Nefunkční odkazy. Osiřelé stránky. „Testovací“ stránka z roku 2019, kterou Google nějakým zázrakem zaindexoval. Pokud spravuješ web, tuhle bolest dobře znáš.
Dobrý crawler tohle všechno odhalí — a hlavně zmapuje celý web, abys měl co opravovat. Jenže spousta lidí si plete „web crawler“ s „web scraper“. Není to totéž.
Otestoval jsem 10 bezplatných crawlerů na reálných webech. Některé jsou skvělé na SEO audity. Jiné se víc hodí na získávání dat. Tady je, co fungovalo — a co ne.
Co je website crawler? Základy bez zbytečných zmatků
Nejdřív si to pojďme srovnat: website crawler není totéž co web scraper. Jasně, tyhle pojmy se na internetu používají pořád a často se hází do jednoho pytle, ale ve skutečnosti jde o dvě odlišné věci. Crawler si představ jako kartografa tvého webu — dělá procházení webu, leze do každého kouta, sleduje odkazy a skládá mapu všech stránek. Jeho hlavní úkol je objevování: nacházet URL, chápat strukturu webu a indexovat obsah. Přesně takhle fungují boti vyhledávačů jako Google a taky SEO nástroje, když kontrolují „zdraví“ webu ().
Web scraper je naopak „těžař“ dat. Neřeší kompletní mapu — jde rovnou po tom, co potřebuje: ceny produktů, názvy firem, recenze, e-maily… prostě konkrétní hodnoty. Scraper vytahuje vybraná pole ze stránek, které crawler najde ().
Přirovnání:
- Crawler: člověk, který projde všechny uličky v supermarketu a sepíše seznam všeho zboží.
- Scraper: člověk, který jde rovnou k regálu s kávou a zapíše ceny všech bio směsí.
Proč na tom záleží? Protože pokud chceš jen najít všechny stránky na webu (třeba kvůli SEO auditu), potřebuješ crawler. Pokud chceš vytáhnout ceny produktů z webu konkurence, potřebuješ scraper — nebo ideálně nástroj pro web crawler, který zvládne obojí.
Proč používat online web crawler? Klíčové přínosy pro byznys
Proč se vůbec zabývat crawlingem? Web se rozhodně nezmenšuje. Ve skutečnosti přes pro optimalizaci webů a některé SEO nástroje denně procházejí až .
Co ti crawler může přinést:
- SEO audity: odhalí nefunkční odkazy, chybějící titulky, duplicitní obsah, osiřelé stránky a další problémy ().
- Kontrola odkazů & QA: zachytí 404 a smyčky přesměrování dřív, než na ně narazí uživatelé ().
- Generování sitemap: automaticky vytvoří XML sitemapu pro vyhledávače i plánování ().
- Inventura obsahu: získáš seznam všech stránek, jejich hierarchii a metadata.
- Compliance & přístupnost: prověří stránky z pohledu WCAG, SEO a právních požadavků ().
- Výkon & bezpečnost: upozorní na pomalé stránky, příliš velké obrázky nebo bezpečnostní rizika ().
- Data pro AI & analýzu: data z crawlu můžeš poslat do analytiky nebo AI nástrojů ().
Rychlá tabulka: kdo typicky crawler využije a proč:
| Použití | Pro koho | Přínos / výsledek |
|---|---|---|
| SEO & audit webu | Marketing, SEO, majitelé malých firem | Odhalení technických chyb, lepší struktura, vyšší pozice |
| Inventura obsahu & QA | Content manažeři, správci webu | Audit/migrace obsahu, kontrola rozbitých odkazů/obrázků |
| Generování leadů (scraping) | Sales, Biz Dev | Automatizace prospectingu, doplnění CRM o nové leady |
| Konkurenční analýza | E-commerce, produktoví manažeři | Monitoring cen, nových produktů, změn skladovosti |
| Sitemap & klonování struktury | Vývojáři, DevOps, konzultanti | Kopie struktury pro redesign nebo zálohy |
| Agregace obsahu | Výzkumníci, média, analytici | Sběr dat z více webů pro analýzu a sledování trendů |
| Průzkum trhu | Analytici, týmy pro trénink AI | Sběr velkých datasetů pro analýzu nebo trénink modelů |
()
Jak jsme vybírali nejlepší bezplatné nástroje pro crawling webu
Strávil jsem spoustu pozdních večerů (a vypil víc kávy, než bych chtěl přiznat) tím, že jsem zkoušel různé crawlery, četl dokumentaci a pouštěl testovací crawly. Tohle byly moje hlavní kriteriální body:
- Technické schopnosti: zvládne moderní weby (JavaScript, přihlášení, dynamický obsah)?
