
Webová data jsou dnes základ pro prodej, marketing i provoz. Pokud je pořád kopírujete ručně, zbytečně zaostáváte.
Jenže problém s „bezplatnými“ nástroji na scraping je v tom, že většina z nich ve skutečnosti zase tak zdarma není. Buď jde jen o zkušební verze s tvrdými limity, nebo zamykají funkce, které opravdu potřebujete, za paywallem.
Prošel jsem 12 nástrojů, abych zjistil, které z nich na bezplatném tarifu zvládnou skutečnou práci. Scrapoval jsem záznamy v Google Maps, dynamické stránky za přihlášením i PDF. Některé obstály. Jiné mi jen sežraly odpoledne.
Tady je poctivý rozbor — začnu těmi, které bych opravdu doporučil.
Proč jsou bezplatné scrapery důležitější než kdy dřív
Řekněme si to na rovinu: v roce 2026 už web scraping není jen pro hackery nebo datové vědce. Stal se běžnou součástí moderních firem, a potvrzují to i čísla. Trh se softwarem pro web scraping dosáhl a do roku 2032 se má víc než zdvojnásobit. Proč? Protože webová data používají všichni — od obchodních týmů po realitní makléře — aby získali náskok.
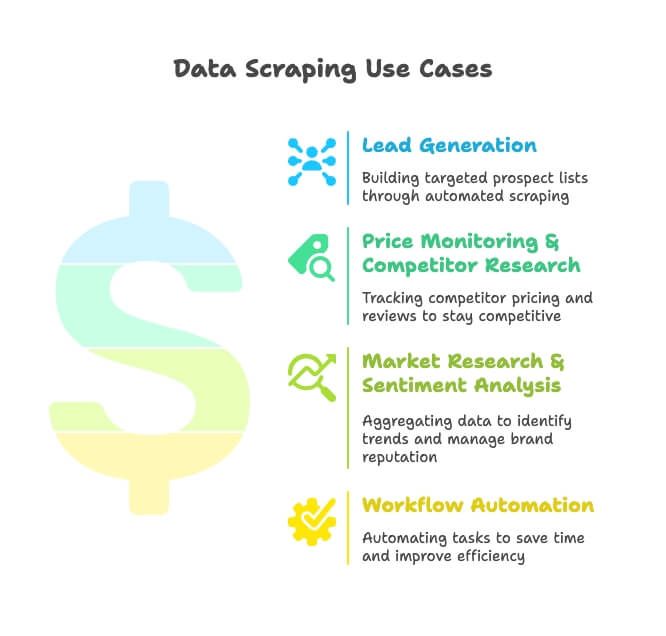
- Generování leadů: Obchodní týmy scrapují adresáře, Google Maps a sociální sítě, aby si sestavily cílené seznamy potenciálních klientů — žádné ruční hledání.
- Sledování cen a průzkum konkurence: Týmy v e-commerce a retailu sledují produkty konkurence, ceny i recenze, aby měly přehled (a ano, 82 % e‑commerce firem je scrapuje právě z tohoto důvodu).
- Průzkum trhu a analýza sentimentu: Marketéři shromažďují recenze, zprávy a diskuse na sociálních sítích, aby odhalili trendy a chránili reputaci značky.
- Automatizace workflow: Provozní týmy automatizují všechno od kontroly zásob po pravidelné reporty a šetří tak každý týden hodiny práce.
A ještě jedna zajímavost: firmy používající AI web scrapery šetří oproti ručním metodám. To nejsou jen drobné úspory — to je rozdíl mezi odchodem domů v 18:00 nebo ve 21:00.
Jak jsme vybírali nejlepší bezplatné nástroje na extrakci dat
Už jsem viděl spoustu seznamů „nejlepší web scraper“, které jen přepisují marketingové texty. Tady ne. Pro tenhle seznam jsem se zaměřil na:
- Skutečnou použitelnost bezplatného plánu: Umožní free tarif dělat reálnou práci, nebo je to jen ochutnávka?
- Snadnost použití: Zvládne i neprogramátor výsledky za pár minut, nebo potřebuje PhD z Regex?
