
Buďme upřímní — Amazon je v podstatě nákupní centrum, supermarket i obchod s elektronikou pro celý internet. Pokud pracujete v prodeji, e-commerce nebo operations, už víte, že to, co se děje na Amazonu, nezůstává jen na Amazonu — ovlivňuje to vaše ceny, zásoby a dokonce i váš další velký produktový launch. Jenže háček je v tom, že všechny ty lákavé produktové detaily, ceny, hodnocení a recenze jsou schované za webovým rozhraním navrženým pro nakupující, ne pro týmy lačné po datech. Jak se tedy k těmto datům dostat, aniž byste trávili víkendy kopírováním a vkládáním, jako bychom byli v roce 1999?
A právě tady přichází ke slovu web scraping. V tomhle průvodci vám ukážu dva způsoby, jak získat produktová data z Amazonu: klasický přístup „vyhrnout si rukávy a naprogramovat to v Pythonu“ a moderní cestu „nechte těžkou práci na AI“ s no-code web scraperem, jako je . Provedu vás skutečným Python kódem (včetně všech záseků a obcházek) a pak ukážu, jak vám Thunderbit dostane stejná data během pár kliknutí — bez programování. Ať už jste vývojář, business analytik, nebo prostě někdo, koho už nebaví ruční zadávání dat, máte to tu pokryté.
Proč získávat produktová data z Amazonu? (amazon scraper python, web scraping with python)
Amazon není jen největší internetový prodejce na světě — je to také největší otevřené tržiště pro konkurenční inteligenci. S a je Amazon zlatý důl pro každého, kdo chce:

- Sledovat ceny (a upravovat své v reálném čase)
- Analyzovat konkurenci (sledovat nové produkty, hodnocení a recenze)
- Generovat leady (najít prodejce, dodavatele nebo potenciální partnery)
- Předpovídat poptávku (sledováním skladových zásob a prodejních ranků)
- Odhalovat trendy na trhu (analýzou recenzí a výsledků vyhledávání)
A nejde jen o teorii — skutečné firmy vidí skutečnou návratnost. Například jeden prodejce elektroniky využil seškrábaná cenová data z Amazonu ke , zatímco jiná značka zaznamenala poté, co automatizovala sledování cen konkurence.
Tady je rychlá tabulka use casů a toho, jakou návratnost můžete čekat:
| Use Case | Kdo to používá | Typická návratnost / přínos |
|---|---|---|
| Sledování cen | E-commerce, operations | Zvýšení marže o 15 %+, růst prodeje o 4 %, o 30 % méně času analytiků |
| Analýza konkurence | Prodej, produkt, operations | Rychlejší úpravy cen, lepší konkurenceschopnost |
| Průzkum trhu (recenze) | Produkt, marketing | Rychlejší iterace produktu, lepší reklamní texty, SEO poznatky |
| Generování leadů | Prodej | 3 000+ leadů/měsíc, úspora 8+ hodin na obchodního zástupce týdně |
| Předpověď zásob a poptávky | Operations, dodavatelský řetězec | O 20 % méně nadzásob, méně výpadků zásob |
| Sledování trendů | Marketing, vedení | Včasné odhalení žhavých produktů a kategorií |
A tady je ten zásadní fakt: dnes hlásí měřitelnou hodnotu z datové analytiky. Pokud Amazon nescrapujete, necháváte poznatky — a peníze — ležet ladem.
Přehled: Amazon Scraper Python vs. no-code web scraper nástroje
Jsou dvě hlavní cesty, jak dostat data z Amazonu z prohlížeče do tabulek nebo dashboardů:
-
Amazon Scraper Python (web scraping with python):
Napíšete si vlastní skript pomocí Python knihoven jako Requests a BeautifulSoup. Máte plnou kontrolu, ale musíte umět programovat, vypořádat se s anti-bot opatřeními a průběžně skript udržovat, jakmile Amazon změní web.