- Použitelnost: je to přívětivé i pro netechnické uživatele, nebo je potřeba kouzlit v příkazové řádce?
- Limity free plánu: je to opravdu zdarma, nebo jen ochutnávka?
- Dostupnost online: jde o cloud, desktop aplikaci, nebo knihovnu do kódu?
- Unikátní funkce: nabízí něco navíc — třeba AI extrakci, vizuální sitemapu nebo event-driven crawling?
Každý nástroj jsem otestoval, prošel zpětnou vazbu uživatelů a porovnal funkce vedle sebe. Pokud mě nějaký nástroj přiměl uvažovat o vyhození notebooku z okna, do výběru se nedostal.
Rychlé srovnání: 10 nejlepších bezplatných website crawlerů
| Nástroj & typ | Hlavní funkce | Nejlepší použití | Technické nároky | Detaily free plánu |
|---|---|---|---|---|
| BrightData (Cloud/API) | Enterprise crawling, proxy síť, renderování JS, řešení CAPTCHA | Sběr dat ve velkém | Hodí se technické znalosti | Zkušebně zdarma: 3 scrapery, 100 záznamů každý (cca 300 záznamů celkem) |
| Crawlbase (Cloud/API) | Crawling přes API, anti-bot, proxy, renderování JS | Vývojáři, kteří chtějí backend infrastrukturu pro crawling | Integrace API | Zdarma: ~5 000 API volání na 7 dní, poté 1 000/měsíc |
| ScraperAPI (Cloud/API) | Rotace proxy, renderování JS, asynchronní crawling, předpřipravené endpointy | Vývojáři, monitoring cen, SEO data | Minimální nastavení | Zdarma: 5 000 API volání na 7 dní, poté 1 000/měsíc |
| Diffbot Crawlbot (Cloud) | AI crawling + extrakce, knowledge graph, renderování JS | Strukturovaná data ve velkém, AI/ML | Integrace API | Zdarma: 10 000 kreditů/měsíc (cca 10k stránek) |
| Screaming Frog (Desktop) | SEO audit, analýza odkazů/metadat, sitemap, vlastní extrakce | SEO audity, správa webu | Desktop aplikace, GUI | Zdarma: 500 URL na jeden crawl, jen základní funkce |
| SiteOne Crawler (Desktop) | SEO, výkon, přístupnost, bezpečnost, offline export, Markdown | Vývoj, QA, migrace, dokumentace | Desktop/CLI, GUI | Zdarma & open-source, v GUI reportu standardně 1 000 URL (lze upravit) |
| Crawljax (Java, OpenSrc) | Event-driven crawling pro JS weby, statický export | Vývojáři, QA pro dynamické web aplikace | Java, CLI/konfigurace | Zdarma & open-source, bez limitů |
| Apache Nutch (Java, OpenSrc) | Distribuovaný crawling, pluginy, integrace s Hadoop, vlastní vyhledávání | Vlastní vyhledávače, crawling ve velkém | Java, příkazová řádka | Zdarma & open-source, platíte jen infrastrukturu |
| YaCy (Java, OpenSrc) | Peer-to-peer crawling & vyhledávání, soukromí, indexace webu/intranetu | Privátní vyhledávání, decentralizace | Java, UI v prohlížeči | Zdarma & open-source, bez limitů |
| PowerMapper (Desktop/SaaS) | Vizuální sitemap, přístupnost, QA, kompatibilita prohlížečů | Agentury, QA, vizuální mapování | GUI, jednoduché | Zkušební verze: 30 dní, 100 stránek (desktop) nebo 10 stránek (online) na jeden scan |
BrightData: cloudový crawler pro enterprise

BrightData je „těžká váha“ webového crawlování. Jde o cloudovou platformu s obří proxy sítí, renderováním JavaScriptu, řešením CAPTCHA a IDE pro vlastní crawly. Pokud sbíráš data ve velkém — třeba hlídáš ceny napříč stovkami e-shopů — infrastruktura BrightData se jen těžko překonává ().
Silné stránky:
- Zvládá náročné weby s anti-bot ochranou
- Škálovatelné pro enterprise potřeby
- Předpřipravené šablony pro běžné weby
Omezení:
- Nemá trvale bezplatný tarif (jen trial: 3 scrapery, 100 záznamů každý)
- Pro jednoduché audity může být zbytečně robustní
- Pro netechnické uživatele má určitou křivku učení
Pokud potřebuješ crawling ve velkém, BrightData je jako pronájem formule 1. Jen nečekej, že po testovací jízdě zůstane zdarma ().