- Podporované typy webů: Statické, dynamické, stránkované, vyžadující přihlášení, PDF, sociální sítě — zvládne nástroj reálné scénáře?
- Možnosti exportu dat: Dostanete data do Excelu, Google Sheets, Notion nebo Airtable bez zbytečných obstrukcí?
- Doplňkové funkce: AI extrakce, plánování, šablony, následné zpracování, integrace.
- Pro koho je nástroj určen: Pro firemní uživatele, analytiky, nebo vývojáře?
Prošel jsem také dokumentaci každého nástroje, testoval onboarding a porovnal limity bezplatných plánů — protože „zdarma“ neznamená vždycky to, co si pod tím představíte.
Přehled: 12 bezplatných nástrojů na extrakci dat vedle sebe
Tady je rychlé srovnání, které vám pomůže zúžit výběr na nástroj podle vašich potřeb.
| Nástroj | Platforma | Omezení bezplatného plánu | Nejlepší pro | Formáty exportu | Jedinečné funkce |
|---|---|---|---|---|---|
| Thunderbit | Rozšíření pro Chrome | 6 stránek měsíčně | Neprogramátoři, firmy | Excel, CSV | AI prompty, scraping PDF/obrázků, procházení podstránek |
| Browse AI | Cloud | 50 kreditů měsíčně | Uživatelé bez kódu | CSV, Sheets | Roboti typu klikni a ukaž, plánování |
| Octoparse | Desktop | 10 úloh, 50 tis. řádků/měsíc | Bez kódu, mírně technicky zdatní | CSV, Excel, JSON | Vizuální workflow, podpora dynamických webů |
| ParseHub | Desktop | 5 projektů, 200 stránek na běh | Bez kódu, mírně technicky zdatní | CSV, Excel, JSON | Vizuální rozhraní, podpora dynamických webů |
| Webscraper.io | Rozšíření pro Chrome | Neomezené lokální použití | Bez kódu, jednoduché úlohy | CSV, XLSX | Na bázi sitemap, komunitní šablony |
| Apify | Cloud | 5 dolarů v kreditech měsíčně | Týmy, mírně technicky zdatní, vývojáři | CSV, JSON, Sheets | Marketplace actorů, plánování, API |
| Scrapy | Knihovna v Pythonu | Neomezeně (open source) | Vývojáři | CSV, JSON, DB | Plná kontrola přes kód, škálovatelnost |
| Puppeteer | Knihovna pro Node.js | Neomezeně (open source) | Vývojáři | Vlastní (kód) | Headless prohlížeč, podpora dynamického JS |
| Selenium | Vícejazyčné | Neomezeně (open source) | Vývojáři | Vlastní (kód) | Automatizace prohlížeče, podpora více prohlížečů |
| Zyte | Cloud | 1 spider, 1 hod./úloha, retence 7 dní | Vývojáři, provozní týmy | CSV, JSON | Hostovaný Scrapy, správa proxy |
| SerpAPI | API | 100 vyhledávání měsíčně | Vývojáři, analytici | JSON | API pro vyhledávače, ochrana proti blokování |
| Diffbot | API | 10 000 kreditů měsíčně | Vývojáři, AI projekty | JSON | AI extrakce, znalostní graf |
Thunderbit: Nejlepší volba pro AI web scraping s důrazem na snadné použití
Pojďme si říct, proč stojí na vrcholu mého seznamu. Neříkám to jen proto, že jsem součástí týmu — opravdu věřím, že Thunderbit je nejblíž tomu mít AI stážistu, který skutečně poslouchá (a nežádá pauzu na kávu).
Thunderbit není typický zážitek ve stylu „nejdřív se nauč nástroj a pak scrapuj“. Je to spíš jako zadat úkol chytrému asistentovi: popíšete, co chcete („Vytáhni ze stránky všechna názvy produktů, ceny a odkazy“), a AI Thunderbitu se postará o zbytek. Žádné XPath, žádné CSS selektory, žádné trápení s Regex. A pokud chcete scrapovat podstránky (třeba detail produktu nebo kontaktní odkazy firmy), Thunderbit může automaticky proklikávat dál a obohatit vaši tabulku — zase jen jedním kliknutím na tlačítko.
