curl_easy_perform(curl);
18 curl_easy_cleanup(curl);
19 }
20 std::size_t startPos = html.find("<title>");
21 std::size_t endPos = html.find("</title>");
22 if(startPos != std::string::npos && endPos != std::string::npos) {
23 startPos += 7;
24 std::string title = html.substr(startPos, endPos - startPos);
25 std::cout << "Page title: " << title << std::endl;
26 } else {
27 std::cout << "Title tag not found" << std::endl;
28 }
29 return 0;
30}Silné stránky:
- Bezkonkurenční rychlost pro masivní scraping.
- Skvělé pro integraci do vysoce výkonných systémů.
Slabiny:
- Strmá křivka učení (kafe doporučeno).
- Ruční správa paměti.
- Méně „high-level“ knihoven; na dynamický obsah se moc nehodí.
Pro koho se hodí:
Když potřebuješ scrapovat miliony stránek nebo je výkon naprosto kritický. Jinak můžeš strávit víc času debugováním než scrapováním.
Java: enterprise řešení pro web scraping
Java je tahoun enterprise světa. Pokud stavíš něco, co má běžet dlouhodobě, zvládat hodně dat a přežít i zombie apokalypsu, Java je spolehlivý parťák.
Proč Java?
- Robustní a škálovatelná: Skvělá pro velké, dlouho běžící scraping projekty.
- Silné typování a práce s chybami: V produkci míň nepříjemných překvapení.
- Klíčové knihovny: pro parsování, pro automatizaci prohlížeče, pro HTTP.
Ukázka v Javě: získání titulku stránky
1import org.jsoup.Jsoup;
2import org.jsoup.nodes.Document;
3public class ScrapeTitle {
4 public static void main(String[] args) throws Exception {
5 Document doc = Jsoup.connect("<https://example.com>").get();
6 String title = doc.title();
7 System.out.println("Page title: " + title);
8 }
9}Silné stránky:
- Vysoký výkon a dobrá paralelizace.
- Výborné pro velké, udržovatelné codebase.
- Solidní podpora dynamického obsahu (přes Selenium nebo HtmlUnit).
Slabiny:
- Ukecanější syntaxe; víc „setupu“ než u skriptovacích jazyků.
- Pro malé jednorázové skripty je to často zbytečně těžké.
Pro koho se hodí:
Enterprise scraping ve velkém nebo projekty, kde je klíčová spolehlivost a škálování.
Go (Golang): rychlý a paralelní web scraping
Go je relativně mladý jazyk, ale už teď je hodně vidět — hlavně u rychlého scrapingu s vysokou mírou paralelismu.
Proč Go?
- Rychlost kompilovaného jazyka: Často skoro na úrovni C++.
- Paralelismus v základu: Goroutines dělají z paralelního scrapingu překvapivě jednoduchou věc.
- Klíčové knihovny: pro scraping, pro parsování.
Ukázka v Go: získání titulku stránky
1package main
2import (
3 "fmt"
4 "github.com/gocolly/colly"
5)
6func main() {
7 c := colly.NewCollector()
8 c.OnHTML("title", func(e *colly.HTMLElement) {
9 fmt.Println("Page title:", e.Text)
10 })
11 err := c.Visit("<https://example.com>")
12 if err != nil {
13 fmt.Println("Error:", err)
14 }
15}Silné stránky:
- Extrémně rychlé a úsporné pro scraping ve velkém.
- Snadné nasazení (jeden binární soubor).
- Skvělé pro paralelní crawling.
Slabiny:
- Menší komunita než u Pythonu nebo Node.js.
- Méně „high-level“ scraping knihoven.
- Pro JavaScript-heavy weby je potřeba další výbava (Chromedp nebo Selenium).
Pro koho se hodí:
Když potřebuješ škálovat scraping nebo je Python už pomalý. .