Crawlbase: bezplatný web crawler přes API pro vývojáře

Crawlbase (dříve ProxyCrawl) je postavený na programovém použití. Zavoláš jejich API s URL a dostaneš HTML — proxy, geotargeting i CAPTCHA řeší na pozadí ().
Silné stránky:
- Vysoká úspěšnost (99 %+)
- Zvládá weby náročné na JavaScript
- Skvělé pro integraci do vlastních aplikací a workflow
Omezení:
- Je potřeba integrace přes API nebo SDK
- Free plán: ~5 000 API volání na 7 dní, poté 1 000/měsíc
Pokud jsi vývojář a chceš crawling (a případně i scraping) ve velkém bez správy proxy, Crawlbase je velmi solidní volba ().
ScraperAPI: jednodušší crawling dynamických webů

ScraperAPI je API typu „prostě mi to stáhni“. Dodáš URL, služba vyřeší proxy, headless prohlížeč i anti-bot ochranu a vrátí HTML (u některých webů i strukturovaná data). Hodí se hlavně na dynamické stránky a má poměrně štědrý free režim ().
Silné stránky:
- Pro vývojáře extrémně jednoduché (jedno API volání)
- Řeší CAPTCHA, blokace IP i JavaScript
- Zdarma: 5 000 API volání na 7 dní, poté 1 000/měsíc
Omezení:
- Žádné vizuální reporty z crawlu
- Pokud chceš následovat odkazy, musíš si logiku napsat sám
Pokud chceš napojit crawling do kódu během pár minut, ScraperAPI je jasná volba.
Diffbot Crawlbot: automatické objevování struktury webu

Diffbot Crawlbot je „chytrý“ přístup. Nejen že prochází web — pomocí AI také klasifikuje stránky a vytahuje strukturovaná data (články, produkty, události atd.) do JSON. Je to jako mít robotického stážistu, který fakt chápe, co čte ().
Silné stránky:
- AI extrakce, nejen crawling
- Zvládá JavaScript i dynamický obsah
- Zdarma: 10 000 kreditů/měsíc (cca 10k stránek)
Omezení:
- Spíš pro vývojáře (integrace přes API)
- Není to vizuální SEO nástroj — spíš pro datové projekty
Pokud potřebuješ strukturovaná data ve velkém (hlavně pro AI nebo analytiku), Diffbot je velmi silný hráč.
Screaming Frog: bezplatný desktop crawler pro SEO

Screaming Frog je klasika mezi desktop crawlery pro SEO audity. Ve free verzi projde až 500 URL na jeden scan a nabídne vše podstatné: rozbité odkazy, meta tagy, duplicitní obsah, sitemapu a další ().
Silné stránky:
- Rychlý, důkladný a v SEO komunitě prověřený
- Bez kódování — zadáš URL a jedeš
- Zdarma do 500 URL na crawl
Omezení:
- Pouze desktop (bez cloudové verze)
- Pokročilé funkce (renderování JS, plánování) jsou až v placené licenci
Pokud to se SEO myslíš vážně, Screaming Frog je povinná výbava — jen nečekej, že zdarma projde web o 10 000 stránkách.
SiteOne Crawler: export statického webu a dokumentace

SiteOne Crawler je takový švýcarský nůž pro technické audity. Je open-source, multiplatformní a kromě crawlování a auditu umí web exportovat i do Markdownu pro dokumentaci nebo offline použití ().
Silné stránky:
- Pokrývá SEO, výkon, přístupnost i bezpečnost
- Export pro archivaci nebo migraci
- Zdarma & open-source, bez limitů použití
Omezení:
- Technicky náročnější než některé čistě GUI nástroje
- Report v GUI je standardně omezen na 1 000 URL (lze nastavit)
Pokud jsi vývojář, QA nebo konzultant a chceš jít do hloubky (a máš rád open source), SiteOne je skrytý klenot.
Crawljax: open-source Java crawler pro dynamické stránky
Crawljax je specialista: je navržený pro moderní webové aplikace náročné na JavaScript a simuluje interakce uživatele (klikání, vyplňování formulářů apod.). Je event-driven a umí dokonce vyexportovat statickou verzi dynamického webu ().