To, co Thunderbit opravdu odlišuje, ale přichází až po scrapování. Potřebujete data shrnout, přeložit, zařadit nebo vyčistit? Vestavěné AI následné zpracování Thunderbitu to zvládne. Nedostanete jen syrová data — dostanete strukturované, použitelné informace připravené pro CRM, tabulku nebo další velký projekt.
Bezplatný plán: Bezplatná verze Thunderbitu umožňuje scrapovat až 6 stránek (nebo 10 se zkušebním bonusem), včetně PDF, obrázků a dokonce i šablon pro sociální sítě. Export do Excelu nebo CSV je zdarma a můžete si vyzkoušet i funkce jako extrakci e-mailů, telefonních čísel a obrázků. Pro větší úlohy odemykají placené plány více stránek, přímý export do Google Sheets/Notion/Airtable, plánované scrapování a okamžité šablony pro oblíbené weby jako Amazon, Google Maps a Instagram.
Pokud chcete Thunderbit vidět v akci, podívejte se na nebo si projděte náš s rychlými úvodními videi.
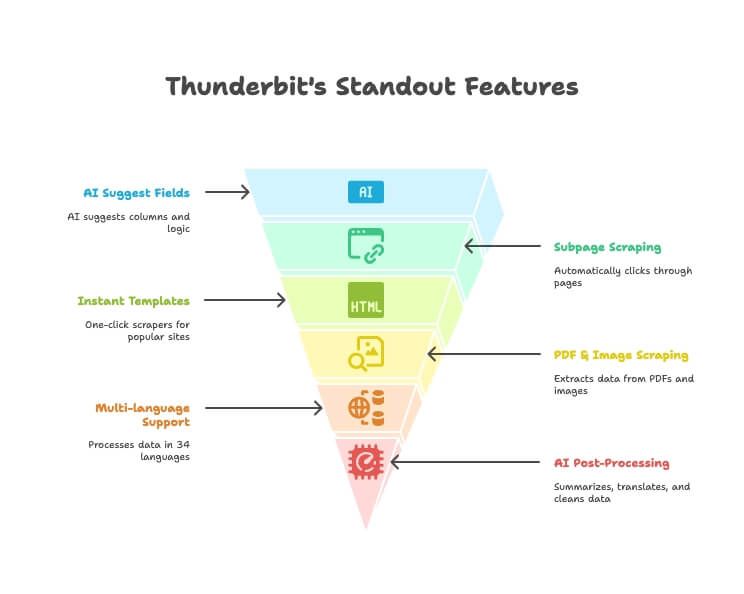
Výrazné funkce Thunderbitu
- AI návrh polí: Stačí popsat data, která chcete, a AI Thunderbitu navrhne správné sloupce i logiku extrakce.
- Scraping podstránek: Automaticky prokliká detailní stránky nebo odkazy a obohatí hlavní tabulku — bez ručního nastavování.
- Okamžité šablony: Scrapery na jedno kliknutí pro Amazon, Google Maps, Instagram a další.
- Scraping PDF a obrázků: Extrahujte tabulky a data z PDF i obrázků pomocí AI — bez dalších nástrojů.
- Podpora více jazyků: Scrapujte a zpracovávejte data ve 34 jazycích.
- Přímý export: Odesílejte data rovnou do Excelu, Google Sheets, Notion nebo Airtable (placené plány).
- AI následné zpracování: Shrnutí, překlad, kategorizace i čištění dat při scrapování.
- Bezplatná extrakce e-mailů/telefonů/obrázků: Získejte kontaktní údaje nebo obrázky z libovolného webu jedním kliknutím.
Thunderbit propojuje „jen scrapování dat“ a „získání dat, která opravdu využijete“. Je to nejblíž, co jsem zatím viděl, skutečnému AI datovému asistentovi pro firemní uživatele.
Zbytek top 12: recenze bezplatných nástrojů na extrakci dat
Pojďme projít zbytek pole podle toho, pro koho jsou jednotlivé nástroje nejvhodnější.