Srovnání nejlepších programovacích jazyků pro web scraping
A teď si to pojďme hodit do přehledné tabulky. Tohle srovnání ti pomůže vybrat nejlepší jazyk pro web scraping v roce 2026:
| Jazyk/Nástroj | Snadnost použití | Výkon | Podpora knihoven | Práce s dynamickým obsahem | Nejlepší použití |
|---|---|---|---|---|---|
| Python | Velmi vysoká | Střední | Vynikající | Dobrá (Selenium/Playwright) | Univerzální, začátečníci, analýza dat |
| JavaScript/Node.js | Střední | Vysoký | Silná | Vynikající (nativně) | Dynamické weby, async scraping, web vývojáři |
| Ruby | Vysoká | Střední | Slušná | Omezená (Watir) | Rychlé skripty, prototypování |
| PHP | Střední | Střední | Průměrná | Omezená (Panther) | Server-side, integrace do web aplikací |
| C++ | Nízká | Velmi vysoký | Omezená | Velmi omezená | Kritický výkon, obří škála |
| Java | Střední | Vysoký | Dobrá | Dobrá (Selenium/HtmlUnit) | Enterprise, dlouho běžící služby |
| Go (Golang) | Střední | Velmi vysoký | Rostoucí | Střední (Chromedp) | Rychlý, paralelní scraping |
Kdy nepsat kód: Thunderbit jako no-code řešení pro web scraping
Buďme realisti: někdy chceš prostě jen data — bez programování, debugování a klasických bolestí typu „proč ten selector zase přestal fungovat“. Přesně na to je tu .
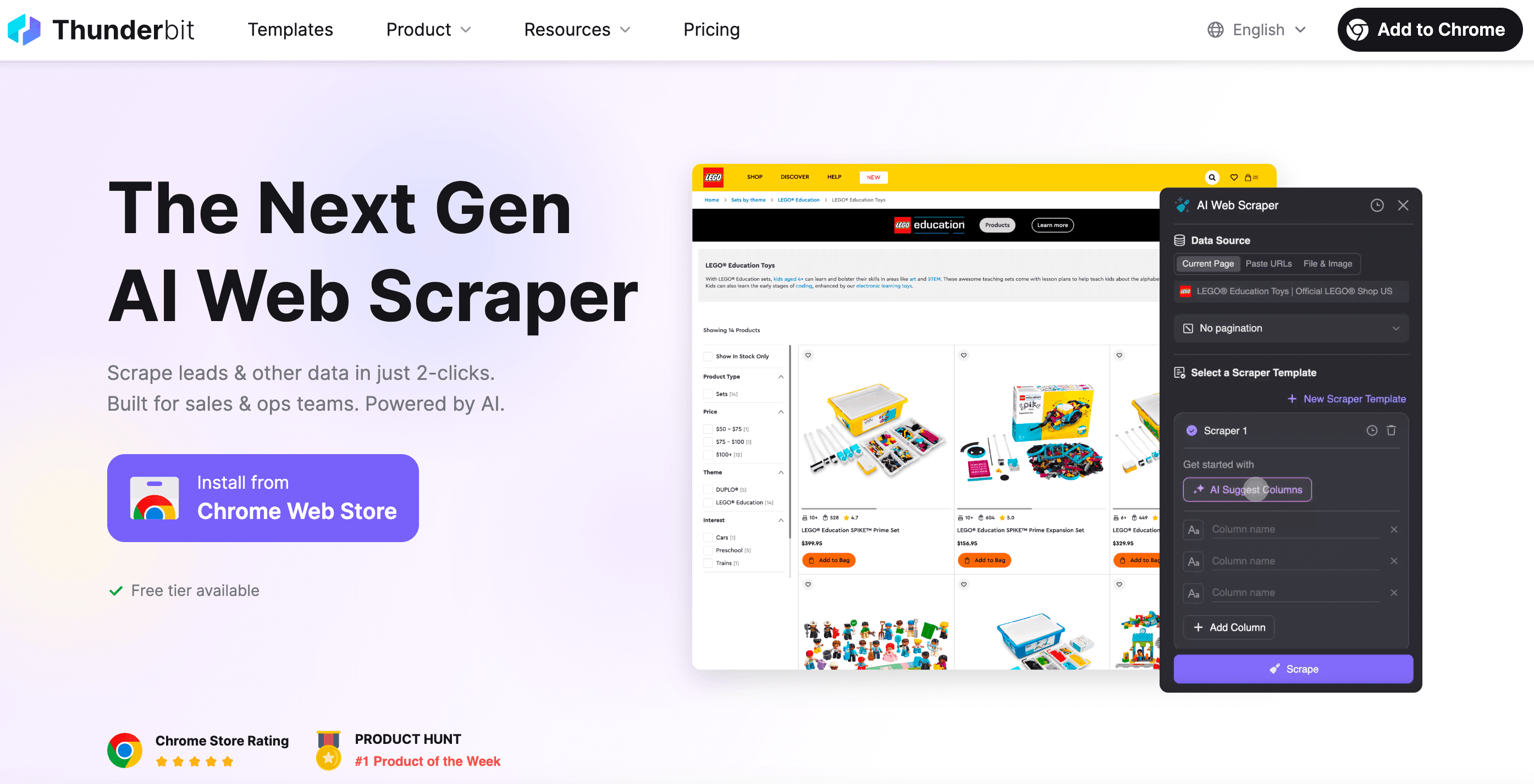
Jako spoluzakladatel Thunderbitu jsem chtěl postavit nástroj, který udělá web scraping stejně jednoduchý jako objednat si jídlo. Tohle je to, čím se Thunderbit liší:
- Nastavení na 2 kliknutí: Stačí kliknout na „AI Suggest Fields“ a „Scrape“. Žádné hraní si s HTTP požadavky, proxy nebo anti-bot triky.