-
No-code web scraper nástroje (jako Thunderbit):
Použijete nástroj, ve kterém data jednoduše ukazujete, klikáte a extrahujete — bez nutnosti programování. Moderní nástroje jako navíc využívají AI, která sama rozpozná, jaká data máte stáhnout, zvládnou podstránky i stránkování a exportují rovnou do Excelu nebo Google Sheets.
Takhle to vypadá vedle sebe:
| Kritérium | Python scraper | No-code (Thunderbit) |
|---|---|---|
| Čas na nastavení | Vysoký (instalace, kód, ladění) | Nízký (instalace rozšíření) |
| Potřebné dovednosti | Nutné programování | Žádné (point & click) |
| Flexibilita | Neomezená | Vysoká pro běžné use casy |
| Údržba | Kód opravujete vy | Nástroj se aktualizuje sám |
| Anti-bot ochrana | Proxy a hlavičky řešíte vy | Vestavěná, vyřešená za vás |
| Škálovatelnost | Ručně (vlákna, proxy) | Cloud scraping, paralelizace |
| Export dat | Na míru (CSV, Excel, DB) | Jedním kliknutím do Excelu, Sheets |
| Cena | Zdarma (váš čas + proxy) | Freemium, platba za škálování |
V dalších částech vás provedu oběma přístupy — nejdřív tím, jak postavit Amazon scraper v Pythonu (s reálným kódem), a pak tím, jak stejnou věc udělat s AI web scraperem od Thunderbitu.
Začínáme s Amazon Scraper Python: předpoklady a nastavení
Než se ponoříme do kódu, nastavme si prostředí.
Budete potřebovat:
- Python 3.x (stáhněte z )
- Editor kódu (já mám rád VS Code, ale funguje cokoli)
- Tyto knihovny:
requests(pro HTTP požadavky)beautifulsoup4(pro parsování HTML)lxml(rychlý HTML parser)pandas(pro datové tabulky/export)re(regulární výrazy, vestavěné)
Instalace knihoven:
1pip install requests beautifulsoup4 lxml pandasNastavení projektu:
- Vytvořte si novou složku pro projekt.
- Otevřete editor, vytvořte nový Python soubor (např.
amazon_scraper.py). - A můžete začít!
Krok za krokem: Web scraping v Pythonu pro produktová data z Amazonu
Podívejme se na scrapování jedné produktové stránky na Amazonu. (Nebojte, za chvíli se dostaneme i k více produktům a stránkám.)
1. Odeslání požadavků a stažení HTML
Nejdřív stáhněme HTML produktové stránky. (URL nahraďte libovolným produktem na Amazonu.)
1import requests
2url = "<https://www.amazon.com/dp/B0ExampleASIN>"
3response = requests.get(url)
4html_content = response.text
5print(response.status_code)Pozor: Tenhle základní požadavek Amazon pravděpodobně zablokuje. Místo produktové stránky můžete vidět chybu 503 nebo CAPTCHA. Proč? Protože Amazon ví, že nejste skutečný prohlížeč.
Jak obejít anti-bot opatření Amazonu
Amazon nemá boty rád. Abyste se vyhnuli blokaci, budete muset:
- Nastavit hlavičku User-Agent (předstírat, že jste Chrome nebo Firefox)
- Střídat User-Agenty (nepoužívat pořád stejný)
- Zpomalit požadavky (přidávat náhodná zpoždění)
- Používat proxy (pro scraping ve velkém)
Takhle nastavíte hlavičky:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)... Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9",
4}
5response = requests.get(url, headers=headers)Chcete to povýšit? Použijte seznam User-Agentů a střídejte je při každém požadavku. U větších úloh budete chtít proxy službu (je jich spousta), ale pro menší scraping obvykle stačí hlavičky a prodlevy.
Extrakce hlavních produktových polí
Jakmile máte HTML, je čas ho rozparsovat pomocí BeautifulSoup.