Pro uživatele bez kódu a firemní uživatele
Thunderbit
Už jsme ho zmínili výše. Nejjednodušší start pro neprogramátory, s AI funkcemi a okamžitými šablonami.
Webscraper.io
- Platforma: Rozšíření pro Chrome
- Nejlepší pro: Jednoduché, statické weby; neprogramátory, kterým nevadí trochu pokusů a omylů.
- Klíčové funkce: Scraping na bázi sitemap, podpora stránkování, export CSV/XLSX.
- Bezplatný plán: Neomezené lokální použití, ale žádné cloudové běhy ani plánování. Jen ruční spuštění.
- Omezení: Nemá vestavěnou podporu přihlášení, PDF ani složitého dynamického obsahu. Jen komunitní podpora.
ParseHub
- Platforma: Desktop aplikace (Windows, Mac, Linux)
- Nejlepší pro: Neprogramátory a méně technické uživatele, kteří do učení chtějí investovat čas.
- Klíčové funkce: Vizuální builder workflow, podpora dynamických webů, AJAX, přihlášení, stránkování.
- Bezplatný plán: 5 veřejných projektů, 200 stránek na běh, jen ruční spouštění.
- Omezení: Projekty jsou na free tarifu veřejné (pozor na citlivá data), bez plánování, pomalejší extrakce.
Octoparse
- Platforma: Desktop aplikace (Windows/Mac), Cloud (placený)
- Nejlepší pro: Neprogramátory a analytiky, kteří chtějí výkon i flexibilitu.
- Klíčové funkce: Vizuální ovládání klikáním, podpora dynamického obsahu, šablony pro oblíbené weby.
- Bezplatný plán: 10 úloh, až 50 000 řádků měsíčně, jen desktop (bez cloudu/plánování).
- Omezení: Na free tarifu žádné API, rotace IP ani plánování. U složitých webů může být křivka učení prudká.
Browse AI
- Platforma: Cloud
- Nejlepší pro: Uživatelé bez kódu, kteří chtějí automatizovat jednoduchý scraping a monitoring.
- Klíčové funkce: Záznam robotů klikáním, plánování, integrace (Sheets, Zapier).
- Bezplatný plán: 50 kreditů měsíčně, 1 web, až 5 robotů.
- Omezení: Omezený objem, u složitých webů určitá počáteční křivka učení.
Pro vývojáře a technické uživatele
Scrapy
- Platforma: Knihovna v Pythonu (open source)
- Nejlepší pro: Vývojáře, kteří chtějí plnou kontrolu a škálovatelnost.
- Klíčové funkce: Vysoce přizpůsobitelné, podporuje velké crawlery, middleware, pipeline.
- Bezplatný plán: Neomezeně (open source).
- Omezení: Žádné GUI, vyžaduje programování v Pythonu. Není pro neprogramátory.
Puppeteer
- Platforma: Knihovna pro Node.js (open source)
- Nejlepší pro: Vývojáře scrapující dynamické weby s velkým množstvím JavaScriptu.
- Klíčové funkce: Automatizace headless prohlížeče, plná kontrola nad navigací a extrakcí.
- Bezplatný plán: Neomezeně (open source).
- Omezení: Vyžaduje programování v JavaScriptu, bez GUI.
Selenium
- Platforma: Vícejazyčné (Python, Java atd.), open source
- Nejlepší pro: Vývojáře automatizující prohlížeče pro scraping nebo testování.
- Klíčové funkce: Podpora více prohlížečů, automatizace klikání, scrollování i přihlášení.
- Bezplatný plán: Neomezeně (open source).
- Omezení: Pomalejší než headless knihovny, vyžaduje skriptování.
Zyte (Scrapy Cloud)
- Platforma: Cloud
- Nejlepší pro: Vývojáře a provozní týmy nasazující Scrapy spiders ve velkém.
- Klíčové funkce: Hostovaný Scrapy, správa proxy, plánování úloh.
- Bezplatný plán: 1 souběžný spider, 1 hodina na úlohu, retence dat 7 dní.
- Omezení: Na free tarifu žádné pokročilé plánování, je třeba znát Scrapy.