Silné stránky:
- Bezkonkurenční pro SPA a AJAX-heavy weby
- Open-source a rozšiřitelný
- Bez limitů použití
Omezení:
- Vyžaduje Javu a určitou míru programování/konfigurace
- Není pro netechnické uživatele
Pokud potřebuješ procházet React nebo Angular aplikaci „jako člověk“, Crawljax je přesně ten typ nástroje.
Apache Nutch: škálovatelný distribuovaný crawler

Apache Nutch je veterán mezi open-source crawlery. Je stavěný na masivní distribuované crawly — třeba když si chceš postavit vlastní vyhledávač nebo indexovat miliony stránek ().
Silné stránky:
- Škáluje až na miliardy stránek s Hadoopem
- Vysoce konfigurovatelný a rozšiřitelný
- Zdarma & open-source
Omezení:
- Strmá křivka učení (Java, příkazová řádka, konfigurace)
- Nehodí se pro malé weby ani „příležitostné“ použití
Pokud chceš crawling ve velkém a nevadí ti práce v terminálu, Nutch je správná volba.
YaCy: peer-to-peer crawler a vyhledávač
YaCy je unikátní decentralizovaný crawler a vyhledávač. Každá instance prochází a indexuje weby a můžeš se připojit do P2P sítě, kde se indexy sdílejí mezi uživateli ().
Silné stránky:
- Důraz na soukromí, bez centrálního serveru
- Skvělé pro privátní vyhledávání nebo intranet
- Zdarma & open-source
Omezení:
- Kvalita výsledků závisí na pokrytí sítě
- Vyžaduje určité nastavení (Java, UI v prohlížeči)
Pokud tě baví decentralizace nebo chceš vlastní vyhledávač, YaCy je hodně zajímavá možnost.
PowerMapper: vizuální generátor sitemap pro UX a QA

PowerMapper je zaměřený na vizualizaci struktury webu. Projde web a vytvoří interaktivní sitemapu, zároveň kontroluje přístupnost, kompatibilitu prohlížečů a základní SEO ().
Silné stránky:
- Vizuální sitemap je skvělá pro agentury a designéry
- Kontroluje přístupnost a compliance
- Jednoduché GUI, bez technických znalostí
Omezení:
- Jen trial (30 dní, 100 stránek desktop / 10 stránek online na scan)
- Plná verze je placená
Pokud potřebuješ klientům ukázat mapu webu nebo řešíš compliance, PowerMapper je praktický nástroj.
Jak vybrat správný bezplatný web crawler
Jak se v tom neztratit? Tady je moje rychlá orientace:
- Na SEO audity: Screaming Frog (menší weby), PowerMapper (vizuálně), SiteOne (hlubší audity)
- Na dynamické web aplikace: Crawljax
- Na crawling ve velkém nebo vlastní vyhledávání: Apache Nutch, YaCy
- Pro vývojáře, kteří chtějí API: Crawlbase, ScraperAPI, Diffbot
- Na dokumentaci nebo archivaci: SiteOne Crawler
- Enterprise škála se zkušebkou: BrightData, Diffbot
Co zvažovat při výběru:
- Škálování: jak velký je web nebo úloha?
- Jednoduchost: chceš klikací GUI, nebo ti nevadí kód?
- Export dat: potřebuješ CSV, JSON nebo integraci do dalších nástrojů?
- Podpora: existuje komunita nebo dokumentace, když se zasekneš?
Když se crawling potká se scrapingem: proč je Thunderbit chytřejší volba
Realita je taková, že většina lidí nedělá procházení webu jen proto, aby měla hezkou mapu. Skutečný cíl bývá získat strukturovaná data — ať už jde o produktové seznamy, kontakty nebo inventuru obsahu. A přesně tady přichází na řadu .
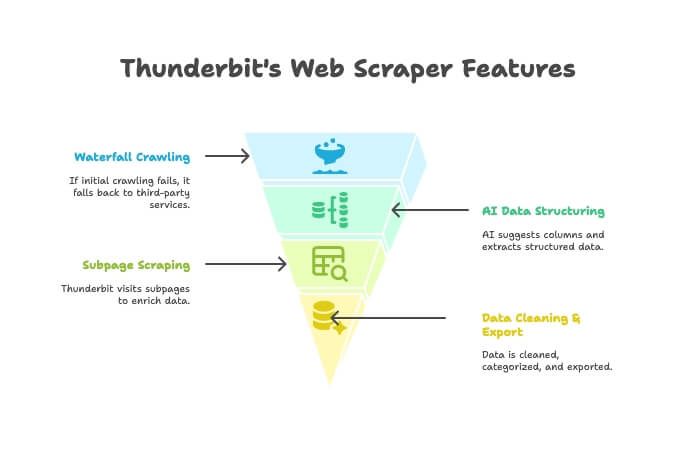
Thunderbit není jen crawler nebo jen scraper — je to AI Chrome rozšíření, které kombinuje obojí. Funguje to takto:
- AI Crawler: Thunderbit prozkoumá web podobně jako crawler.