- Chytré šablony: Jedna scraper šablona se umí přizpůsobit různým rozvržením stránek. Nemusíš přepisovat scraper pokaždé, když se web změní.
- Scraping v prohlížeči i v cloudu: Vybereš si scraping v prohlížeči (ideální pro weby po přihlášení) nebo v cloudu (super rychlé pro veřejná data).
- Zvládá dynamický obsah: AI v Thunderbitu ovládá skutečný prohlížeč — takže si poradí s infinite scroll, pop-upy, přihlášením a dalšími.
- Export kamkoli: Stáhneš do Excelu, Google Sheets, Airtable, Notion nebo to jen zkopíruješ do schránky.
- Bez údržby: Když se web změní, stačí znovu spustit AI návrh polí. Žádné noční ladění.
- Plánování a automatizace: Nastavíš scrapery tak, aby běžely podle plánu — bez cronů a bez serverové infrastruktury.
- Specializované extraktory: Potřebuješ e-maily, telefonní čísla nebo obrázky? Thunderbit má i extraktory na jedno kliknutí.
A to nejlepší? Nemusíš znát ani řádek kódu. Thunderbit je dělaný pro business uživatele, marketéry, obchodní týmy, realitní profíky — zkrátka pro každého, kdo potřebuje rychle získat strukturovaná data.
Chceš vidět Thunderbit v praxi? nebo mrkni na náš , kde najdeš ukázky.
Závěr: jak vybrat nejlepší jazyk pro web scraping v roce 2026
Web scraping je v roce 2026 dostupnější — a zároveň silnější — než kdy dřív. Po letech v automatizačních „zákopách“ mi vychází tohle:
- Python je pořád nejlepší jazyk pro web scraping, pokud chceš rychlý start a maximum zdrojů.
- JavaScript/Node.js nemá konkurenci pro dynamické weby postavené na JavaScriptu.
- Ruby a PHP jsou super pro rychlé skripty a integraci do webů, hlavně pokud je už používáš.
- C++ a Go dávají smysl, když potřebuješ rychlost a škálování.
- Java je sázka na jistotu pro enterprise a dlouhodobé projekty.
- A pokud chceš programování úplně vynechat? je tvoje tajná zbraň.
Než se do toho pustíš, zeptej se sám sebe:
- Jak velký je můj projekt?
- Potřebuju řešit dynamický obsah?
- Jak moc jsem technicky „v pohodě“?
- Chci to stavět, nebo jen získat data?
Vyzkoušej některou ukázku kódu výše — nebo si na příští projekt zkus Thunderbit. A pokud chceš jít víc do hloubky, mrkni na pro další návody, tipy a příběhy z praxe.
Přeju úspěšný scraping — a ať jsou tvoje data vždycky čistá, strukturovaná a ideálně na jedno kliknutí.
P.S. Pokud se někdy ve 2 ráno zasekneš v scrapingové králičí noře, pamatuj: vždycky existuje Thunderbit. Nebo káva. Nebo obojí.
Nejčastější dotazy (FAQ)
1. Jaký je nejlepší programovací jazyk pro web scraping v roce 2026?
Python zůstává nejčastější volbou díky čitelné syntaxi, silným knihovnám (např. BeautifulSoup, Scrapy a Selenium) a velké komunitě. Hodí se pro začátečníky i pokročilé, zejména když scraping kombinuješ s analýzou dat.
2. Který jazyk je nejlepší pro scraping webů náročných na JavaScript?
JavaScript (Node.js) je nejlepší volba pro dynamické weby. Nástroje jako Puppeteer a Playwright ti dají plnou kontrolu nad prohlížečem, takže můžeš pracovat i s obsahem načítaným přes React, Vue nebo Angular.
3. Existuje no-code varianta pro web scraping?
Ano — je no-code AI Web Scraper, který zvládá dynamický obsah i plánování. Stačí kliknout na „AI Suggest Fields“ a můžeš scrapovat. Je ideální pro sales, marketing nebo operations týmy, které potřebují rychle získat strukturovaná data.
Zjistěte více: