
Amazon má a ve svém katalogu . Pokud jste někdy zkoušeli ručně kopírovat názvy produktů, ceny, hodnocení a ASIN do tabulky, víte, jaká je to otrava — a jak rychle vám to přeroste přes hlavu.
Pracuji v , kde vyvíjíme AI web scraper, takže často přemýšlím o tom, jak lidé získávají data z webu. Pro tenhle článek jsem ale chtěl udělat něco, co se v podobných přehledech moc nevidí: postavit vedle sebe sedm reálných rozšíření pro Chrome, která můžete nainstalovat a používat na Amazonu, otestovat je na stejných stránkách a dát vám přímou odpověď na to, co funguje, co nefunguje a kam se které nástroje hodí. Každé rozšíření jsem hodnotil podle osmi kritérií, která přímo odrážejí frustrace, které vídám ve fórech i u našich uživatelů — například rozpoznávání polí pomocí AI, scrapování podstránek, riziko zablokování, bezplatné plány a možnosti exportu. Ať už jste prodávající na Amazonu, marketér, nebo prostě jen někdo, koho už nebaví kopírování a vkládání, tenhle průvodce je pro vás.
Proč vůbec scrapovat data o produktech z Amazonu?
Kdo tedy Amazon skutečně scrapuje a proč?
Stručná odpověď: skoro každý, kdo online prodává, dělá marketing nebo zkoumá produkty. Amazon uvádí, že v jeho obchodě pochází od nezávislých prodejců, a ti se neustále navzájem sledují. Tohle jsou nejčastější use cases, které vídám:
| Use Case | Kdo to dělá | Co získají |
|---|---|---|
| Sledování cen konkurence | Prodejci, cenové týmy, agentury | Aktuální data o ceně a dostupnosti konkurenčních produktů |
| Výzkum produktů a sledování trendů | Prodejci na Amazonu, tržní analytici | Odhalení rostoucích kategorií, nových hráčů a změn poptávky |
| Analýza sentimentu recenzí | Prodejci privátních značek, brand týmy | Opakující se stížnosti, mezery ve funkcích a příležitosti |
| Generování leadů (kontakty prodejců) | Velkoobchodní týmy, agentury | Jména prodejců, storefronty a kontaktní údaje |
| Sledování katalogu a zásob | Ecommerce operations, ochrana značky | Přehled o skladových zásobách, změnách listingů a neautorizovaných prodejcích |
| Optimalizace klíčových slov a listingů | Vlastníci značek, provozovatelé marketplace | Data o vyhledávacích dotazech, text listingů a klíčová slova konkurence |
Návratnost je hmatatelná. Vlastní případové studie Amazonu ukazují, že poté, co optimalizoval pro nejdůležitější vyhledávací výrazy pomocí strukturovaných dat. A ukázal, že pracovníci tráví víc než 9 hodin týdně opakovaným ručním zadáváním dat. Když zautomatizujete byť jen část toho, uvolníte si dost času na skutečné rozhodování.
Co dělá z rozšíření pro Chrome na Amazon scraper skutečně dobrý nástroj? (Moje testovací kritéria)
Ne každé rozšíření pro Chrome je stejné — a většina srovnávacích článků hází dohromady API, desktopové aplikace a rozšíření do prohlížeče, jako by šlo o totéž. Nejde. Tady je rámec, který jsem použil, a proč na jednotlivých kritériích záleží:
- Snadnost nastavení – Dokáže i netechnický uživatel získat výsledky do 5 minut? (Fóra potvrzují, že je to jedno z hlavních témat.)
- Rozpoznávání polí pomocí AI – Dokáže nástroj automaticky rozpoznat pole produktu, nebo musíte ručně nastavovat selektory? (Žádný konkurenční článek to ani nebere jako samostatnou kategorii.)
- Scrapování podstránek / detailních stránek – Dokáže obohatit data z listingu o informace z detailní stránky produktu v jednom workflow?
- Ochrana proti botům / riziko zablokování – Jak si poradí s agresivní detekcí botů na Amazonu? (V uživatelských fórech jde o .)
- Podpora stránkování – Umí automaticky scrapovat více výsledkových stránek?
- Bezplatný plán / cena – Co vlastně dostanete bez placení? (Uživatelé se na bezplatné možnosti ptají přímo a žádný konkurent nedává praktickou odpověď.)
- Možnosti exportu – CSV, Excel, Google Sheets, Airtable, Notion?
- Plánování a automatizace – Dá se nastavit opakované spouštění?
Každé rozšíření jsem testoval na výsledcích vyhledávání Amazon US a na stránkách s detaily produktů, se stejnými dotazy a za stejných podmínek.

Scrapování s AI vs. scrapování podle selektorů: proč je to pro Amazon důležité
Je tu rozdíl, který žádný jiný přehled Amazon scraperů neřeší — a přitom je to jeden z nejdůležitějších faktorů, který určuje, kolik údržby váš scraper bude vyžadovat.
Většina rozšíření pro Chrome funguje tak, že mapuje CSS selektory na datová pole. Vy (nebo šablona nástroje) ukážete na HTML element pro „price“ nebo „title“ a scraper si vezme, co je tam zrovna teď. Problém? Amazon mění své HTML a CSS , aby scrapeři přestali fungovat. Uživatelé na fórech popisují hashované nebo proměnlivé názvy tříd jako .
Takhle vypadají tři hlavní přístupy:
| Přístup | Jak funguje | Když Amazon změní rozložení |
|---|---|---|
| Podle selektorů (tradiční) | Uživatel ručně mapuje CSS selektory na pole | Přestane fungovat — uživatel musí znovu nastavit konfiguraci |
| Na bázi šablon | Předpřipravené recepty pro stránky Amazonu | Přestane fungovat, dokud vývojář neaktualizuje šablonu |
| S podporou AI (např. Thunderbit) | AI přečte obsah stránky a automaticky rozpozná pole | Přizpůsobí se automaticky — bez údržby |
Ze sedmi rozšíření, která jsem testoval, používá jako výchozí způsob nastavení rozpoznávání polí pomocí AI jen Thunderbit. Ostatní spoléhají na selektory nebo šablony, což znamená víc údržby, až Amazon nevyhnutelně upraví své stránky. Když tenhle rozdíl pochopíte, ušetří vám to do budoucna spoustu frustrace.