Pro týmy a enterprise použití
Apify
- Platforma: Cloud
- Nejlepší pro: Týmy, méně technické uživatele a vývojáře, kteří chtějí hotové nebo vlastní scrapery.
- Klíčové funkce: Marketplace actorů (předpřipravené boty), plánování, API, integrace.
- Bezplatný plán: 5 dolarů v kreditech měsíčně (na malé úlohy dostačující), retence dat 7 dní.
- Omezení: Určitá křivka učení, použití omezené kredity.
SerpAPI
- Platforma: API
- Nejlepší pro: Vývojáře a analytiky, kteří potřebují data z vyhledávačů (Google, Bing, YouTube).
- Klíčové funkce: API pro vyhledávače, ochrana proti blokování, strukturovaný JSON výstup.
- Bezplatný plán: 100 vyhledávání měsíčně.
- Omezení: Není pro libovolné weby, pouze API použití.
Diffbot
- Platforma: API
- Nejlepší pro: Vývojáře, AI/ML týmy a enterprise, které potřebují strukturovaná webová data ve velkém.
- Klíčové funkce: AI extrakce, znalostní graf, API pro články a produkty.
- Bezplatný plán: 10 000 kreditů měsíčně.
- Omezení: Jen přes API, vyžaduje technické dovednosti, omezená propustnost.
Omezení bezplatných plánů: Co „zdarma“ vlastně znamená u jednotlivých nástrojů
Buďme upřímní — „zdarma“ může znamenat cokoli od „neomezeně pro hobby uživatele“ po „tak akorát, aby vás to nalákalo“. Tady je rozpad toho, co skutečně dostanete:
| Nástroj | Stránek/řádků za měsíc | Formáty exportu | Plánování | Přístup k API | Významná omezení zdarma |
|---|---|---|---|---|---|
| Thunderbit | 6 stránek | Excel, CSV | Ne | Ne | Omezený AI návrh polí, bez přímého exportu do Sheets/Notion na free tarifu |
| Browse AI | 50 kreditů | CSV, Sheets | Ano | Ano | 1 web, 5 robotů, retence 15 dní |
| Octoparse | 50 000 řádků | CSV, Excel, JSON | Ne | Ne | Jen desktop, bez cloudu/plánování |
| ParseHub | 200 stránek na běh | CSV, Excel, JSON | Ne | Ne | 5 veřejných projektů, pomalejší rychlost |
| Webscraper.io | Neomezeně lokálně | CSV, XLSX | Ne | Ne | Ruční běhy, bez cloudu |
| Apify | 5 dolarů v kreditech (~malé úlohy) | CSV, JSON, Sheets | Ano | Ano | Retence 7 dní, kreditový strop |
| Scrapy | Neomezeně | CSV, JSON, DB | Ne | N/A | Nutné programování |
| Puppeteer | Neomezeně | Vlastní (kód) | Ne | N/A | Nutné programování |
| Selenium | Neomezeně | Vlastní (kód) | Ne | N/A | Nutné programování |
| Zyte | 1 spider, 1 hod./úloha | CSV, JSON | Omezeně | Ano | Retence 7 dní, 1 souběžná úloha |
| SerpAPI | 100 vyhledávání | JSON | Ne | Ano | Jen API pro vyhledávače |
| Diffbot | 10 000 kreditů | JSON | Ne | Ano | Jen API, s omezenou rychlostí |
Shrnutí: Pro skutečné projekty nabízejí Thunderbit, Browse AI a Apify nejpoužitelnější bezplatné verze pro firemní uživatele. Pro průběžný nebo rozsáhlý scraping narazíte na limity poměrně rychle a budete muset přejít na placený tarif nebo na open-source / kódová řešení.
Který nástroj na extrakci dat je pro vás nejlepší? (Průvodce podle typu uživatele)
Tady je tahák, který vám pomůže vybrat správný nástroj podle role a vztahu k technologiím:
| Typ uživatele | Nejlepší nástroje zdarma | Proč |
|---|---|---|
| Neprogramátor (prodej/marketing) | Thunderbit, Browse AI, Webscraper.io | Nejrychlejší na naučení, klikání bez kódu, pomoc AI |
| Mírně technický uživatel (provoz/analytik) | Octoparse, ParseHub, Apify, Zyte | Větší výkon, zvládnou složité weby, možnost částečného skriptování |
| Vývojář/inženýr | Scrapy, Puppeteer, Selenium, Diffbot, SerpAPI | Plná kontrola, neomezené možnosti, API-first |
| Tým/enterprise | Apify, Zyte | Spolupráce, plánování, integrace |
Reálné scénáře web scrapingu: srovnání přizpůsobivosti nástrojů
Podívejme se, jak si tyto nástroje vedou v pěti běžných scénářích scrapingu:
| Scénář | Thunderbit | Browse AI | Octoparse | ParseHub | Webscraper.io | Apify | Scrapy | Puppeteer | Selenium | Zyte | SerpAPI | Diffbot |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Seznamy se stránkováním | Snadno | Snadno | Středně | Středně | Středně | Snadno | Snadno | Snadno | Snadno | Snadno | N/A | Středně |
| Záznamy v Google Maps | Snadno* | Těžko | Středně | Středně | Těžko | Snadno | Těžko | Těžko | Těžko | Těžko | Snadno | N/A |
| Stránky vyžadující přihlášení | Snadno | Středně | Středně | Středně | Ručně | Středně | Snadno | Snadno | Snadno | Snadno | N/A | N/A |
| Extrakce dat z PDF | Snadno | Ne | Ne | Ne | Ne | Středně | Těžko | Těžko | Těžko | Těžko | Ne | Omezeně |
| Obsah sociálních sítí | Snadno* | Částečně | Těžko | Těžko | Těžko | Snadno | Těžko | Těžko | Těžko | Těžko | YouTube | Omezeně |
- Thunderbit a Apify nabízejí předpřipravené šablony/actory pro Google Maps a scraping sociálních sítí, takže jsou tyto scénáře pro netechnické uživatele mnohem jednodušší.
Rozšíření vs. desktop vs. cloud: Jaký zážitek z web scrapingu je nejlepší?
- Rozšíření do Chrome (Thunderbit, Webscraper.io):
- Výhody: Rychlý start, běží v prohlížeči, minimální nastavení.
- Nevýhody: Ruční provoz, může být ovlivněno změnami webu, omezená automatizace.
- Přínos Thunderbitu: AI si poradí se změnami struktury, navigací na podstránky i scrapingem PDF/obrázků — je tak mnohem robustnější než tradiční rozšíření.
- Desktop aplikace (Octoparse, ParseHub):
- Výhody: Výkonné, vizuální workflow, zvládají dynamické weby a přihlášení.
- Nevýhody: Strmější křivka učení, na free tarifech bez cloudové automatizace, závislost na OS.
- Cloudové platformy (Browse AI, Apify, Zyte):
- Výhody: Plánování, týmová spolupráce, škálovatelnost, integrace.
- Nevýhody: Free plány bývají často omezené kredity, něco je potřeba nastavit a někdy je nutná znalost API.
- Open-source knihovny (Scrapy, Puppeteer, Selenium):
- Výhody: Neomezené, přizpůsobitelné, ideální pro vývojáře.
- Nevýhody: Vyžadují kód, nehodí se pro firemní uživatele.