1from bs4 import BeautifulSoup
2soup = BeautifulSoup(html_content, "lxml")Teď vytáhněme důležité údaje:
Název produktu
1title_elem = soup.find(id="productTitle")
2product_title = title_elem.get_text(strip=True) if title_elem else NoneCena
Cena na Amazonu může být na několika místech. Zkuste toto:
1price = None
2price_elem = soup.find(id="priceblock_ourprice") or soup.find(id="priceblock_dealprice")
3if price_elem:
4 price = price_elem.get_text(strip=True)
5else:
6 price_whole = soup.find("span", {"class": "a-price-whole"})
7 price_frac = soup.find("span", {"class": "a-price-fraction"})
8 if price_whole and price_frac:
9 price = price_whole.text + price_frac.textHodnocení a počet recenzí
1rating_elem = soup.find("span", {"class": "a-icon-alt"})
2rating = rating_elem.get_text(strip=True) if rating_elem else None
3review_count_elem = soup.find(id="acrCustomerReviewText")
4reviews_text = review_count_elem.get_text(strip=True) if review_count_elem else ""
5reviews_count = reviews_text.split()[0] # např. "1,554 ratings"URL hlavního obrázku
Amazon někdy schovává obrázky ve vysokém rozlišení v JSON přímo v HTML. Tady je rychlý přístup přes regulární výraz:
1import re
2match = re.search(r'"hiRes":"(https://.*?.jpg)"', html_content)
3main_image_url = match.group(1) if match else NoneNebo vezměte hlavní img tag:
1img_tag = soup.find("img", {"id": "landingImage"})
2img_url = img_tag['src'] if img_tag else NoneDetaily produktu
Specifikace jako značka, hmotnost a rozměry bývají většinou v tabulce:
1details = {}
2rows = soup.select("#productDetails_techSpec_section_1 tr")
3for row in rows:
4 header = row.find("th").get_text(strip=True)
5 value = row.find("td").get_text(strip=True)
6 details[header] = valueNebo pokud Amazon používá formát „detailBullets“:
1bullets = soup.select("#detailBullets_feature_div li")
2for li in bullets:
3 txt = li.get_text(" ", strip=True)
4 if ":" in txt:
5 key, val = txt.split(":", 1)
6 details[key.strip()] = val.strip()Výsledek vypište:
1print("Title:", product_title)
2print("Price:", price)
3print("Rating:", rating, "based on", reviews_count, "reviews")
4print("Main image URL:", main_image_url)
5print("Details:", details)Scrapování více produktů a práce se stránkováním
Jeden produkt je fajn, ale pravděpodobně budete chtít celý seznam. Tady je, jak scrapovat výsledky vyhledávání a více stránek.
Získání odkazů na produkty z výsledkové stránky
1search_url = "<https://www.amazon.com/s?k=bluetooth+headphones>"
2res = requests.get(search_url, headers=headers)
3soup = BeautifulSoup(res.text, "lxml")
4product_links = []
5for a in soup.select("h2 a.a-link-normal"):
6 href = a['href']
7 full_url = "<https://www.amazon.com>" + href
8 product_links.append(full_url)Zpracování stránkování
Vyhledávací URL na Amazonu používají &page=2, &page=3 atd.
1for page in range(1, 6): # scrape first 5 pages
2 search_url = f"<https://www.amazon.com/s?k=bluetooth+headphones&page={page}>"
3 res = requests.get(search_url, headers=headers)
4 if res.status_code != 200:
5 break
6 soup = BeautifulSoup(res.text, "lxml")
7 # ... extract product links as above ...Průchod produktovými stránkami a export do CSV
Shromážděte produktová data do seznamu slovníků a pak použijte pandas:
1import pandas as pd
2df = pd.DataFrame(product_data_list) # list of dicts
3df.to_csv("amazon_products.csv", index=False)Nebo do Excelu:
1df.to_excel("amazon_products.xlsx", index=False)Nejlepší postupy pro projekty Amazon Scraper Python
Buďme realisté — Amazon neustále mění svůj web a bojuje proti scraperům. Takhle udržíte projekt v provozu:
- Střídejte hlavičky a User-Agenty (použijte knihovnu jako
fake-useragent) - Používejte proxy pro scraping ve velkém
- Zpomalujte požadavky (náhodné
time.sleep()mezi požadavky) - Ošetřujte chyby elegantně (opakujte požadavek při 503, ustupte, pokud jste blokováni)
- Pište flexibilní parsovací logiku (u každého pole hledejte více selektorů)
- Sledujte změny HTML (když skript najednou vrací u všeho
None, zkontrolujte stránku) - Respektujte robots.txt (Amazon zakazuje scraping mnoha sekcí — scrapujte zodpovědně)
- Čistěte data průběžně (odstraňte symboly měny, čárky a mezery)
- Buďte v kontaktu s komunitou (fóra, Stack Overflow, Reddit r/webscraping)
Checklist pro údržbu scraperu:
- [ ] Střídat User-Agenty a hlavičky
- [ ] Používat proxy při scrapování ve velkém
- [ ] Přidávat náhodná zpoždění
- [ ] Rozdělit kód do modulů pro snadné aktualizace
- [ ] Sledovat blokace nebo CAPTCHA
- [ ] Pravidelně exportovat data
- [ ] Dokumentovat selektory a logiku
Pro hlubší ponor se podívejte na můj .
No-code alternativa: scrapování Amazonu s Thunderbit AI Web Scraperem
Dobře, takže jste viděli Python cestu. Ale co když nechcete programovat — nebo prostě chcete dostat data na dvě kliknutí a jít dál se životem? Právě tady přichází na řadu .
Thunderbit je Chrome rozšíření s AI web scraperem, které vám umožní extrahovat produktová data z Amazonu (i z prakticky jakéhokoli webu) bez kódu. Tady je, proč ho mám rád:
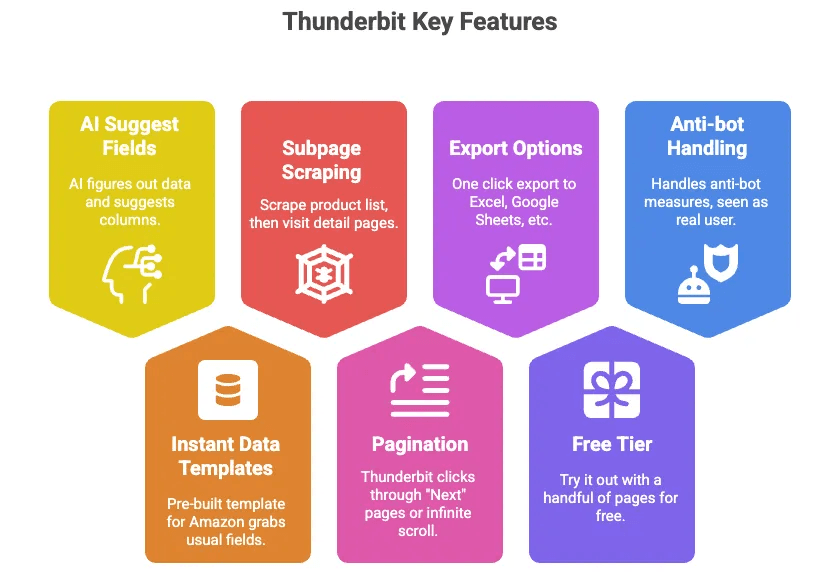
- AI navrhování polí: Stačí kliknout na tlačítko a AI od Thunderbitu zjistí, jaká data jsou na stránce, a navrhne sloupce (např. Název, Cena, Hodnocení atd.).
- Okamžité datové šablony: Pro Amazon je připravená šablona, která stáhne všechna běžná pole — bez nastavování.
- Scraping podstránek: Seberte seznam produktů a pak nechte Thunderbit navštívit detail každého produktu a automaticky vytáhnout víc informací.
- Stránkování: Thunderbit za vás prokliká „Další“ stránky nebo infinite scroll.
- Export do Excelu, Google Sheets, Airtable, Notion: Jedním kliknutím máte data připravená k použití.
- Bezplatná verze: Vyzkoušejte si ho zdarma na několika stránkách.
- Zvládá anti-bot věci za vás: Protože běží ve vašem prohlížeči (nebo v cloudu), Amazon ho vidí jako skutečného uživatele.
Krok za krokem: Jak použít Thunderbit ke scrapování produktových dat z Amazonu
Je to až směšně snadné:
-
Nainstalujte Thunderbit:
Stáhněte si a přihlaste se.
-
Otevřete Amazon:
Přejděte na stránku Amazonu, kterou chcete scrapovat (výsledky vyhledávání, detail produktu, cokoli).
-
Klikněte na „AI Suggest Fields“ nebo použijte šablonu:
Thunderbit navrhne sloupce k extrakci (nebo si můžete vybrat šablonu Amazon Product).
-
Zkontrolujte sloupce:
Podle potřeby je upravte (přidejte/odeberte pole, přejmenujte je atd.).
-
Klikněte na „Scrape“:
Thunderbit stáhne data ze stránky a zobrazí je v tabulce.
-
Zvládněte podstránky a stránkování:
Pokud jste scrapovali seznam, klikněte na „Scrape Subpages“ a Thunderbit navštíví detail každého produktu a vytáhne více informací. Umí také automaticky proklikávat „Další“ stránky.
-
Exportujte data:
Klikněte na „Export to Excel“ nebo „Export to Google Sheets“. Hotovo.
-
(Volitelné) Naplánujte scraping:
Potřebujete tahle data každý den? Použijte plánovač Thunderbitu a automatizujte to.
To je všechno. Žádný kód, žádné ladění, žádné proxy, žádné bolesti hlavy. Pro vizuální návod se podívejte na nebo na .
Amazon Scraper Python vs. no-code web scraper: srovnání vedle sebe
Dejme to všechno dohromady:
| Kritérium | Python scraper | Thunderbit (no code) |
|---|---|---|
| Čas na nastavení | Vysoký (instalace, kód, ladění) | Nízký (instalace rozšíření) |
| Potřebné dovednosti | Nutné programování | Žádné (point & click) |
| Flexibilita | Neomezená | Vysoká pro běžné use casy |
| Údržba | Kód opravujete vy | Nástroj se aktualizuje sám |
| Anti-bot ochrana | Proxy a hlavičky řešíte vy | Vestavěná, vyřešená za vás |
| Škálovatelnost | Ručně (vlákna, proxy) | Cloud scraping, paralelizace |
| Export dat | Na míru (CSV, Excel, DB) | Jedním kliknutím do Excelu, Sheets |
| Cena | Zdarma (váš čas + proxy) | Freemium, platba za škálování |
| Nejlepší pro | Vývojáře, vlastní potřeby | Business uživatele, rychlé výsledky |
Pokud jste vývojář, který rád ladí detaily a potřebuje něco opravdu na míru, Python je váš kamarád. Pokud chcete rychlost, jednoduchost a nulový kód, Thunderbit je správná cesta.