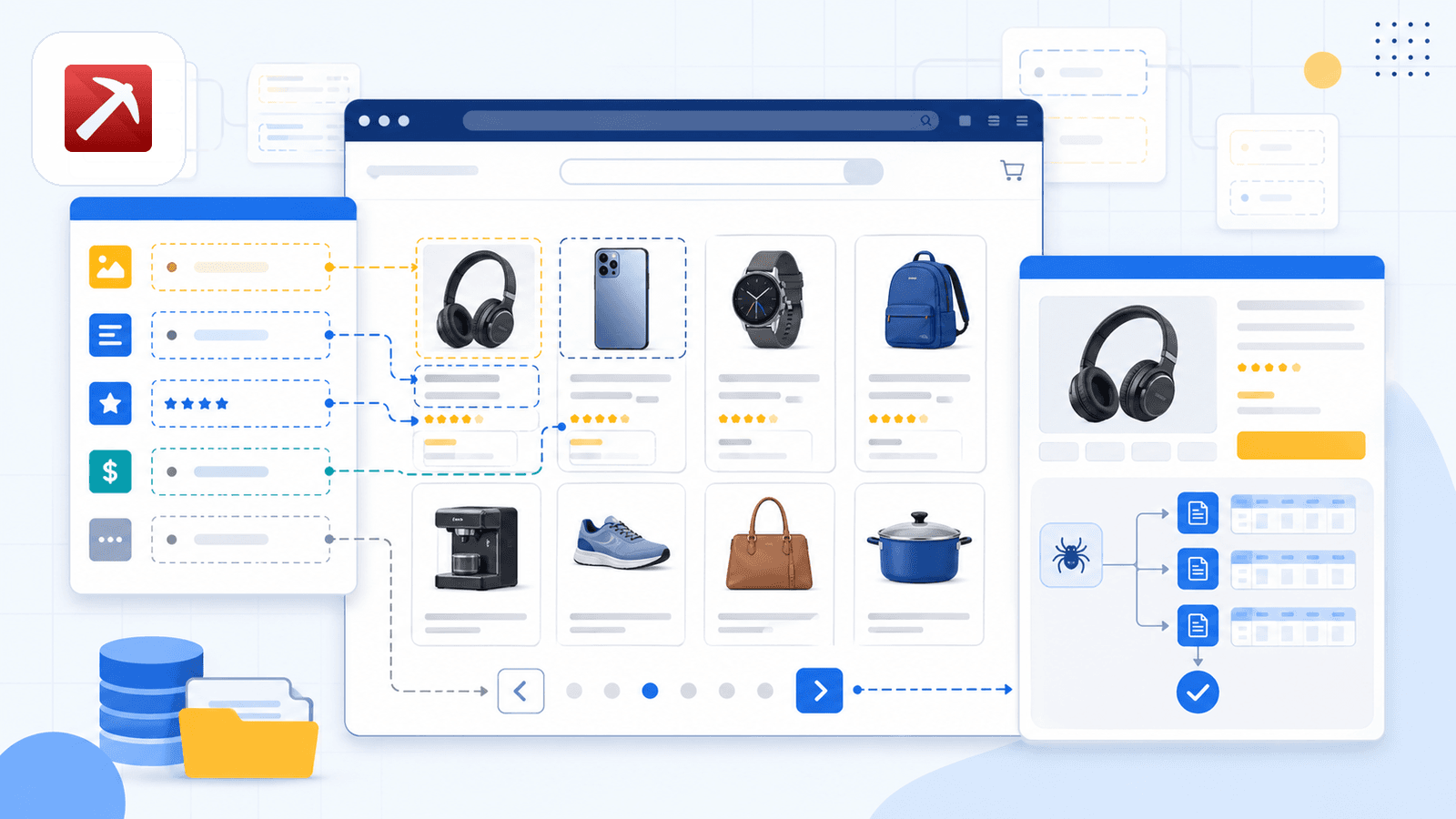
1. Thunderbit – AI-powered Amazon scraper pro Chrome
je nástroj, který jsme vyvinuli u nás ve firmě, takže to říkám na rovinu. Zároveň ale opravdu věřím, že je to nejlepší volba pro netechnické uživatele, kteří chtějí rychlá a přesná data z Amazonu bez zápasu se selektory nebo kódem.
Hlavní odlišnost je AI Suggest Fields. Když otevřete stránku s výsledky vyhledávání na Amazonu a kliknete na tlačítko, AI v Thunderbitu přečte stránku a navrhne názvy sloupců — title, price, rating, ASIN, number of reviews, product URL a další. Nic nenastavujete. AI sama pozná, co na stránce je, a navrhne správná pole i datové typy.
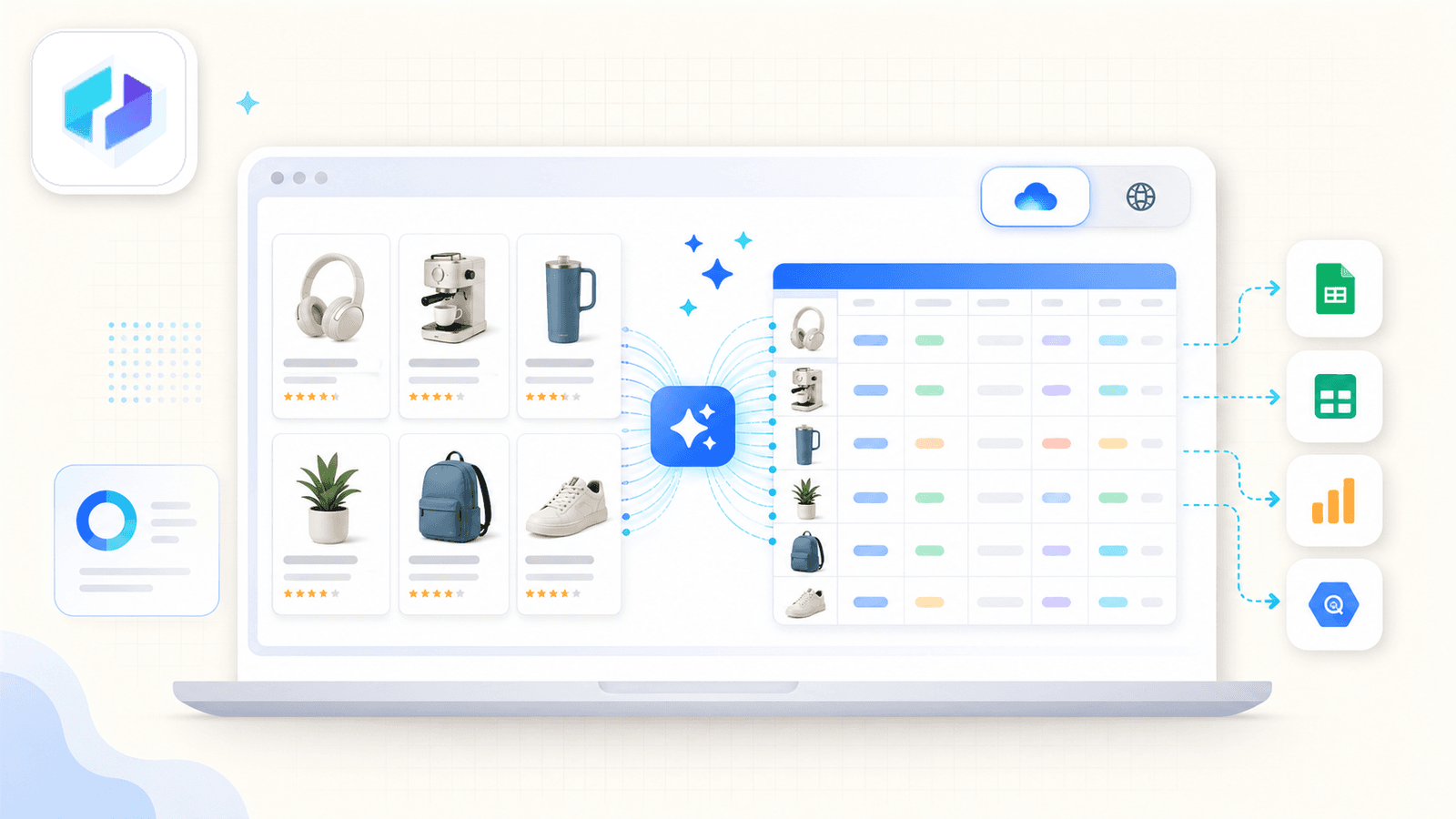
Typická session scrapování Amazonu vypadá takto:
- Nainstalujete , otevřete stránku s výsledky vyhledávání na Amazonu.
- Kliknete na AI Suggest Fields – AI rozpozná a navrhne sloupce.
- Kliknete na Scrape – data se okamžitě naplní.
- U populárních stránek Amazonu můžete použít i předpřipravenou a získat skutečný zážitek na jedno kliknutí.
To, co Thunderbit opravdu odlišuje, je scrapování podstránek. Po vytažení dat z listingové stránky kliknete na Scrape Subpages – Thunderbit navštíví každou URL produktu a připojí detailní pole (plné popisy, odrážky, informace o prodejci, URL obrázků) do stejné tabulky. Většina konkurenčních rozšíření to vůbec nenabízí.
Je tu také přepínač cloud vs. browser. Cloud režim zvládne až 50 stránek současně u veřejných listingů. Browser režim používá vaši vlastní relaci Chromu — ideální, když jste přihlášení do Seller Central nebo chcete zůstat víc „pod radarem“.
Plánování je v běžné angličtině: popíšete časový interval a AI ho převede na plán.
Možnosti exportu zahrnují Excel, Google Sheets, Airtable, Notion, CSV a JSON — vše je součástí bezplatného plánu.
Výhody a nevýhody Thunderbitu
Výhody:
- AI automaticky rozpozná pole — žádné nastavování selektorů, žádná údržba při změnách rozložení Amazonu
- Obohacení podstránek na jedno kliknutí
- Přepínání cloud/browser pro flexibilitu a nižší riziko zablokování
- Nejširší možnosti exportu (Sheets, Airtable, Notion, Excel, CSV, JSON)
- Plánování v přirozeném jazyce
- Předpřipravená Amazon šablona pro okamžité výsledky
Nevýhody:
- Kredity znamenají, že intenzivní uživatelé budou potřebovat placený plán
- Rozpoznávání polí pomocí AI přidává krátký zpracovací krok (pár sekund)
- Jde o novější nástroj, takže má méně komunitní dokumentace než starší řešení
Cena Thunderbitu
- Bezplatný plán: 6 stránek (10 s trial boostem), včetně AI funkcí a všech exportních formátů
- Placené plány: od cca 9 USD/měsíc (ročně) za 500 kreditů; 1 kredit = 1 výstupní řádek
- Aktuální informace najdete na stránce
2. Instant Data Scraper – bezplatná, jednoduchá varianta
Instant Data Scraper je rozšíření pro Chrome, které pomocí heuristických algoritmů automaticky rozpoznává tabulková data na webových stránkách. Existuje už roky a pořád patří mezi nejstahovanější bezplatné scrapery v Chrome Web Storu.
Na Amazonu rozšíření aktivujete na stránce s výsledky vyhledávání a ono se pokusí automaticky rozpoznat datovou tabulku. Někdy budete muset kliknout na „try another table“, pokud první pokus netrefí správně. Pro jednoduché jednorázové scrapování funguje docela dobře.
Pro rok 2026 je tu ale důležité upozornění: oficiální landing page nyní uvádí, že Instant Data Scraper už nevlastní, nevyvíjí ani nepodporuje Web Robots. To znamená žádné aktualizace, žádné opravy chyb a žádné nové funkce. V , že nástroj zvládl přehledové stránky, ale zasekl se ve chvíli, kdy bylo potřeba kliknout na detail.
Výhody a nevýhody Instant Data Scraperu
Výhody:
- 100% zdarma, není potřeba účet
- Lehký a rychlý pro jednoduché tabulky
- Podporuje základní stránkování (klikání na tlačítko „Next“)
Nevýhody:
- Žádné rozpoznávání polí pomocí AI (spoléhá na shodu vzorů, což může u složitého rozložení Amazonu selhat)
- Žádné scrapování podstránek
- Export jen do CSV/Excelu
- Žádné plánování, žádná cloudová varianta
- Už se neudržuje — přestává fungovat, když Amazon změní rozložení, a nikdo to neopravuje
3. Web Scraper – zkušené rozšíření pro ruční konfiguraci
Web Scraper je jeden z nejzavedenějších scraperů jako rozšíření pro Chrome a je postavený kolem vizuálního tvůrce sitemap. Otevřete DevTools, vytvoříte „sitemap“ klikáním a ukazováním pro definici selektorů, nastavíte stránkování a můžete sledovat odkazy na detailní stránky produktů.
Web Scraper také nabízí v marketplace šablonu Amazon Products Listings Scraper, která řeší navigaci, stránkování i extrakci produktových stránek. Jejich podrobný průvodce popisuje 8krokové nastavení — instalaci, generování selektorů, konfiguraci stránkování, sledování odkazů na produkty, spuštění lokálně nebo v cloudu.
Cloudová verze přidává plánování, přístup k API, rotaci proxy, obcházení CAPTCHA a integraci s Google Sheets.

Výhody a nevýhody Web Scraperu
Výhody:
- Zralý, dobře zdokumentovaný a podporovaný komunitou
- Bezplatné rozšíření pro prohlížeč (neomezené lokální použití)
- Marketplace šablony pro Amazon
- Cloudová varianta pro škálování (plánování, rotace IP, integrace)
- Umí sledovat odkazy na detailní stránky produktů (částečné obohacení podstránek)
Nevýhody:
- Vyžaduje ruční nastavení selektorů — strmější křivka učení pro netechnické uživatele
- Žádné automatické rozpoznávání polí pomocí AI
- Šablony mohou přestat fungovat po změně layoutu Amazonu
- Pokročilé funkce jsou uzamčené v placených cloudových plánech
Cena Web Scraperu
- Zdarma: rozšíření pro Chrome, neomezené lokální scrapování
- Cloud plány: od 50 USD/měsíc (Project), 100 USD/měsíc (Professional), od 200 USD/měsíc (Scale)
4. Octoparse – nástroj nabitý funkcemi s jedním háčkem u rozšíření pro Chrome
Octoparse je výkonná no-code scrapingová platforma s předpřipravenými šablonami pro Amazon pro detaily produktů, vyhledávání podle klíčových slov i recenze. Podporuje cloudové scrapování, plánování a vícekrokové workflow.
Je tu ale důležitý detail: rozšíření Octoparse v Chrome Web Storu je aktuálně uvedené jako Octoparse AI Web Automation a výslovně říká, že funguje jen spolu s Octoparse AI Botem ve Windows. Ve skutečnosti je tedy celý scrapingový zážitek primárně postavený na platformě, ne na rozšíření. Pokud hledáte čistý workflow „nainstalovat a scrapovat v Chromu“, Octoparse je spíš desktopová aplikace s pomocníkem v prohlížeči.
Šablony jsou ale výborné. Zadáte URL vyhledávání, Octoparse automaticky vytáhne data o produktech a můžete si stavět vlastní workflow pomocí point-and-click selektorů, stránkování a sledování odkazů pro detailní stránky.
Výhody a nevýhody Octoparse
Výhody:
- Silná sada funkcí s Amazon šablonami
- Cloudové uzly pro rychlost, plánování a extrakci podstránek přes workflow
- Dobrá práce se stránkováním
- Vhodné pro složité, vícekrokové scrapingové pipeline
Nevýhody:
- Plný výkon vyžaduje desktopovou aplikaci — nejde o čistý zážitek z rozšíření pro Chrome
- Žádné automatické navrhování polí pomocí AI (existuje samostatný produkt Chat4Data, ale je to jiné rozšíření)
- Bezplatný plán omezuje export na zhruba 50 tisíc datových záznamů měsíčně a 10 000 řádků na export
- Rozhraní může být pro začátečníky složité
Cena Octoparse
- Zdarma: omezeno (lokální extrakce, limit 50K exportu)
- Standard: cca 75–83 USD/měsíc
- Professional: cca 208–249 USD/měsíc
- Doplňky: rotace IP za 3 USD/GB, řešení CAPTCHA za 2–2,50 USD za 1 000
5. Axiom.ai – no-code tvůrce botů
Axiom.ai je rozšíření pro Chrome pro tvorbu automatizačních botů v prohlížeči pomocí vizuálního no-code builderu. Je to spíš univerzální nástroj pro automatizaci než vyloženě scraper, ale má šablony pro scrapování Amazonu a průvodce extrakcí ASIN.
Vytvoříte bota (nebo použijete šablonu), který prochází URL produktů v Google Sheets, navštíví každou stránku, vytáhne data pomocí point-and-click selektorů a zapíše výsledky zpět do Sheetu. Plánování je k dispozici v placených plánech a cloudové běhy jsou nyní nabízené od 1 bota v cloudu ve Starter a Pro až po 20 souběžných cloudových botů v Ultimate.
Výhody a nevýhody Axiom.ai
Výhody:
- Univerzální no-code automatizace (nejen scraping)
- Nativní integrace s Google Sheets
- Plánování a cloudové běhy v placených plánech
- Šablony pro Amazon
- Vhodné pro vícekrokové workflow nad rámec samotné extrakce dat
Nevýhody:
- Složitější nastavení pro jednoduchý scrape (vyžaduje návrh bota, konfiguraci Google Sheetu a testování smyček)
- Žádné rozpoznávání polí pomocí AI
- Žádné obohacení podstránek na jedno kliknutí (musíte vytvořit samostatný krok bota)
- Export omezený na Google Sheets nebo CSV
Cena Axiom.ai
- Zdarma: 2 hodiny běhu
- Starter: 15 USD/měsíc
- Pro: 50 USD/měsíc
- Pro Max: 150 USD/měsíc
- Ultimate: 250 USD/měsíc
6. Data Miner – rozšíření založené na receptech
Data Miner je rozšíření pro Chrome zaměřené na získávání dat pomocí „receptů“ — předdefinovaných nebo vlastních scrapingových šablon. Ve veřejné knihovně můžete najít existující Amazon recept, nebo si vytvořit vlastní výběrem prvků na stránce.
Data Miner podporuje stránkování přes funkci Next Page Automation a nabízí také workflow Crawl Scrape pro návštěvu detailních URL a použití druhého receptu. Takže to není „bez scrapování podstránek“ — ale jde o ruční vícekrokový proces, ne o obohacení na jedno kliknutí.
Hlavní omezení je bezplatný plán: 500 stránek měsíčně a některé domény jsou na free verzi omezené. Recepty jsou specifické pro konkrétní weby a vlastní dokumentace Data Mineru upozorňuje, že pokud se web změní a změní se referenční HTML kód, recept přestane fungovat.
Výhody a nevýhody Data Mineru
Výhody:
- Snadné spuštění existujícího receptu
- Knihovna komunitních receptů
- Podporuje stránkování i crawl detailních stránek (ruční nastavení)
- Jednoduché rozhraní
Nevýhody:
- Bezplatný plán je omezený na 500 stránek/měsíc
- Žádné rozpoznávání polí pomocí AI
- Recepty přestávají fungovat po změně layoutu Amazonu
- Žádné cloudové scrapování, žádné plánování ve veřejných dokumentech
- Export: CSV, Excel, clipboard; Google Sheets jen v placených plánech
Cena Data Mineru
- Zdarma: 500 stránek/měsíc
- Placené: 19,99, 49, 99, 200 USD/měsíc s rostoucími limity a funkcemi
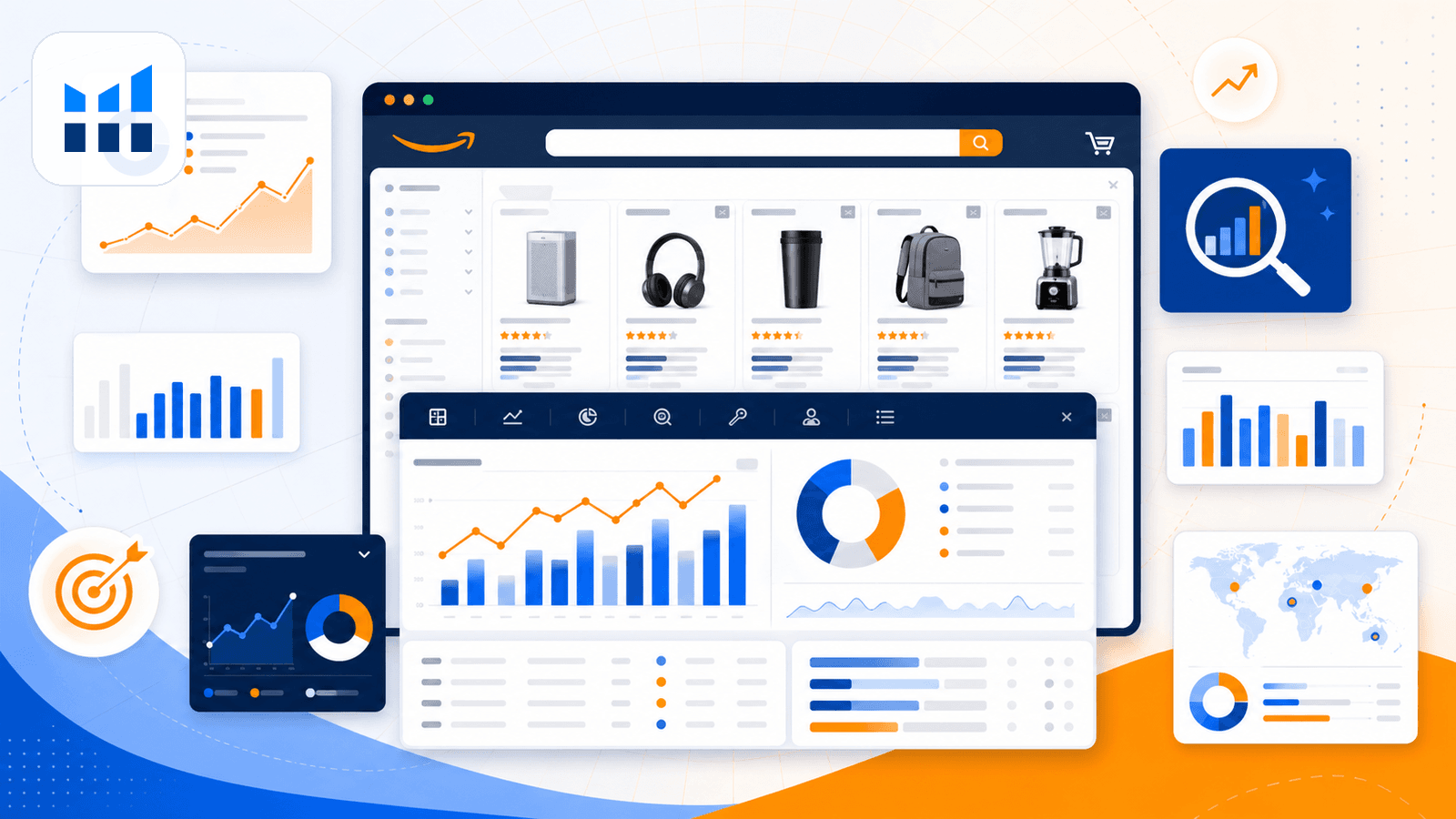
7. Helium 10 – sada nástrojů pro Amazon seller intelligence
Helium 10 je komplexní sada nástrojů pro prodejce na Amazonu, ne univerzální web scraper. Jeho rozšíření pro Chrome (Xray) zobrazuje data přímo nad výsledky vyhledávání na Amazonu — odhadovaný prodej, tržby, trendy recenzí, BSR a další. Je určené pro prodejce, kteří dělají produktový výzkum, ne pro extrakci syrových dat ze stránky.
Helium 10 má v roce 2026 i bezplatný plán, ale přístup k rozšíření pro Chrome je na free verzi omezený. Rozšíření umí exportovat výsledky do CSV nebo Excelu a podporuje i práci přes clipboard.
Výhody a nevýhody Helium 10
Výhody:
- Hluboké poznatky specifické pro Amazon (odhad prodejů, data o klíčových slovech, trendy BSR)
- Důvěřují mu profesionální prodejci
- Data a plánování v cloudu pro sledování klíčových slov a pozic
- K dispozici bezplatný plán (omezený)
Nevýhody:
- Není to obecný scraper — neumí z libovolných stránek vytahovat vlastní datová pole
- Drahý ve srovnání s nástroji zaměřenými na scraping
- Omezené exportní formáty (CSV, Excel)
- Žádné rozpoznávání polí pomocí AI, žádné obohacení podstránek ve smyslu scrapování
Cena Helium 10
- Zdarma: omezený přístup včetně rozšíření pro Chrome
- Starter: 49 USD/měsíc
- Platinum: 229 USD/měsíc
- Diamond: 359 USD/měsíc
Srovnání Amazon scraperů pro Chrome: kompletní přehled vedle sebe
Tady je poctivé srovnání. Po praktickém testování a ověření v roce 2026 jsem opravil několik předpokladů z dřívějších verzí:
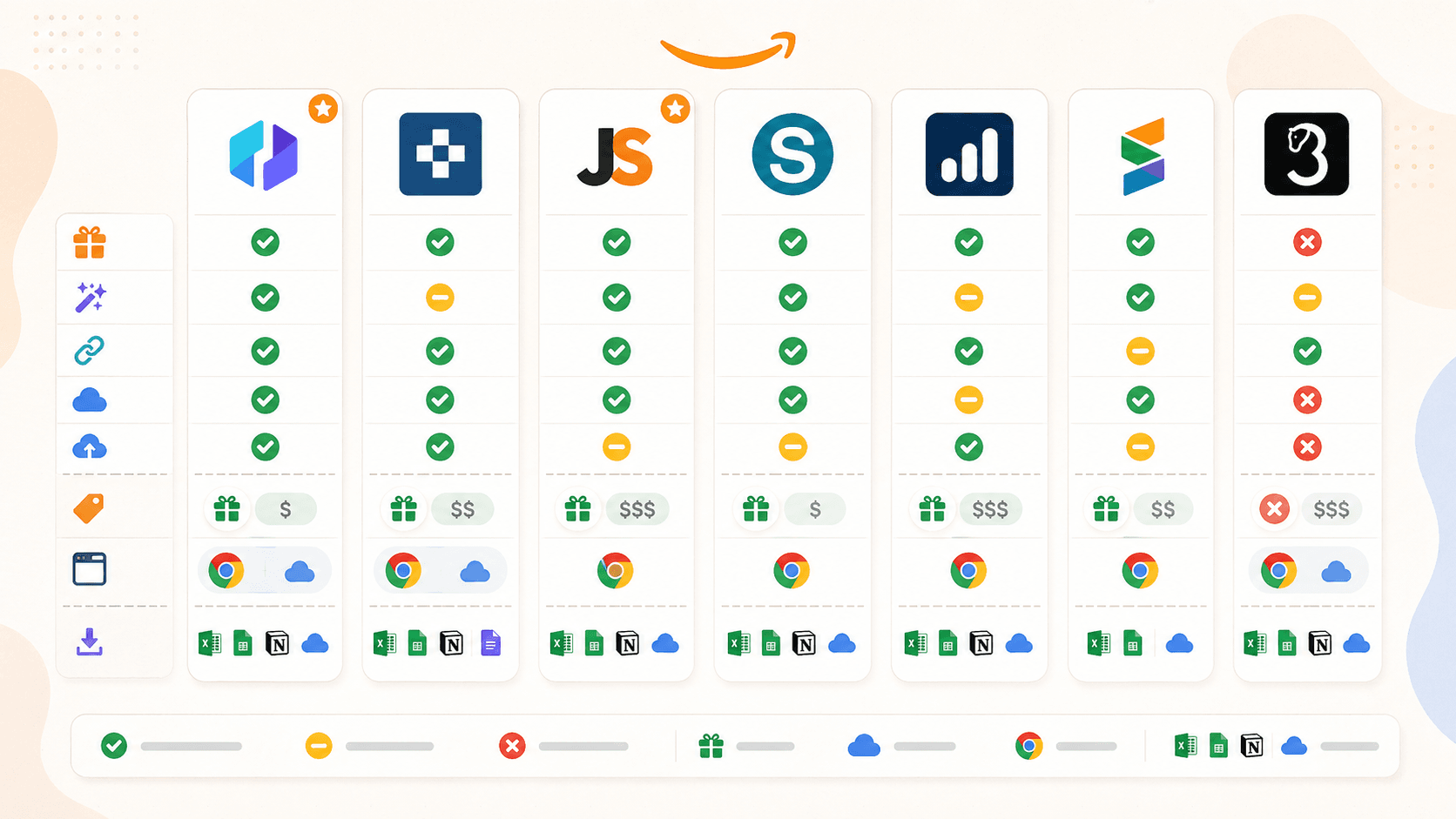
| Funkce | Thunderbit | Instant Data Scraper | Web Scraper | Octoparse | Axiom.ai | Data Miner | Helium 10 |
|---|---|---|---|---|---|---|---|
| Hlavní kategorie | AI scraper extension | Bezplatný heuristický scraper | Scraper podle selektorů / šablon | No-code scrapingová platforma | Tvůrce automatizačních botů v prohlížeči | Scraper založený na receptech | Překryvná vrstva pro research prodejců |
| AI navrhování polí | Ano | Ne | Ne | Ne (samostatný Chat4Data) | Ne | Ne | Ne |
| Obohacení podstránek | Ano (1 kliknutí) | Ne | Ano (ruční sitemap) | Ano (workflow) | Ano (ruční krok bota) | Ano (ruční crawl) | N/A |
| Cloudové scrapování | Ano | Ne | Ano (placené) | Ano (placené) | Ano (placené) | Ne | Analytics v cloudu |
| Plánování | Ano | Ne | Ano (placené) | Ano (placené) | Ano (placené) | Ne | Ano (sledování klíčových slov / pozic) |
| Bezplatný plán | Ano (6–10 stránek) | Ano (zcela zdarma) | Ano (jen v prohlížeči) | Ano (omezený) | Ano (2 hodiny běhu) | Ano (500 stránek/měsíc) | Ano (omezený) |
| Předpřipravená Amazon šablona | Ano | Ne | Ano | Ano | Ano (průvodce) | Knihovna receptů | N/A |
| Export do Sheets/Airtable/Notion | Ano (vše) | Pouze CSV/Excel | CSV, Excel, JSON; Sheets přes cloud | CSV, Excel, JSON, více | Google Sheets, CSV | CSV, Excel; Sheets v placených plánech | CSV, Excel |
Je z toho patrných pár věcí. Thunderbit je jediné rozšíření s rozpoznáváním polí pomocí AI a s nejširšími možnostmi exportu v bezplatném plánu. Instant Data Scraper je nejjednodušší bezplatná možnost, ale už se neudržuje. Web Scraper a Octoparse jsou silné pro uživatele, kteří jsou ochotní investovat čas do nastavení, ale ani jeden z nich není čistý zážitek „nainstalovat a používat“ v rozšíření. Axiom.ai je nejlepší pro vícekrokovou automatizaci nad rámec scrapování. Data Miner je snadný pro používání existujících receptů, ale bezplatný plán je dost napjatý. Helium 10 je nástroj pro seller intelligence, ne obecný scraper.
Cloud vs. scrapování v prohlížeči na Amazonu: co potřebujete vědět o riziku zablokování
Tohle je slon v místnosti. Amazon aktivně detekuje a blokuje automatizované scrapování. Uživatelé na Redditu hlásí a vlastní Amazonu výslovně říkají, že licence nezahrnuje „jakékoli použití data miningu, robotů nebo podobných nástrojů pro sběr a extrakci dat“.
Jaký je tedy praktický rozdíl mezi scrapováním v prohlížeči a v cloudu?
- Scrapování v prohlížeči běží ve vaší vlastní relaci Chromu — skutečné cookies, přihlášený stav, přirozené chování při prohlížení. Při malém objemu působí lidskyji, ale zatěžuje váš prohlížeč.
- Cloudové scrapování používá vzdálené servery pro rychlost (Thunderbit zvládá v cloud režimu 50 stránek najednou), ale kvůli detekci je potřeba omezování rychlosti a rotace proxy.
Takhle vypadá moje rozhodovací matice:
| Situace | Doporučený režim | Proč |
|---|---|---|
| Scrapování 20 produktových stránek pro výzkum | Prohlížeč | Nízký objem, přirozené chování |
| Sledování 500 konkurenčních SKU týdně | Cloud | Záleží na rychlosti, veřejná data |
| Scrapování při přihlášení do Seller Central | Prohlížeč | Potřebujete vlastní přihlašovací relaci |
| Jednorázový hromadný export kategorie | Cloud | Paralelní scrapování pro vyšší rychlost |
Ze sedmi testovaných rozšíření je cloudové scrapování dostupné v Thunderbitu, Web Scraperu (placeně), Octoparse (placeně), Axiom.ai (placeně) a Helium 10 (pro analytiku). Instant Data Scraper a Data Miner fungují jen v prohlížeči.
Praktické tipy, jak snížit riziko zablokování: Dodržujte rozumné intervaly požadavků, nescrapujte ve špičce a pokud to nástroj podporuje, rotujte user agenty. A nikdy si neslibujte „nulové riziko“ — jen ho řiďte.
Od listingové stránky k detailu produktu: jak funguje scrapování podstránek na Amazonu
Tenhle workflow se podceňuje — a žádný konkurenční článek ho neukazuje od začátku do konce.
Když scrapujete stránku s výsledky vyhledávání Amazonu, dostanete souhrnná data: názvy produktů, ceny, hodnocení, ASIN a URL produktů. Ale často potřebujete i data z detailní stránky — plné popisy, odrážky, URL obrázků, informace o prodejci, rozpad recenzí. A právě tady přichází na řadu scrapování podstránek.
V Thunderbitu workflow vypadá takto:
- Scrapujete stránku s výsledky vyhledávání Amazonu -> získáte tabulku produktů (název, cena, hodnocení, ASIN, URL produktu).
- Kliknete na „Scrape Subpages“ -> Thunderbit navštíví každou URL produktu a připojí detailní pole (popis, počet recenzí, jméno prodejce, URL obrázků atd.) do stejné tabulky.
- Exportujete obohacenou tabulku do Google Sheets, Airtable, Notion nebo Excelu.
AI rozpozná strukturu podstránky a tabulku automaticky obohatí — bez ruční konfigurace. Z mé zkušenosti to u každé dávky ušetří minimálně hodinu oproti tomu, když byste museli každou produktovou stránku otevírat a pole kopírovat ručně.
I ostatní nástroje to umí, ale s větší námahou:
- Web Scraper: nakonfigurujete sitemapu tak, aby sledovala odkazy na produkty, a pro každé detailní pole definujete selektory. Funguje to, ale jde o vícekrokový ruční proces.
- Octoparse: sestavíte workflow s kroky pro sledování odkazů. Silné, ale ne na jedno kliknutí.
- Axiom.ai: navrhnete smyčku bota, která navštíví každou URL a vytáhne data. Flexibilní, ale vyžaduje dovednosti v tvorbě botů.
- Data Miner: použijete funkci Crawl Scrape pro návštěvu uložených URL a aplikujete druhý recept. Ruční a závislé na receptu.
- Instant Data Scraper a Helium 10: workflow pro obohacení podstránek nenabízejí.
Pokud pravidelně potřebujete jak data na úrovni listingů, tak data na úrovni detailů, měl by vám vybraný nástroj tenhle workflow maximálně zjednodušit — ne jen umožnit.
Upřímný rozpad bezplatných plánů: co skutečně dostanete bez placení
Na to se ve fórech ptají nejčastěji, a žádný konkurenční článek to neodpovídá transparentně.
| Rozšíření | Bezplatný plán | Co zdarma získáte | Kdy je potřeba přejít na vyšší plán |
|---|---|---|---|
| Thunderbit | Ano (6 stránek, 10 s trialem) | Navrhování polí pomocí AI, všechny exportní formáty (Excel, Sheets, Airtable, Notion), extraktory e-mailů/telefonů | Potřebujete více stránek nebo plánované scrapování |
| Instant Data Scraper | Ano (zcela zdarma) | Základní rozpoznávání tabulek, export CSV/Excel | N/A (není placený plán, ale ani aktualizace) |
| Web Scraper | Ano (jen v prohlížeči) | Scrapování v prohlížeči, export CSV | Cloudové scrapování, plánování, integrace |
| Octoparse | Ano (omezeně) | ~50K exportu/měsíc, lokální extrakce | Více záznamů, cloudové uzly |
| Axiom.ai | Ano (2 hodiny běhu) | Základní automatizace, Google Sheets | Více spuštění, plánování, cloud |
| Data Miner | Ano (500 stránek/měsíc) | Recepty, CSV/Excel, Next Page Automation | Více stránek, Sheets, crawl funkce |
| Helium 10 | Ano (omezeně) | Omezený přístup k Chrome Extension | Plný Xray, nástroje pro klíčová slova, plánování |
Klíčový poznatek: bezplatný plán Thunderbitu zahrnuje funkce AI i všechny exportní formáty — většina konkurence zamyká pokročilé exporty nebo AI do placených tarifů. Instant Data Scraper je úplně zdarma, ale chybí mu AI, podstránky a plánování (a už se neudržuje). Helium 10 sice bezplatný plán má, ale přístup k rozšíření je omezený a nejde o obecný scraper.
Moje doporučení podle situace:
- „Jen zkouším, co to umí“ -> Instant Data Scraper (zcela zdarma) nebo bezplatný plán Thunderbitu
- „Potřebuji pravidelné a spolehlivé scrapování“ -> placené plány Thunderbitu nebo Web Scraperu
- „Prodávající na Amazonu, který potřebuje tržní inteligenci“ -> Helium 10
Které rozšíření pro Chrome na Amazon scraper si vybrat?
Po otestování všech sedmi je moje upřímné shrnutí toto:
- Nejlepší pro netechnické uživatele, kteří chtějí rychlé výsledky s AI: Thunderbit. AI automaticky rozpozná pole, obohacení podstránek na jedno kliknutí, nejširší možnosti exportu, přepínání cloud/browser. Pokud chcete přejít z Amazon stránky do tabulky za méně než dvě minuty, tohle je moje volba.
- Nejlepší plně bezplatná volba pro rychlé jednorázové scrapování: Instant Data Scraper. Bez nákladů, bez účtu, ale s omezenými funkcemi a bez další údržby.
- Nejlepší pro uživatele, kteří zvládnou ruční konfiguraci: Web Scraper. Flexibilní tvůrce sitemap, dobrá cloudová varianta, dobře zdokumentované.
- Nejlepší pro složité vícekrokové scrapingové pipeline: Octoparse (desktop + rozšíření) nebo Axiom.ai (boty v prohlížeči). Oba nástroje jsou silné, ale ani jeden není čisté „nainstalovat a používat“ rozšíření pro Chrome.
- Nejlepší pro jednoduchou extrakci na základě receptů: Data Miner. Snadné používání existujících receptů, ale omezený bezplatný plán a žádná AI.
- Nejlepší pro Amazon seller intelligence, ne pro obecné scrapování: Helium 10. Nástroj dělaný na míru, hluboká proprietární data, ale drahý a není to obecný scraper.
Pokud chcete vidět, jak AI-powered Amazon scraping skutečně vypadá, . Myslím, že budete překvapeni, kolik toho zvládnete během pár kliknutí. A pokud Thunderbit není úplně to pravé, vyzkoušejte i pár dalších nástrojů z tohohle seznamu — nikdy nebyla lepší doba přestat kopírovat a vkládat a začít scrapovat chytřeji.
Další tipy k scrapování Amazonu najdete v našich průvodcích: , a . Můžete se také podívat na návody na .
Časté dotazy
1. Je scrapování dat o produktech z Amazonu legální?
Scrapování veřejně viditelných dat je obecně přípustné, ale Amazon ve svých výslovně zakazuje data mining a automatizovanou extrakci bez písemného souhlasu. Tenhle článek nepředstavuje právní radu — před scrapováním ve větším měřítku si vždy zkontrolujte podmínky Amazonu.
2. Dokáže Amazon detekovat a blokovat scrapeři jako rozšíření pro Chrome?
Ano. Amazon má anti-bot systémy, které mohou spustit CAPTCHA, omezit počet požadavků nebo blokovat IP adresy. Riziko lze snížit rozumnou rychlostí požadavků, scrapováním v prohlížeči pro menší úlohy a cloudovým scrapováním s omezováním rychlosti pro větší úlohy. Praktickou rozhodovací matici najdete výše v části o cloudu vs. prohlížeči.
3. Jaká data můžete z Amazonu přes rozšíření pro Chrome scrapovat?
Mezi běžná pole patří názvy produktů, ceny, hodnocení, počet recenzí, ASIN, jména prodejců, popisy, URL obrázků, dostupnost a informace o dopravě. Nástroje s AI, jako je Thunderbit, dokážou tato pole automaticky rozpoznat a navrhnout bez ručního nastavování.
4. Potřebuji programátorské znalosti, abych mohl používat rozšíření pro Chrome na Amazon scraper?
Ne — všech sedm testovaných nástrojů je navržených pro netechnické uživatele. Některé vyžadují víc nastavení (Web Scraper, Octoparse, Axiom.ai), zatímco jiné jsou téměř bez konfigurace (Thunderbit, Instant Data Scraper). Kompromis je obvykle mezi flexibilitou a snadností použití.
5. Které rozšíření pro Chrome na Amazon scraper má nejlepší bezplatný plán?
Bezplatný plán Thunderbitu zahrnuje rozpoznávání polí pomocí AI a všechny exportní formáty (Sheets, Airtable, Notion, Excel, CSV, JSON), které většina konkurence zamyká do placených plánů. Instant Data Scraper je úplně zdarma, ale postrádá AI, podstránky a plánování. Data Miner nabízí 500 bezplatných stránek měsíčně. Bezplatný plán Helium 10 je omezený a zaměřený na research prodejců, ne na obecné scrapování.
Zjistit více