Trendy web scrapingu v roce 2026: Co odlišuje moderní nástroje
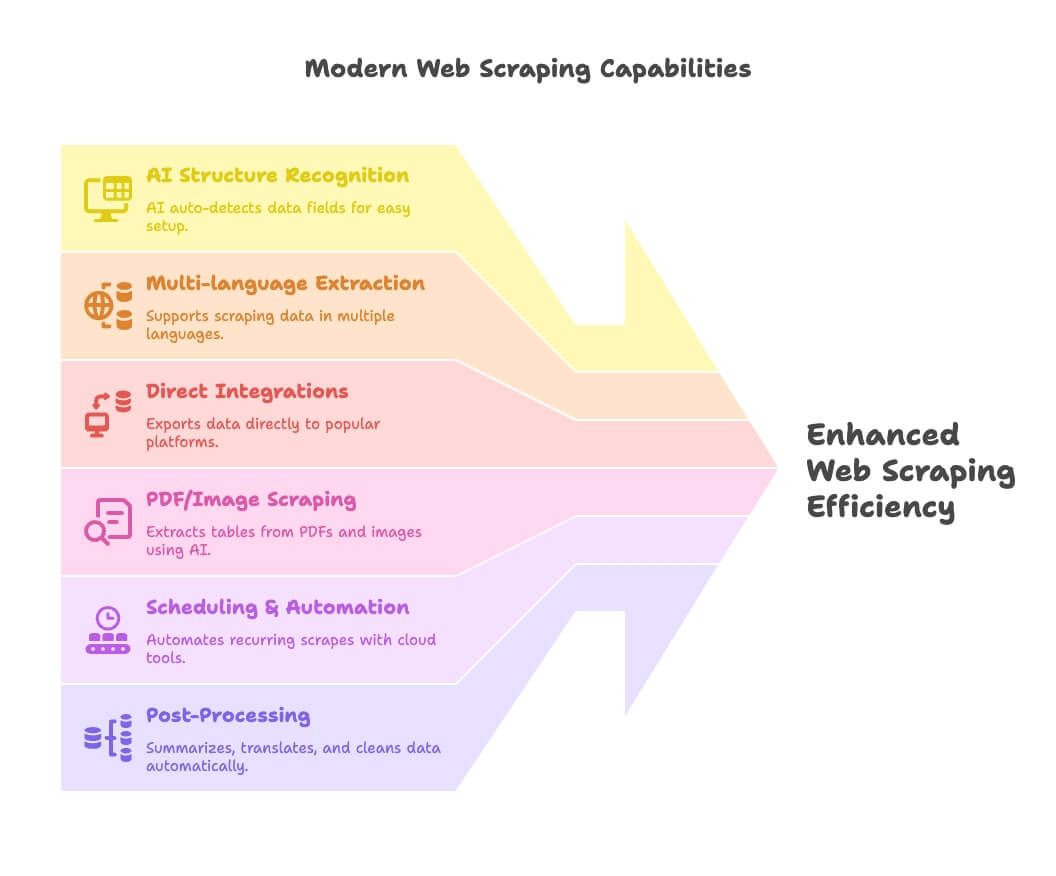
Web scraping v roce 2026 je hlavně o AI, automatizaci a integracích. Tady je to nové:
- AI rozpoznávání struktury: Nástroje jako Thunderbit používají AI k automatické detekci datových polí, takže nastavení je pro neprogramátory hračka.
- Vícejazyčná extrakce: Thunderbit a další podporují scraping i zpracování dat v desítkách jazyků.
- Přímé integrace: Exportujte scrapovaná data rovnou do Google Sheets, Notion nebo Airtable — žádné další přetahování CSV.
- Scraping PDF/obrázků: Thunderbit v tom vede, protože umožňuje extrahovat tabulky z PDF i obrázků pomocí AI.
- Plánování a automatizace: Cloudové nástroje (Apify, Browse AI) umožňují nastavit opakované scrapování a pak už na něj nemusíte myslet.
- Následné zpracování: Shrnutí, překlad, kategorizace a čištění dat přímo během scrapingu — žádné chaotické tabulky.
Thunderbit, Apify a SerpAPI stojí v čele těchto trendů, ale Thunderbit vyniká tím, že AI scraping zpřístupňuje všem, ne jen vývojářům.