Kdy zvolit Python, no-code nebo AI web scraper pro data z Amazonu
Zvolte Python, pokud:
- Potřebujete vlastní logiku nebo chcete scraping integrovat do backend systémů
- Scrapujete ve velkém měřítku (desítky tisíc produktů)
- Chcete se naučit, jak scraping funguje pod kapotou
Zvolte Thunderbit (no-code, AI web scraper), pokud:
- Chcete data rychle a bez programování
- Jste business uživatel, analytik nebo marketér
- Potřebujete, aby si váš tým mohl data získávat sám
- Chcete se vyhnout starostem s proxy, anti-bot opatřeními a údržbou
Použijte obojí, pokud:
- Chcete rychle prototypovat s Thunderbitem a pak postavit vlastní Python řešení pro produkci
- Chcete Thunderbit používat pro sběr dat a Python pro čištění a analýzu dat
Pro většinu business uživatelů pokryje Thunderbit 90 % potřeb scrapování Amazonu za zlomek času. Pro zbylých 10 % — tedy super na míru, ve velkém nebo hluboce integrovaných věcí — je stále králem Python.
Závěr a klíčové poznatky
Scrapování produktových dat z Amazonu je superschopnost pro jakýkoli tým v prodeji, e-commerce nebo operations. Ať už sledujete ceny, analyzujete konkurenci, nebo jen chcete ušetřit týmu nekonečné kopírování a vkládání, existuje pro vás řešení.
- Python scraping vám dává plnou kontrolu, ale přináší křivku učení a průběžnou údržbu.
- No-code web scrapery jako Thunderbit zpřístupňují extrakci dat z Amazonu každému — bez kódu, bez stresu, jen výsledky.
- Nejlepší přístup? Použijte nástroj, který odpovídá vašim dovednostem, časovému plánu a obchodním cílům.
Pokud vás to láká, vyzkoušejte Thunderbit — start je zdarma a budete překvapeni, jak rychle získáte data, která potřebujete. A pokud jste vývojář, nebojte se kombinovat přístupy: někdy je nejrychlejší cesta k hotovému řešení nechat AI udělat ty nudné části za vás.
Časté dotazy
1. Proč by firma chtěla scrapovat produktová data z Amazonu?
Scraping Amazonu firmám umožňuje sledovat ceny, analyzovat konkurenci, sbírat recenze pro produktový výzkum, předpovídat poptávku a generovat obchodní leady. S více než 600 miliony produktů a téměř 2 miliony prodejců na Amazonu jde o bohatý zdroj konkurenční inteligence.
2. Jaké jsou hlavní rozdíly mezi použitím Pythonu a no-code nástrojů, jako je Thunderbit, pro scrapování Amazonu?
Python scrapery nabízejí maximální flexibilitu, ale vyžadují programátorské dovednosti, čas na nastavení a průběžnou údržbu. Thunderbit, no-code AI web scraper, umožňuje uživatelům okamžitě extrahovat data z Amazonu přes Chrome rozšíření — bez programování, s vestavěnou anti-bot ochranou a exportem do Excelu nebo Sheets.
3. Je legální scrapovat data z Amazonu?
Podmínky služby Amazonu obecně scraping zakazují a Amazon aktivně používá anti-bot opatření. Mnoho firem však stále scrapuje veřejně dostupná data a zároveň postupuje zodpovědně — například respektuje limity rychlosti a vyhýbá se nadměrnému počtu požadavků.
4. Jaká data mohu z Amazonu získat pomocí web scraping nástrojů?
Mezi běžná pole patří názvy produktů, ceny, hodnocení, počet recenzí, obrázky, specifikace produktu, dostupnost a dokonce i informace o prodejci. Thunderbit podporuje také scraping podstránek a stránkování, takže zachytí data napříč více produkty a stránkami.
5. Kdy mám zvolit Python scraping místo nástroje jako Thunderbit (nebo naopak)?
Použijte Python, pokud potřebujete plnou kontrolu, vlastní logiku nebo plánujete scraping integrovat do backend systémů. Použijte Thunderbit, pokud chcete rychlé výsledky bez programování, potřebujete snadné škálování nebo jste business uživatel, který hledá řešení s nízkou údržbou.
Chcete jít víc do hloubky? Podívejte se na tyto zdroje:
Šťastné scrapování — a ať jsou vaše tabulky vždy aktuální.