- Waterfall Crawling: pokud se Thunderbitův vlastní engine na stránku nedostane (třeba kvůli tvrdé anti-bot ochraně), automaticky přepne na externí crawlingové služby — bez ručního nastavování.
- AI strukturování dat: jakmile má HTML, AI navrhne správné sloupce a vytáhne strukturovaná data (jména, ceny, e-maily atd.) bez psaní selektorů.
- Scraping podstránek: potřebuješ detaily z každé produktové stránky? Thunderbit umí automaticky navštívit podstránky a obohatit tabulku.
- Čištění dat & export: umí data shrnout, kategorizovat, přeložit a jedním kliknutím exportovat do Excelu, Google Sheets, Airtable nebo Notion.
- No-code jednoduchost: pokud umíš používat prohlížeč, zvládneš i Thunderbit. Bez kódu, bez proxy, bez nervů.
Kdy dává Thunderbit větší smysl než klasický crawler?
- Když chceš na konci čistý a použitelný spreadsheet, ne jen seznam URL.
- Když chceš automatizovat celý proces (crawl, extrakce, čištění, export) na jednom místě.
- Když si vážíš svého času (a klidu).
Thunderbit si můžeš a rychle zjistit, proč na něj přechází tolik byznys uživatelů.
Závěr: jak z bezplatných crawlerů vytěžit maximum
Website crawlery urazily velký kus cesty. Ať už jsi marketér, vývojář, nebo jen chceš udržet web v kondici, existuje pro tebe bezplatný (nebo alespoň „free-to-try“) nástroj. Od enterprise platforem jako BrightData a Diffbot, přes open-source poklady jako SiteOne a Crawljax, až po vizuální mapovače typu PowerMapper — nabídka je dnes širší než kdy dřív.
Pokud ale hledáš chytřejší a integrovanější cestu od „potřebuju ta data“ k „tady je moje tabulka“, zkus Thunderbit. Je postavený pro byznys uživatele, kteří chtějí výsledky, ne jen reporty.
Chceš začít? Stáhni si nástroj, spusť scan a uvidíš, co ti dosud unikalo. A pokud chceš přejít od crawlování k použitelným datům na dvě kliknutí, mrkni na .
Další praktické návody a hlubší rozbory najdeš na .
FAQ
Jaký je rozdíl mezi website crawlerem a web scraperem?
Crawler objevuje a mapuje všechny stránky webu (jako když vytváříš obsah/„table of contents“). Scraper z těchto stránek vytahuje konkrétní datová pole (např. ceny, e-maily nebo recenze). Crawler najde, scraper vytěží ().
Který bezplatný web crawler je nejlepší pro netechnické uživatele?
Na menší weby a SEO audity je Screaming Frog poměrně přívětivý. Na vizuální mapování je skvělý PowerMapper (během trialu). Thunderbit je nejjednodušší, pokud chceš hlavně strukturovaná data a preferuješ no-code práci přímo v prohlížeči.
Existují weby, které web crawlery blokují?
Ano — některé weby používají robots.txt nebo anti-bot ochranu (CAPTCHA, blokace IP) a crawling omezují. Nástroje jako ScraperAPI, Crawlbase a Thunderbit (díky waterfall crawling) to často dokážou obejít, ale vždy crawluj zodpovědně a respektuj pravidla webu ().
Mají bezplatné website crawlery limity na počet stránek nebo funkce?
Většinou ano. Například Screaming Frog má ve free verzi limit 500 URL na crawl; trial PowerMapperu je 100 stránek. API nástroje mívají měsíční limity kreditů. Open-source nástroje jako SiteOne nebo Crawljax obvykle nemají tvrdé limity, ale jsi omezený výkonem svého hardwaru.
Je používání web crawleru legální a v souladu s ochranou soukromí?
Obecně platí, že crawling veřejně dostupných stránek je legální, ale vždy si ověř podmínky použití webu a robots.txt. Nikdy necrawluj soukromá nebo heslem chráněná data bez svolení a při extrakci osobních údajů mysli na zákony o ochraně soukromí ().