Nad rámec scrapingu: zpracování dat a přidané funkce
Nejde jen o získání dat — jde o to, aby byla užitečná. Takhle si vedou přední nástroje v oblasti následného zpracování:
| Nástroj | Čištění | Překlad | Kategorizace | Shrnutí | Poznámky |
|---|---|---|---|---|---|
| Thunderbit | Ano | Ano | Ano | Ano | Vestavěné AI následné zpracování |
| Apify | Částečně | Částečně | Částečně | Částečně | Záleží na použitém actoru |
| Browse AI | Ne | Ne | Ne | Ne | Jen syrová data |
| Octoparse | Částečně | Ne | Částečně | Ne | Některé úpravy polí |
| ParseHub | Částečně | Ne | Částečně | Ne | Některé úpravy polí |
| Webscraper.io | Ne | Ne | Ne | Ne | Jen syrová data |
| Scrapy | Ano* | Ano* | Ano* | Ano* | Pokud to naprogramuje vývojář |
| Puppeteer | Ano* | Ano* | Ano* | Ano* | Pokud to naprogramuje vývojář |
| Selenium | Ano* | Ano* | Ano* | Ano* | Pokud to naprogramuje vývojář |
| Zyte | Částečně | Ne | Částečně | Ne | Některé funkce automatické extrakce |
| SerpAPI | Ne | Ne | Ne | Ne | Jen strukturovaná data z vyhledávání |
| Diffbot | Ano | Ano | Ano | Ano | AI-powered, ale pouze přes API |
- Logiku zpracování musí implementovat vývojář.
Thunderbit je jediný nástroj, který umožňuje i netechnickým uživatelům přejít od syrových webových dat ke strukturovaným, použitelným poznatkům — vše v jednom workflow.
Komunita, podpora a studijní zdroje: jak se rychle dostat do tempa
Dokumentace a onboarding jsou hodně důležité. Takhle si nástroje vedou:
| Nástroj | Dokumentace a návody | Komunita | Šablony | Křivka učení |
|---|---|---|---|---|
| Thunderbit | Výborná | Rostoucí | Ano | Velmi nízká |
| Browse AI | Dobrá | Dobrá | Ano | Nízká |
| Octoparse | Výborná | Velká | Ano | Střední |
| ParseHub | Výborná | Velká | Ano | Střední |
| Webscraper.io | Dobrá | Fórum | Ano | Střední |
| Apify | Výborná | Velká | Ano | Středně vysoká |
| Scrapy | Výborná | Obrovská | N/A | Vysoká |
| Puppeteer | Dobrá | Velká | N/A | Vysoká |
| Selenium | Dobrá | Obrovská | N/A | Vysoká |
| Zyte | Dobrá | Velká | Ano | Středně vysoká |
| SerpAPI | Dobrá | Střední | N/A | Vysoká |
| Diffbot | Dobrá | Střední | N/A | Vysoká |
Thunderbit a Browse AI jsou pro začátečníky nejsnazší. Octoparse a ParseHub mají skvělé zdroje, ale vyžadují víc trpělivosti. Apify a vývojářské nástroje mají strmější křivku učení, ale dokumentace je kvalitní.
Závěr: Jak si v roce 2026 vybrat správný bezplatný nástroj na extrakci dat
Tady je hlavní závěr: ne všechny „bezplatné“ nástroje na extrakci dat jsou stejně použitelné a váš výběr by měl záviset na roli, technické pohodě a skutečných potřebách scrapingu.
- Pokud jste firemní uživatel nebo neprogramátor a chcete data získat rychle — zvlášť z komplikovaných webů, PDF nebo obrázků — Thunderbit je nejlepší místo, kde začít. Jeho AI přístup, prompty v přirozeném jazyce a funkce následného zpracování z něj dělají nejbližší věc skutečnému AI datovému asistentovi. Vyzkoušejte zdarma a uvidíte, jak rychle se dostanete od „potřebuju tahle data“ k „tady je moje tabulka“.
- Pokud jste vývojář nebo potřebujete neomezený, přizpůsobitelný scraping, open-source nástroje jako Scrapy, Puppeteer a Selenium jsou vaše nejlepší volba.
- Pro týmy a mírně technické uživatele nabízejí Apify a Zyte škálovatelná, týmová řešení s velkorysými free tarify pro menší úlohy.
Ať už vypadá váš workflow jakkoli, začněte nástrojem, který odpovídá vašim dovednostem i potřebám. A pamatujte: v roce 2026 nemusíte být programátor, abyste využili sílu webových dat — potřebujete jen správného asistenta (a možná trochu smyslu pro humor, když vás roboti začnou přebíhat).
Chcete se ponořit hlouběji? Podívejte se na další průvodce a srovnání na , například: